Leveraging LLMs For Turkish Skill Extraction
作者: Ezgi Arslan İltüzer, Özgür Anıl Özlü, Vahid Farajijobehdar, Gülşen Eryiğit
分类: cs.CL
发布日期: 2026-01-30
💡 一句话要点
利用大型语言模型进行土耳其语技能提取,填补低资源语言技能提取空白。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 土耳其语 技能提取 大型语言模型 少样本学习 低资源语言
📋 核心要点
- 土耳其语技能提取面临缺乏数据集和技能分类体系的挑战,现有方法难以有效处理其形态复杂性。
- 利用大型语言模型,结合动态少样本提示、嵌入检索和LLM重排序,构建端到端技能提取流程。
- 实验表明,该方法在土耳其语技能提取任务上取得了显著成果,端到端性能达到0.56,优于传统方法。
📝 摘要(中文)
技能提取是现代招聘系统的关键组成部分,能够实现高效的职位匹配、个性化推荐和劳动力市场分析。尽管土耳其在全球劳动力中扮演着重要角色,但土耳其语作为一种形态复杂的语言,缺乏技能分类体系和专门的技能提取数据集,导致土耳其语技能提取方面的研究不足。本文旨在回答三个研究问题:1) 鉴于土耳其语的低资源特性,如何有效地进行技能提取?2) 最有前景的模型是什么?3) 不同的大型语言模型(LLM)和提示策略(即,动态与静态的少样本示例、不同的上下文信息以及鼓励因果推理)对技能提取有何影响?本文介绍了第一个土耳其语技能提取数据集,并使用LLM对自动技能提取进行了性能评估。手动标注的数据集包含来自不同职业领域的327个职位发布的4,819个带标签的技能跨度。在端到端流程中使用时,LLM优于监督序列标注,能够更有效地将提取的跨度与ESCO分类体系中的标准化技能对齐。最佳配置是使用Claude Sonnet 3.7,采用动态少样本提示进行技能识别,基于嵌入的检索以及基于LLM的重排序进行技能链接,实现了0.56的端到端性能,使土耳其语的研究结果与其他语言的类似研究处于同一水平。我们的研究结果表明,LLM可以提高低资源环境下的技能提取性能,我们希望我们的工作能够加速对代表性不足的语言的技能提取研究。
🔬 方法详解
问题定义:论文旨在解决土耳其语技能提取任务中,由于缺乏数据集和技能分类体系,以及土耳其语本身形态复杂性带来的挑战。现有方法,如监督序列标注,难以有效提取和标准化土耳其语的技能信息。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语言理解和生成能力,结合合适的提示策略和检索机制,构建一个端到端的技能提取流程。通过少样本学习和动态提示,使LLM能够适应土耳其语的特点,并有效地提取和链接技能。
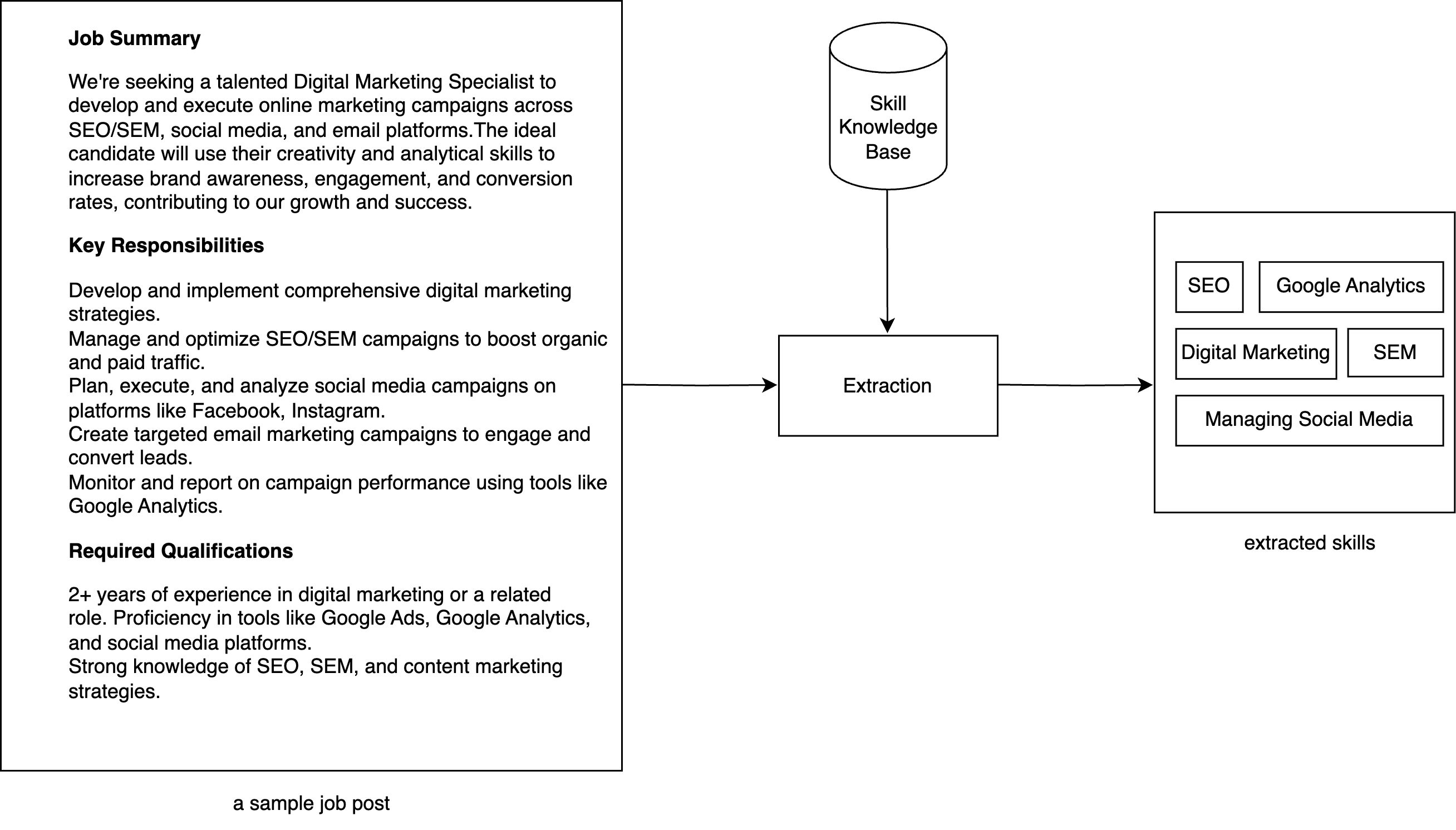
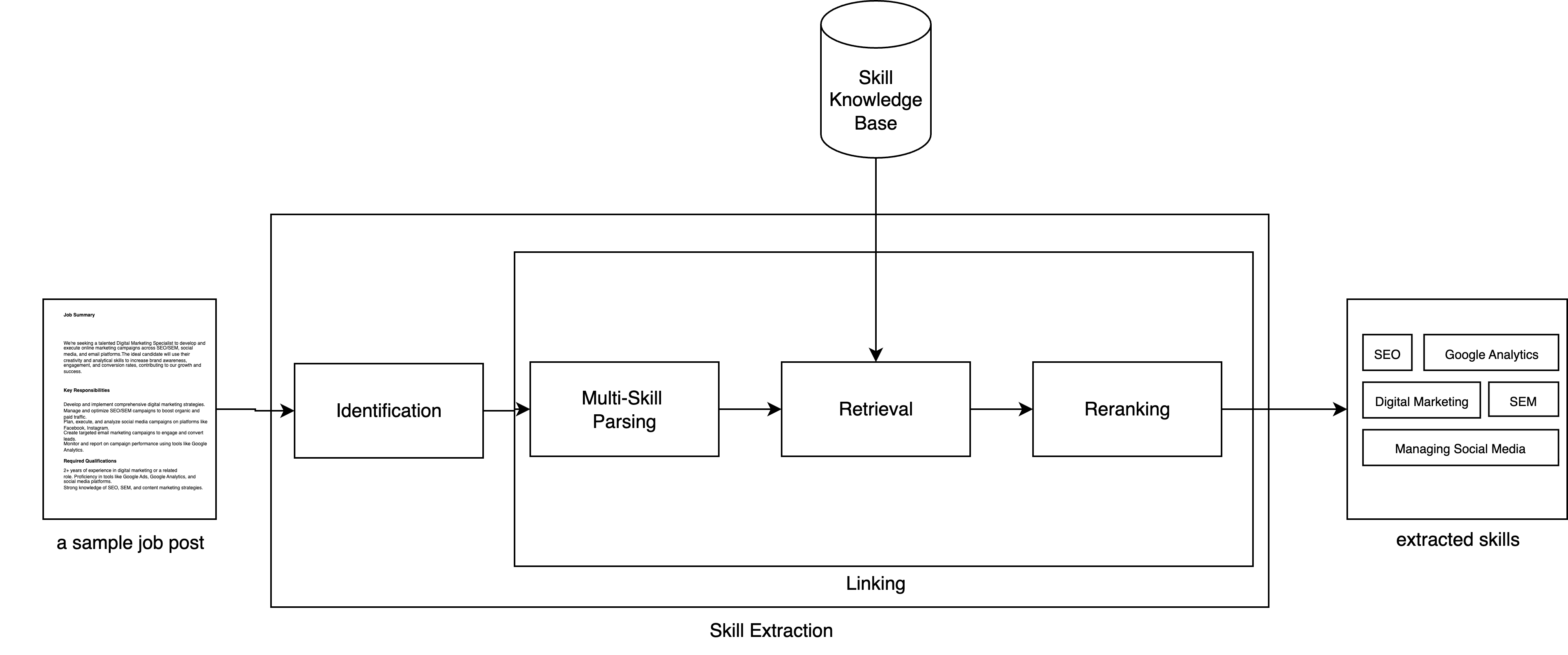
