Rethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry
作者: Zhuochun Li, Yong Zhang, Ming Li, Yuelyu Ji, Yiming Zeng, Ning Cheng, Yun Zhu, Yanmeng Wang, Shaojun Wang, Jing Xiao, Daqing He
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-30
💡 一句话要点
提出基于表征的INSPECTOR框架,利用小模型实现高效、可靠、可解释的LLM评判。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型评估 表征学习 小模型 提示工程 语义容量 推理任务 可解释性
📋 核心要点
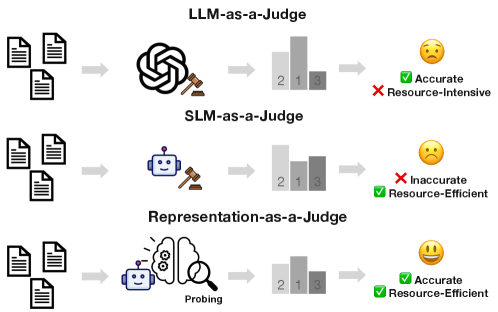
- 现有“LLM即评判”方法成本高、不透明,且对提示敏感,难以规模化应用。
- 论文提出“表征即评判”范式,利用小模型内部表征进行评估,降低对生成能力的需求。
- INSPECTOR框架在推理任务上超越了基于提示的小模型,性能接近大型LLM评判。
📝 摘要(中文)
大型语言模型(LLMs)通常被用作无参考评估器,通过提示工程实现,但这种“LLM即评判”的模式成本高昂、不透明且对提示设计敏感。本文研究了是否可以通过利用内部表征而非表面生成,使较小的模型能够作为高效的评估器。我们发现了一个一致的经验模式:小型语言模型虽然生成能力较弱,但在其隐藏状态中编码了丰富的评估信号。这促使我们提出了语义容量不对称假设:评估所需的语义容量远小于生成,并且可以基于中间表征,这意味着评估不一定需要依赖大规模生成模型,而是可以利用来自较小模型的潜在特征。我们的发现促使我们从“LLM即评判”转变为“表征即评判”,这是一种无需解码的评估策略,它探测内部模型结构,而不是依赖于提示输出。我们通过INSPECTOR实例化了这种范式,INSPECTOR是一个基于探测的框架,可以从小模型表征中预测方面级别的评估分数。在推理基准(GSM8K、MATH、GPQA)上的实验表明,INSPECTOR显著优于基于提示的小型LLM,并接近完整的LLM评判,同时为可扩展评估提供了一种更高效、可靠和可解释的替代方案。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)作为评判者进行评估时,存在计算成本高昂、缺乏透明度以及对提示工程过度依赖的问题。这些问题限制了LLM评判在实际应用中的可扩展性和可靠性。因此,需要一种更高效、更经济且更可解释的评估方法。
核心思路:论文的核心思路是利用小型语言模型(Small LMs)的内部表征作为评估信号,而不是依赖于它们的生成能力。作者认为,评估任务所需的语义容量远小于生成任务,因此可以通过分析小模型在处理输入时产生的隐藏状态来提取有用的评估信息。这种“表征即评判”的范式旨在绕过对大型生成模型的依赖,从而降低计算成本并提高评估效率。
技术框架:论文提出的INSPECTOR框架包含以下主要步骤:1)使用小型语言模型处理待评估的文本输入,并提取其隐藏状态表征;2)使用探测技术(Probing)训练一个分类器或回归器,将隐藏状态表征映射到相应的评估分数(例如,准确性、相关性等);3)使用训练好的探测器对新的文本输入进行评估,直接从其隐藏状态预测评估分数,而无需进行文本生成。
关键创新:最重要的技术创新点在于提出了“语义容量不对称假设”和“表征即评判”的范式。与传统的“LLM即评判”方法相比,INSPECTOR不再依赖于大型模型的生成能力,而是直接利用小型模型的内部表征进行评估。这种方法不仅降低了计算成本,还提高了评估的效率和可解释性。
关键设计:INSPECTOR的关键设计包括:1)选择合适的预训练小型语言模型作为基础模型;2)确定需要评估的方面(例如,准确性、相关性、流畅性等);3)设计合适的探测器结构(例如,线性分类器、多层感知机等);4)选择合适的训练数据和损失函数,以训练探测器将隐藏状态表征映射到准确的评估分数。论文中使用了不同层的隐藏状态,并探索了不同的探测方法,以找到最佳的评估性能。
