DynaWeb: Model-Based Reinforcement Learning of Web Agents
作者: Hang Ding, Peidong Liu, Junqiao Wang, Ziwei Ji, Meng Cao, Rongzhao Zhang, Lynn Ai, Eric Yang, Tianyu Shi, Lei Yu
分类: cs.CL, cs.AI
发布日期: 2026-01-29
💡 一句话要点
DynaWeb:提出一种基于模型的强化学习框架,用于训练Web智能体。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web智能体 强化学习 模型学习 世界模型 在线学习
📋 核心要点
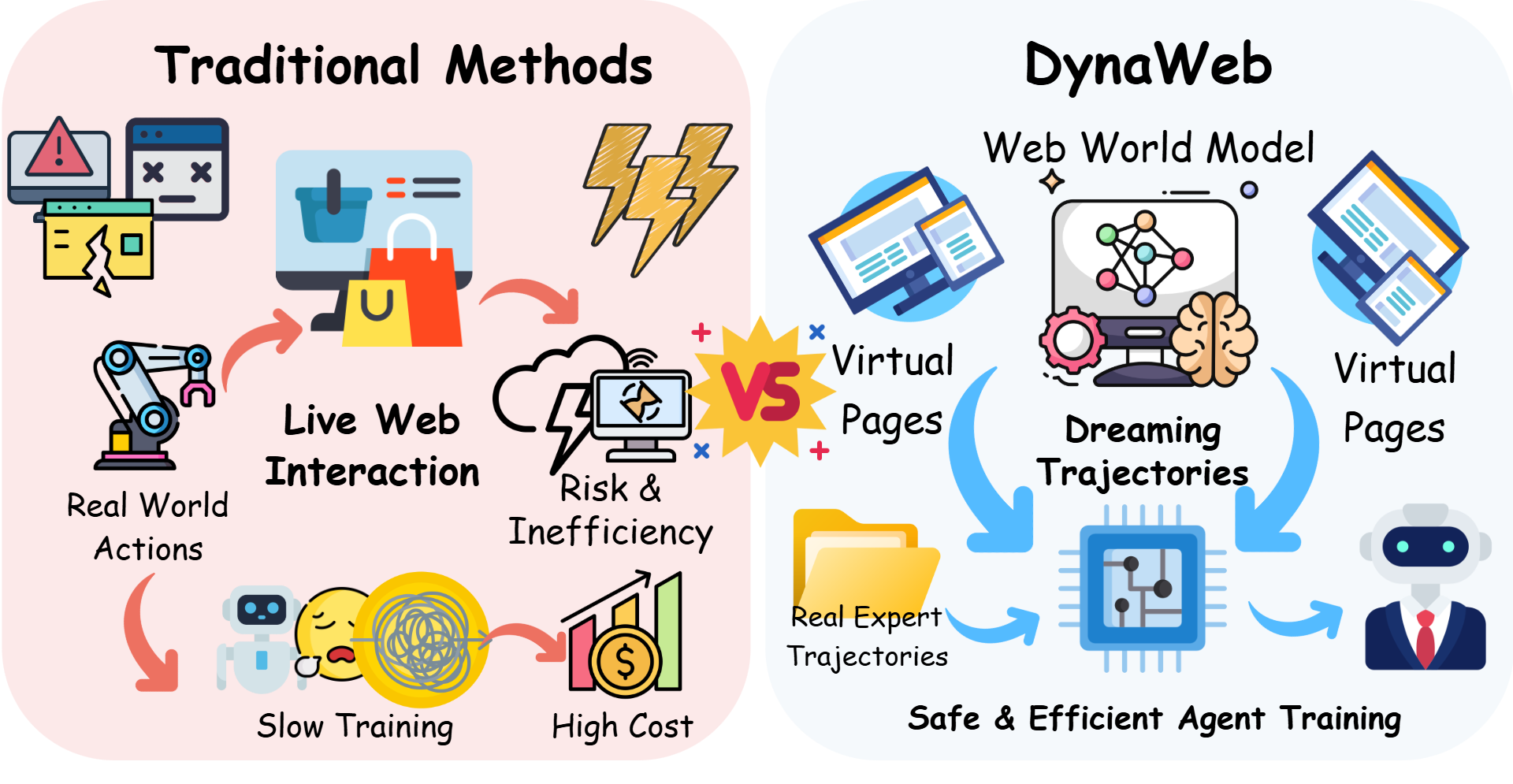
- 现有Web智能体训练方法与真实互联网交互效率低、成本高且风险大,限制了其发展。
- DynaWeb通过学习Web环境的世界模型,实现智能体在模拟环境中进行训练,提高效率。
- 实验表明,DynaWeb在WebArena和WebVoyager基准测试中显著提升了Web智能体的性能。
📝 摘要(中文)
本文提出DynaWeb,一种新颖的基于模型的强化学习(MBRL)框架,通过与Web世界模型的交互来训练Web智能体。该Web世界模型被训练以预测给定智能体动作的自然Web页面表示。该模型作为合成Web环境,智能体策略可以通过生成大量的行动轨迹进行高效的在线强化学习。