$ρ$-$\texttt{EOS}$: Training-free Bidirectional Variable-Length Control for Masked Diffusion LLMs
作者: Jingyi Yang, Yuxian Jiang, Jing Shao
分类: cs.CL
发布日期: 2026-01-30
备注: 11 pages,6 figures,6 tables
💡 一句话要点
提出$ρ$-$ exttt{EOS}$,实现Masked扩散LLM的免训练双向变长控制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 变长生成 免训练 序列结束符 隐式密度 双向控制
📋 核心要点
- Masked扩散LLM需要预定义固定长度,限制了灵活性,需要在质量和效率间权衡。
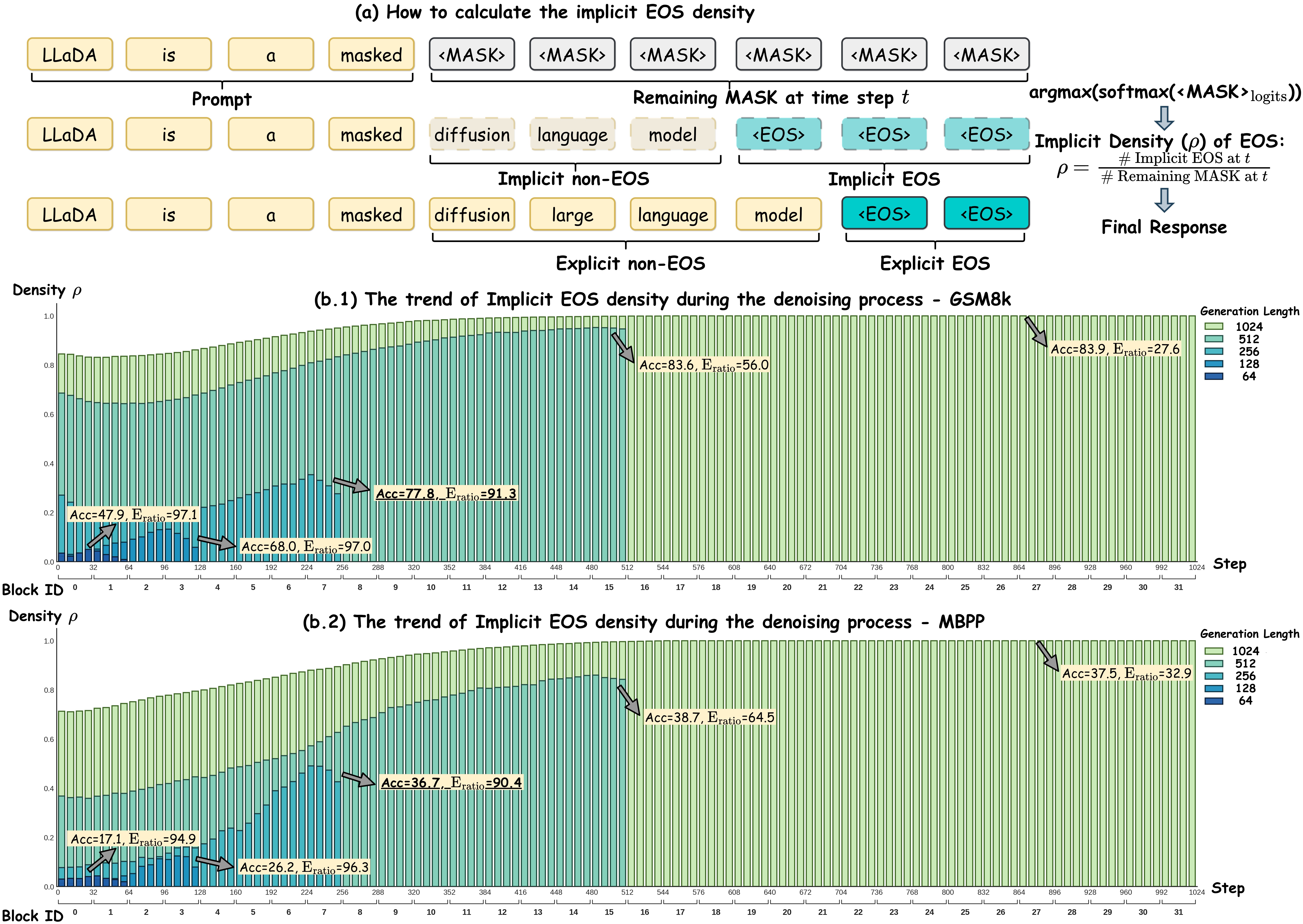
- 通过分析去噪过程,发现EOS token的隐式密度可作为生成充分性的可靠指标。
- 提出$ρ$-$ exttt{EOS}$策略,无需训练,单阶段实现Masked dLLM的双向变长生成。
📝 摘要(中文)
当前Masked扩散大语言模型(dLLMs)除了并行生成和全局上下文建模外,还存在一个根本限制:它们需要预定义的固定生成长度,缺乏灵活性,并且不可避免地需要在输出质量和计算效率之间进行权衡。为了解决这个问题,我们研究了去噪动态过程,发现序列结束($ exttt{EOS}$)token的隐式密度($ρ$)可以作为生成充分性的可靠信号。特别地,去噪过程中不断变化的隐式$ exttt{EOS}$密度揭示了当前Masked空间是过剩还是不足,从而指导生成长度的调整方向。基于此,我们提出$ extbf{$ρ$-$ exttt{EOS}$}$,一种免训练的单阶段策略,能够为Masked dLLMs实现双向变长生成。与之前的两阶段方法(需要单独的长度调整和迭代Mask插入阶段,同时仅支持单向扩展)不同,$ extbf{$ρ$-$ exttt{EOS}$}$通过连续估计隐式$ exttt{EOS}$密度,在统一的去噪过程中实现双向长度调整:过高的密度触发$ exttt{MASK}$ token收缩,而不足的密度则导致扩展。在数学和代码基准上的大量实验表明,$ extbf{$ρ$-$ exttt{EOS}$}$在实现可比性能的同时,显著提高了推理效率和token利用率。
🔬 方法详解
问题定义:Masked扩散LLM需要预先设定固定的生成长度,这导致了两个主要问题。一是缺乏灵活性,无法根据实际需求动态调整生成长度。二是需要在输出质量和计算效率之间进行权衡,过短的长度可能导致信息不完整,过长的长度则浪费计算资源。现有方法通常采用两阶段策略,但效率较低且仅支持单向扩展。
