Are LLM Evaluators Really Narcissists? Sanity Checking Self-Preference Evaluations
作者: Dani Roytburg, Matthew Bozoukov, Matthew Nguyen, Mackenzie Puig-Hall, Narmeen Oozeer
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-30
💡 一句话要点
提出评估器质量基线,消除LLM自偏好评估中的噪声,提升评估可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自偏好 评估器偏差 自动化评估 评估器质量基线
📋 核心要点
- 现有研究表明LLM评估器存在自偏好,但难以区分自恋偏差与实验误差,影响评估的准确性。
- 论文提出评估器质量基线,通过对比评估器对自己错误答案和他人错误答案的偏好,消除噪声数据。
- 实验表明,使用该基线后,只有51%的初始发现具有统计显著性,有效提升了自偏好研究的可靠性。
📝 摘要(中文)
最近的研究表明,大型语言模型(LLM)在充当评估者时,倾向于偏袒自己的输出,这损害了自动化后训练和评估工作流程的完整性。然而,很难区分哪些评估偏差是由自恋引起的,哪些是由一般的实验混淆因素引起的,这扭曲了对自偏好偏差的测量。本文发现了一个核心的方法学混淆,它可以减少89.6%的测量误差。具体来说,当评估者回答自己错误完成的查询时,可能会给出偏袒自己的判断;无论其中一个回答是否是他们自己的,情况都是如此。为了将自偏好信号与难题上的噪声输出分离,我们引入了评估器质量基线,该基线将评估者错误地投票给自己答案的概率与投票给另一个模型的不正确答案的概率进行比较。在37,448个查询上评估这个简单的基线后,只有51%的初始发现保留了统计显著性。最后,我们转向描述LLM评估者对“简单”与“困难”评估投票的熵。我们的校正基线通过消除潜在解决方案中的噪声数据,为未来关于自偏好的研究提供了可能。更广泛地说,这项工作有助于不断增长的关于编目和隔离评估者偏差效应的研究。
🔬 方法详解
问题定义:现有研究发现LLM在作为评估者时,会倾向于选择自己的答案,即存在“自偏好”现象。这种自偏好会影响自动化评估流程的公正性和准确性。然而,现有的研究难以区分这种自偏好是源于LLM的“自恋”心理,还是由于实验设计中的其他混淆因素导致的。因此,如何准确测量和消除LLM评估器中的自偏好偏差是一个重要的挑战。
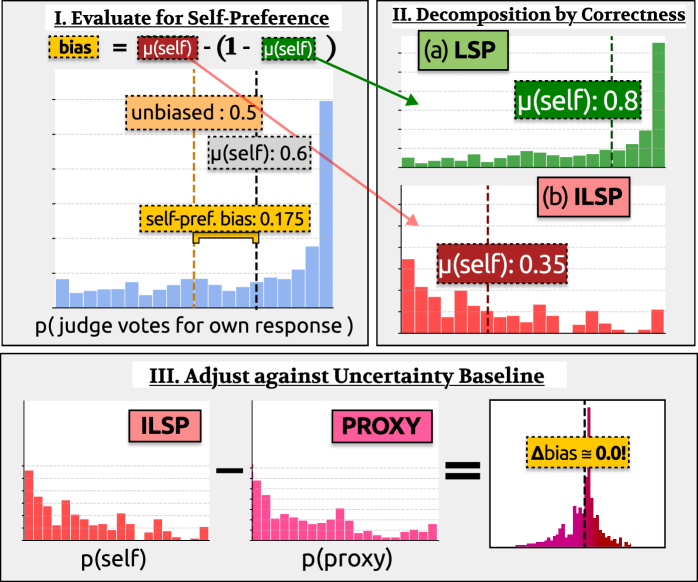
核心思路:论文的核心思路是,LLM评估器在难题上容易出错,如果评估器对自己错误回答的偏好仅仅是因为它认为自己的回答是正确的(即使是错误的),那么这种偏好就不能被视为真正的“自偏好”。因此,论文提出了一种“评估器质量基线”,用于区分真正的自偏好和由于评估器自身能力不足导致的偏好。
技术框架:论文提出的方法主要包含以下几个步骤: 1. 收集LLM评估器对一系列问题的回答,包括评估器自己的回答和其他LLM的回答。 2. 对于每个问题,判断评估器自己的回答是否正确。 3. 计算评估器错误地投票给自己答案的概率,以及错误地投票给其他LLM的错误答案的概率。 4. 使用这两个概率的比值作为评估器质量基线,用于校正自偏好偏差。
关键创新:论文的关键创新在于提出了“评估器质量基线”这一概念,并将其用于消除LLM自偏好评估中的噪声。与以往的研究不同,该方法不仅关注评估器是否偏好自己的答案,还考虑了评估器自身能力对评估结果的影响。通过对比评估器对自己错误答案和他者错误答案的偏好,可以更准确地测量和消除自偏好偏差。
关键设计:论文的关键设计在于如何定义和计算评估器质量基线。具体来说,基线被定义为评估器错误地投票给自己答案的概率与错误地投票给其他LLM的错误答案的概率的比值。这个比值可以反映评估器在多大程度上是因为认为自己的答案正确而偏好自己的答案,而不是因为“自恋”心理。论文还详细描述了如何收集和处理数据,以确保基线的计算结果是可靠的。
🖼️ 关键图片