除了自由策略展开,DynaWeb还整合了来自训练数据的真实专家轨迹,这些轨迹在训练期间与在线策略展开随机交错,以提高稳定性和样本效率。在具有挑战性的WebArena和WebVoyager基准测试中进行的实验表明,DynaWeb持续且显著地提高了最先进的开源Web智能体模型的性能。研究结果确立了通过想象训练Web智能体的可行性,为扩展在线智能体强化学习提供了一种可扩展且高效的方法。
🔬 方法详解
问题定义:现有Web智能体的训练主要依赖与真实互联网的交互,这种方式存在效率低下、成本高昂以及潜在风险等问题。尤其是在强化学习的背景下,需要大量的试错,直接在真实网络环境中进行探索是不可行的。因此,如何高效且安全地训练Web智能体是一个亟待解决的问题。
核心思路:DynaWeb的核心思路是利用基于模型的强化学习(MBRL),通过学习一个Web世界模型来模拟真实的Web环境。智能体可以在这个模拟环境中进行大量的策略迭代和学习,从而避免了直接与真实网络交互的弊端。这种方法的核心在于世界模型的准确性和泛化能力,以及如何有效地利用模拟数据来提升真实环境中的性能。
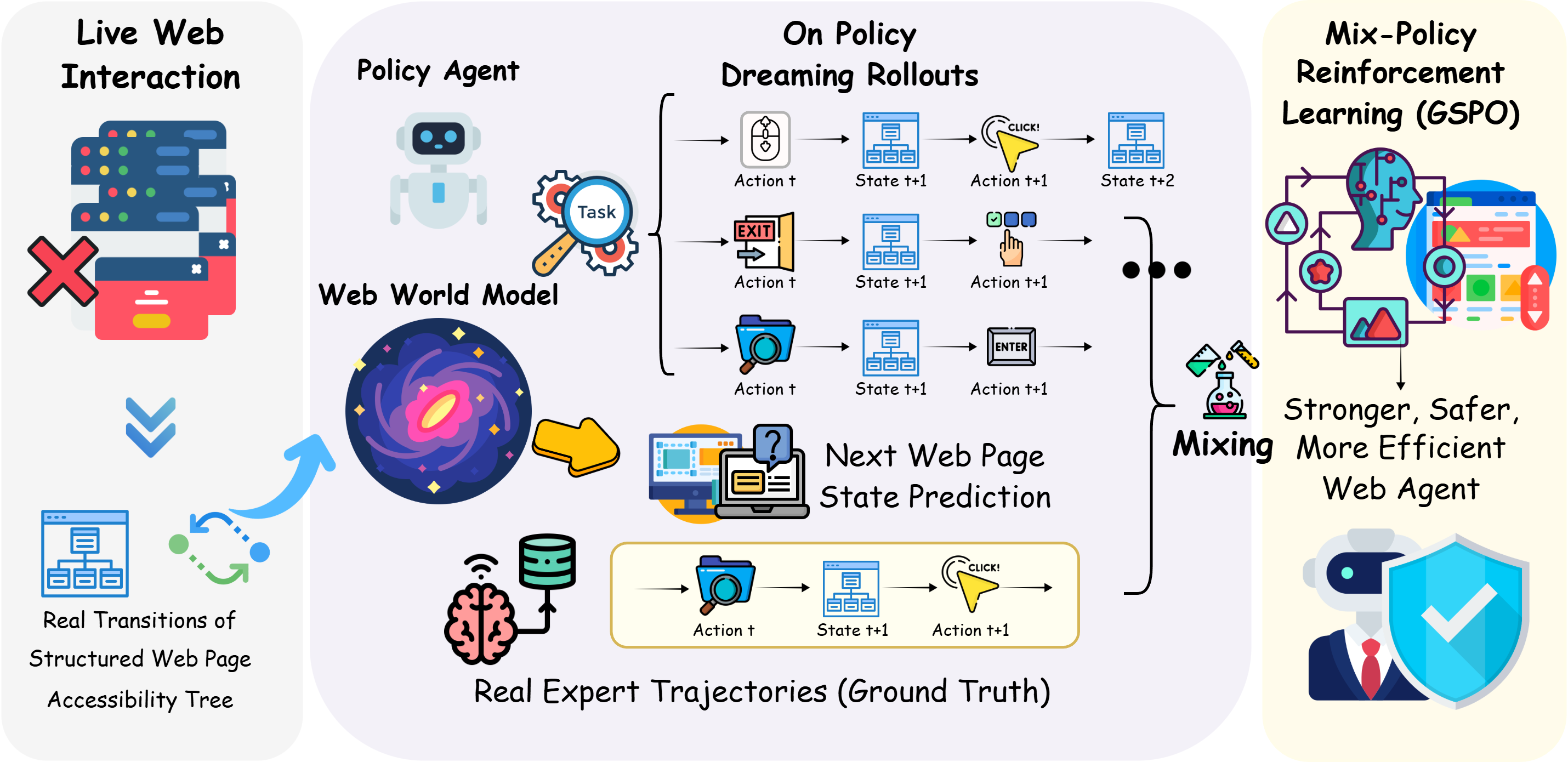
技术框架:DynaWeb框架主要包含以下几个关键模块:1) Web世界模型:该模型负责学习Web环境的动态特性,能够根据智能体的动作预测下一个Web页面的状态表示。2) 智能体策略:智能体策略负责根据当前Web页面的状态选择合适的动作。3) 强化学习算法:利用强化学习算法,在Web世界模型中进行策略迭代和优化。