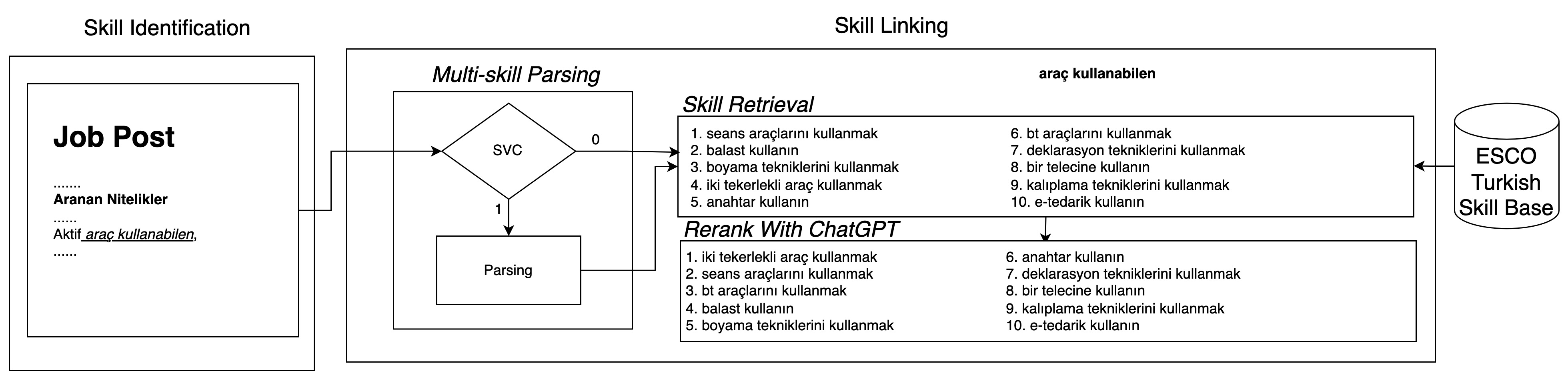
技术框架:整体框架包含三个主要阶段:1) 技能识别:使用LLM和动态少样本提示,从职位描述文本中识别潜在的技能跨度。2) 技能链接:使用基于嵌入的检索方法,将识别出的技能跨度与ESCO技能分类体系中的标准化技能进行匹配。3) 技能重排序:使用LLM对检索到的技能进行重排序,选择最相关的技能。
关键创新:最重要的技术创新点在于结合了动态少样本提示和LLM重排序的端到端技能提取流程。动态少样本提示能够根据不同的职位描述,选择最相关的示例,提高LLM的技能识别准确率。LLM重排序能够利用LLM的上下文理解能力,选择最符合职位需求的技能。
关键设计:论文使用了Claude Sonnet 3.7作为LLM,并设计了动态少样本提示策略,根据职位描述的上下文信息,选择最相关的少样本示例。在技能链接阶段,使用了基于嵌入的检索方法,计算技能跨度与ESCO技能之间的相似度。在技能重排序阶段,使用了LLM对检索到的技能进行排序,选择最相关的技能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Claude Sonnet 3.7,采用动态少样本提示进行技能识别,嵌入检索和LLM重排序进行技能链接,实现了0.56的端到端性能。该结果优于传统的监督序列标注方法,并将土耳其语技能提取的研究水平提升到与其他语言的类似研究相当的水平。
🎯 应用场景
该研究成果可应用于土耳其语招聘系统,实现职位与求职者技能的精准匹配,提升招聘效率。同时,该方法也可推广至其他低资源语言的技能提取任务,促进全球劳动力市场的分析和优化,为相关领域的学术研究和产业应用提供参考。
📄 摘要(原文)
Skill extraction is a critical component of modern recruitment systems, enabling efficient job matching, personalized recommendations, and labor market analysis. Despite Türkiye's significant role in the global workforce, Turkish, a morphologically complex language, lacks both a skill taxonomy and a dedicated skill extraction dataset, resulting in underexplored research in skill extraction for Turkish. This article seeks the answers to three research questions: 1) How can skill extraction be effectively performed for this language, in light of its low resource nature? 2)~What is the most promising model? 3) What is the impact of different Large Language Models (LLMs) and prompting strategies on skill extraction (i.e., dynamic vs. static few-shot samples, varying context information, and encouraging causal reasoning)? The article introduces the first Turkish skill extraction dataset and performance evaluations of automated skill extraction using LLMs. The manually annotated dataset contains 4,819 labeled skill spans from 327 job postings across different occupation areas. The use of LLM outperforms supervised sequence labeling when used in an end-to-end pipeline, aligning extracted spans with standardized skills in the ESCO taxonomy more effectively. The best-performing configuration, utilizing Claude Sonnet 3.7 with dynamic few-shot prompting for skill identification, embedding-based retrieval, and LLM-based reranking for skill linking, achieves an end-to-end performance of 0.56, positioning Turkish alongside similar studies in other languages, which are few in the literature. Our findings suggest that LLMs can improve skill extraction performance in low-resource settings, and we hope that our work will accelerate similar research on skill extraction for underrepresented languages.