核心思路:论文的核心思路是利用序列结束符(EOS)的隐式密度来指导生成长度的调整。作者观察到,在去噪过程中,EOS token的密度能够反映当前生成内容的充分性。如果EOS密度过高,说明生成内容可能已经足够,可以减少生成长度;反之,如果EOS密度过低,则说明生成内容不足,需要增加生成长度。通过动态调整Masked空间的大小,实现变长生成。
技术框架:$ρ$-$ exttt{EOS}$方法是一个单阶段的去噪过程。在每一步去噪迭代中,模型首先预测当前Masked区域的内容。然后,计算EOS token的隐式密度。根据密度值,决定是收缩(减少Masked token)还是扩展(增加Masked token)Masked区域。这个过程持续进行,直到满足停止条件。整个过程在一个统一的去噪框架内完成,无需额外的长度调整阶段。
关键创新:该方法最关键的创新在于利用EOS token的隐式密度作为生成长度调整的信号。这种方法无需额外的训练,可以直接应用于现有的Masked扩散LLM。此外,$ρ$-$ exttt{EOS}$实现了双向的长度调整,可以根据需要动态地增加或减少生成长度,而传统方法通常只能单向扩展。
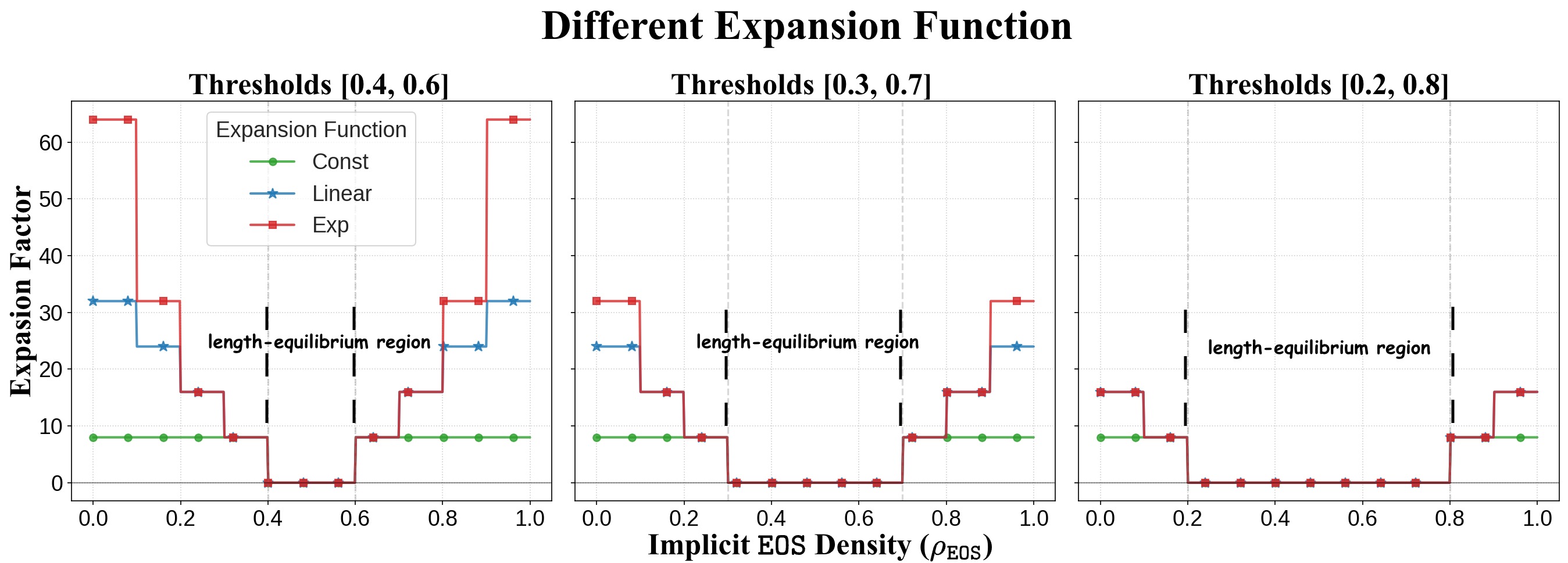
关键设计:$ρ$-$ exttt{EOS}$的关键设计在于EOS密度的计算方式和长度调整的策略。具体来说,EOS密度可以通过统计当前Masked区域中预测为EOS token的概率来估计。长度调整策略则需要设定一个阈值,当EOS密度高于阈值时,进行收缩;低于阈值时,进行扩展。阈值的选择会影响生成长度的精度和效率,需要在实际应用中进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,$ρ$-$ exttt{EOS}$方法在数学和代码生成任务上取得了与固定长度生成方法相当的性能,同时显著提高了推理效率和token利用率。具体来说,该方法能够在保证生成质量的前提下,减少生成所需的token数量,从而降低计算成本。
🎯 应用场景
该研究成果可广泛应用于需要灵活控制生成长度的自然语言生成任务中,例如自动摘要、机器翻译、代码生成等。通过动态调整生成长度,可以提高生成效率,减少计算资源消耗,并提升生成质量。该方法尤其适用于资源受限的场景,例如移动设备或边缘计算环境。
📄 摘要(原文)
Beyond parallel generation and global context modeling, current masked diffusion large language models (dLLMs) suffer from a fundamental limitation: they require a predefined, fixed generation length, which lacks flexibility and forces an inevitable trade-off between output quality and computational efficiency. To address this, we study the denoising dynamics and find that the implicit density ($ρ$) of end-of-sequence ($\texttt{EOS}$) tokens serves as a reliable signal of generation sufficiency. In particular, the evolving implicit $\texttt{EOS}$ density during denoising reveals whether the current masked space is excessive or insufficient, thereby guiding the adjustment direction for generation length. Building on this insight, we propose $\textbf{$ρ$-$\texttt{EOS}$}$, a training-free, single-stage strategy that enables bidirectional variable-length generation for masked dLLMs. Unlike prior two-stage approaches--which require separate length adjustment and iterative mask insertion phases while supporting only unidirectional expansion--$\textbf{$ρ$-$\texttt{EOS}$}$ achieves bidirectional length adjustment within a unified denoising process by continuously estimating the implicit $\texttt{EOS}$ density: excessively high density triggers $\texttt{MASK}$ token contraction, while insufficient density induces expansion. Extensive experiments on mathematics and code benchmarks demonstrate that $\textbf{$ρ$-$\texttt{EOS}$}$ achieves comparable performance while substantially improving inference efficiency and token utilization.