🖼️ 关键图片

📊 实验亮点
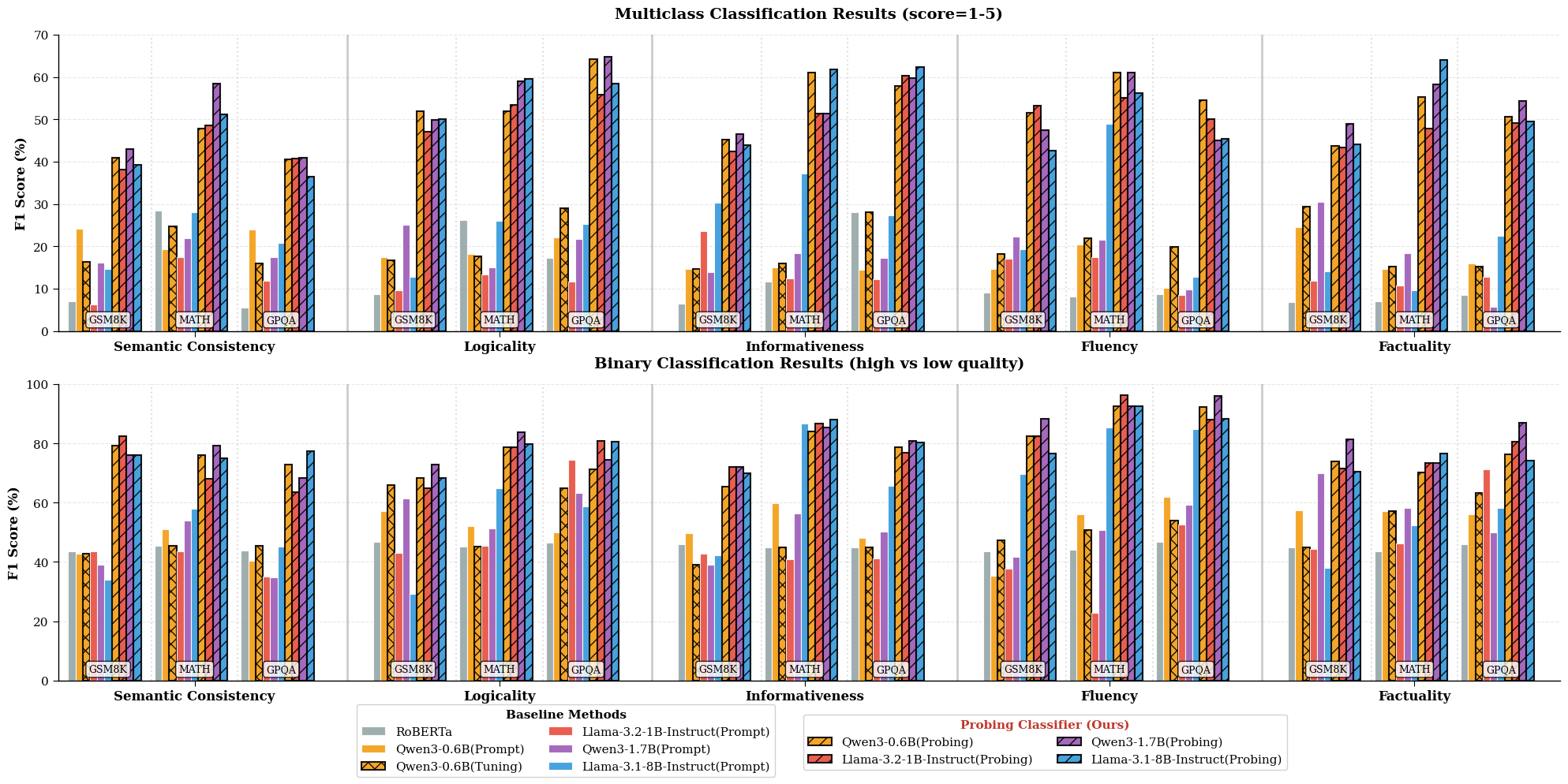
实验结果表明,INSPECTOR在GSM8K、MATH和GPQA等推理基准测试中,显著优于基于提示的小型LLM,并且性能接近大型LLM评判。例如,INSPECTOR在某些任务上甚至可以达到与GPT-3.5相当的评估性能,同时计算成本大大降低。这证明了“表征即评判”范式的有效性和潜力。
🎯 应用场景
该研究成果可应用于自动评估各种文本生成任务,例如机器翻译、文本摘要、对话生成等。它能够降低评估成本,提高评估效率,并提供更可解释的评估结果。此外,该方法还可以用于开发更高效的自动评分系统,辅助教育和科研领域。
📄 摘要(原文)
Large language models (LLMs) are widely used as reference-free evaluators via prompting, but this "LLM-as-a-Judge" paradigm is costly, opaque, and sensitive to prompt design. In this work, we investigate whether smaller models can serve as efficient evaluators by leveraging internal representations instead of surface generation. We uncover a consistent empirical pattern: small LMs, despite with weak generative ability, encode rich evaluative signals in their hidden states. This motivates us to propose the Semantic Capacity Asymmetry Hypothesis: evaluation requires significantly less semantic capacity than generation and can be grounded in intermediate representations, suggesting that evaluation does not necessarily need to rely on large-scale generative models but can instead leverage latent features from smaller ones. Our findings motivate a paradigm shift from LLM-as-a-Judge to Representation-as-a-Judge, a decoding-free evaluation strategy that probes internal model structure rather than relying on prompted output. We instantiate this paradigm through INSPECTOR, a probing-based framework that predicts aspect-level evaluation scores from small model representations. Experiments on reasoning benchmarks (GSM8K, MATH, GPQA) show that INSPECTOR substantially outperforms prompting-based small LMs and closely approximates full LLM judges, while offering a more efficient, reliable, and interpretable alternative for scalable evaluation.