Hybrid Linear Attention Done Right: Efficient Distillation and Effective Architectures for Extremely Long Contexts
作者: Yingfa Chen, Zhen Leng Thai, Zihan Zhou, Zhu Zhang, Xingyu Shen, Shuo Wang, Chaojun Xiao, Xu Han, Zhiyuan Liu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-29
备注: 20 pages, 8 figures
💡 一句话要点
提出HALO和HypeNet,实现Transformer到混合模型的低成本高效蒸馏,提升长文本处理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 混合Transformer 知识蒸馏 长文本建模 RNN-Attention 位置编码 模型压缩 高效推理
📋 核心要点
- 现有混合Transformer模型预训练成本高昂,且在长文本处理上表现不佳,限制了其应用。
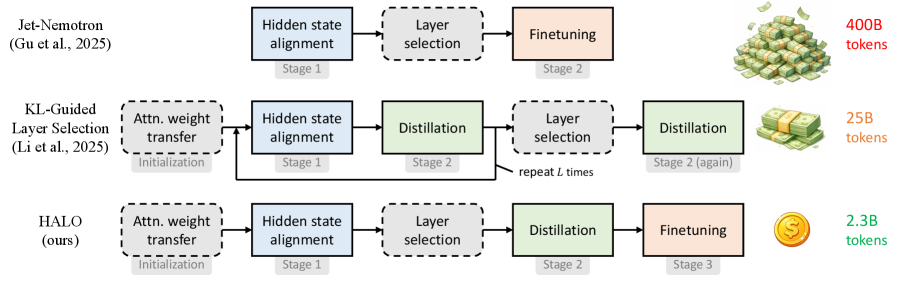
- 论文提出HALO流程,通过层优化将Transformer模型高效蒸馏为RNN-attention混合模型。
- 引入HypeNet架构,结合HyPE位置编码,提升长度泛化能力,并在长文本任务中实现高效推理。
📝 摘要(中文)
混合Transformer架构结合了softmax注意力模块和循环神经网络(RNN),在长文本建模中表现出理想的性能-吞吐量权衡。然而,从头开始进行大规模预训练的成本过高,阻碍了其应用和研究。最近的研究表明,预训练的softmax注意力模块可以通过参数迁移和知识蒸馏转换为RNN模块。但是,这些迁移方法需要大量的训练数据(超过100亿tokens),并且由此产生的混合模型也表现出较差的长文本性能,而这正是混合模型相对于基于Transformer的模型具有显著推理加速优势的场景。本文提出了HALO(Hybrid Attention via Layer Optimization),一个用于将Transformer模型蒸馏成RNN-attention混合模型的流程。然后,我们提出了一种混合架构HypeNet,它通过一种新颖的位置编码方案(名为HyPE)和各种架构修改实现了卓越的长度泛化能力。我们使用HALO将Qwen3系列转换为HypeNet,实现了与原始Transformer模型相当的性能,同时享受了卓越的长文本性能和效率。转换仅需23亿tokens,不到其预训练数据的0.01%。
🔬 方法详解
问题定义:现有混合Transformer模型,虽然在长文本处理上具有推理速度优势,但从头开始预训练成本过高,阻碍了其广泛应用。已有的蒸馏方法需要大量训练数据,且蒸馏后的模型在长文本上的性能仍然不佳。因此,需要一种低成本且能保证长文本性能的蒸馏方法。
核心思路:论文的核心思路是通过知识蒸馏,将预训练好的Transformer模型的知识迁移到混合模型(RNN-attention)中。关键在于设计一种高效的蒸馏流程(HALO)和一种能够更好处理长文本的混合模型架构(HypeNet),从而在保证性能的同时,显著降低训练成本。
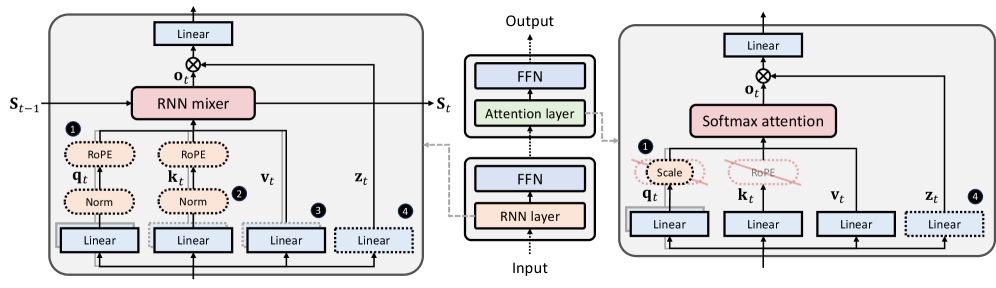
技术框架:整体框架包含两个主要部分:1) HALO蒸馏流程:用于将预训练的Transformer模型蒸馏成RNN-attention混合模型。2) HypeNet混合架构:一种结合了RNN和attention机制的新型网络结构,包含HyPE位置编码等创新设计。HALO流程利用少量数据对Transformer模型进行蒸馏,得到HypeNet模型。
关键创新:论文的关键创新点在于:1) HALO蒸馏流程:通过层优化,实现了Transformer到混合模型的高效蒸馏,显著降低了训练数据需求。2) HypeNet架构:通过HyPE位置编码和架构修改,提升了模型在长文本上的长度泛化能力和性能。HyPE位置编码允许模型更好地处理不同长度的输入序列。
关键设计:HALO流程的具体实现细节未知,但强调了层优化。HypeNet架构的关键设计包括:1) HyPE位置编码:一种新的位置编码方式,具体实现未知。2) 架构修改:对RNN和attention模块的连接方式进行了调整,具体细节未知。损失函数可能包含知识蒸馏常用的损失函数,如KL散度等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用HALO流程将Qwen3系列Transformer模型转换为HypeNet模型,仅需23亿tokens的训练数据,不到原始预训练数据的0.01%,即可达到与原始Transformer模型相当的性能,并在长文本处理上表现出更优的性能和效率。这证明了该方法在降低训练成本和提升长文本处理能力方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的场景,例如:长文档摘要、机器翻译、代码生成、对话系统等。通过将大型Transformer模型蒸馏成更高效的混合模型,可以在资源受限的环境下部署高性能的自然语言处理应用,并降低计算成本和能源消耗。未来,该方法有望推广到其他模态,例如长视频理解等。
📄 摘要(原文)
Hybrid Transformer architectures, which combine softmax attention blocks and recurrent neural networks (RNNs), have shown a desirable performance-throughput tradeoff for long-context modeling, but their adoption and studies are hindered by the prohibitive cost of large-scale pre-training from scratch. Some recent studies have shown that pre-trained softmax attention blocks can be converted into RNN blocks through parameter transfer and knowledge distillation. However, these transfer methods require substantial amounts of training data (more than 10B tokens), and the resulting hybrid models also exhibit poor long-context performance, which is the scenario where hybrid models enjoy significant inference speedups over Transformer-based models. In this paper, we present HALO (Hybrid Attention via Layer Optimization), a pipeline for distilling Transformer models into RNN-attention hybrid models. We then present HypeNet, a hybrid architecture with superior length generalization enabled by a novel position encoding scheme (named HyPE) and various architectural modifications. We convert the Qwen3 series into HypeNet using HALO, achieving performance comparable to the original Transformer models while enjoying superior long-context performance and efficiency. The conversion requires just 2.3B tokens, less than 0.01% of their pre-training data