📊 实验亮点
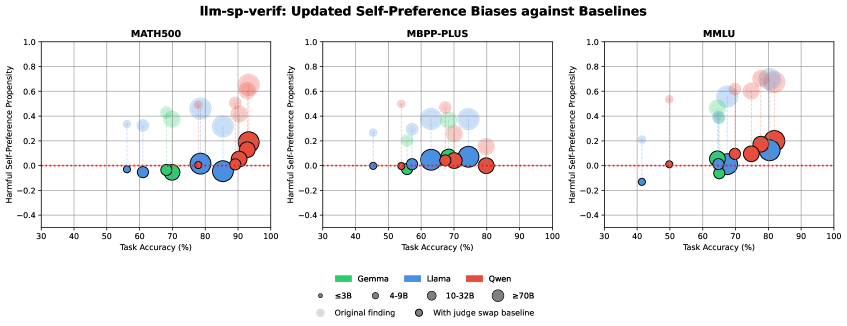
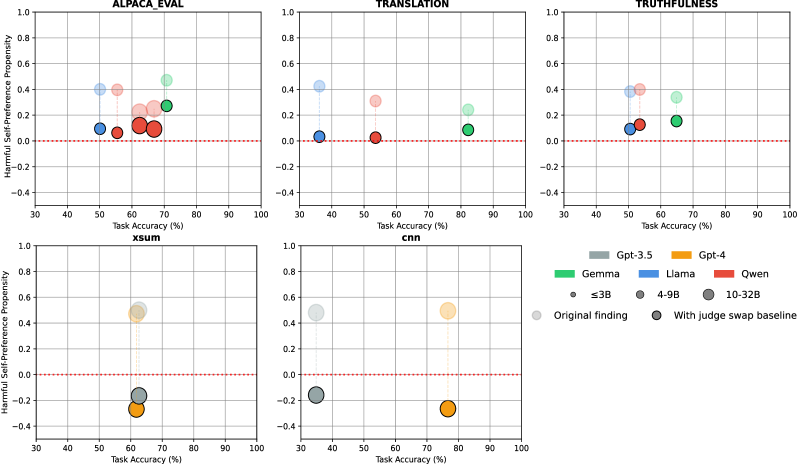
论文在37,448个查询上进行了实验,结果表明,使用评估器质量基线后,只有51%的初始发现保留了统计显著性。这表明,许多先前被认为是自偏好的现象,实际上可能是由于评估器自身能力不足导致的。该研究结果强调了在评估LLM时,需要考虑评估器自身能力的重要性。
🎯 应用场景
该研究成果可应用于改进LLM的自动化评估流程,提高评估结果的准确性和公正性。通过消除评估器中的自偏好偏差,可以更客观地评估不同LLM的性能,从而促进LLM技术的进步。此外,该方法还可以应用于其他类型的AI评估任务中,例如图像识别、语音识别等。
📄 摘要(原文)
Recent research has shown that large language models (LLM) favor own outputs when acting as judges, undermining the integrity of automated post-training and evaluation workflows. However, it is difficult to disentangle which evaluation biases are explained by narcissism versus general experimental confounds, distorting measurements of self-preference bias. We discover a core methodological confound which could reduce measurement error by 89.6%. Specifically, LLM evaluators may deliver self-preferring verdicts when the judge responds to queries which they completed incorrectly themselves; this would be true regardless of whether one of their responses is their own. To decouple self-preference signals from noisy outputs on hard problems, we introduce an Evaluator Quality Baseline, which compares the probability that a judge incorrectly votes for itself against the probability that it votes for an incorrect response from another model. Evaluating this simple baseline on 37,448 queries, only 51% of initial findings retain statistical significance. Finally, we turn towards characterizing the entropy of "easy" versus "hard" evaluation votes from LLM judges. Our corrective baseline enables future research on self-preference by eliminating noisy data from potential solutions. More widely, this work contributes to the growing body of work on cataloging and isolating judge-bias effects.