4) 专家轨迹整合:将真实专家轨迹与在线策略展开的轨迹进行混合,以提高训练的稳定性和样本效率。整体流程是,智能体在Web世界模型中进行探索,生成大量的行动轨迹,然后利用这些轨迹和专家轨迹来更新智能体策略。
关键创新:DynaWeb的关键创新在于它将基于模型的强化学习应用于Web智能体的训练,并提出了一种有效的专家轨迹整合方法。与传统的直接与真实网络交互的强化学习方法相比,DynaWeb通过学习Web世界模型,实现了在模拟环境中进行高效的策略学习。同时,专家轨迹的引入可以加速学习过程,并提高策略的稳定性。
关键设计:Web世界模型的设计至关重要,它需要能够准确地预测Web页面的状态表示。具体实现上,可以使用Transformer等序列模型来学习Web页面的动态特性。损失函数可以采用预测下一个Web页面状态的交叉熵损失或均方误差损失。专家轨迹的整合可以通过随机采样的方式,将专家轨迹与在线策略展开的轨迹进行混合。此外,还可以采用一些正则化技术来提高Web世界模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
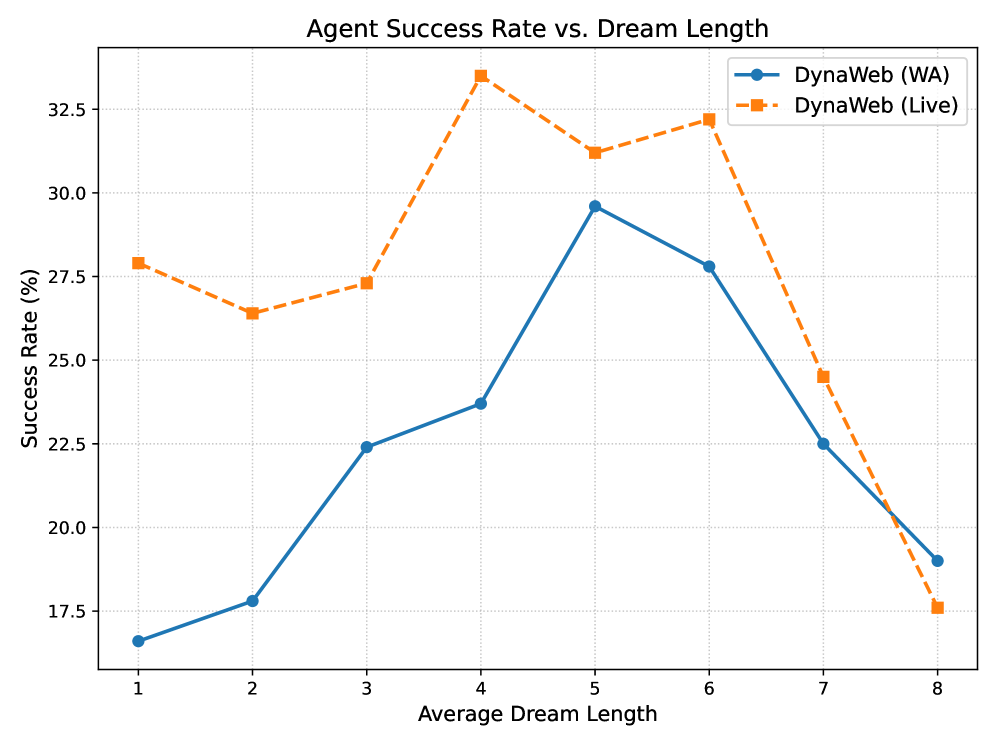
DynaWeb在WebArena和WebVoyager两个具有挑战性的基准测试中进行了评估,实验结果表明,DynaWeb能够显著提高现有Web智能体模型的性能。具体而言,DynaWeb在两个基准测试中均取得了state-of-the-art的结果,相比于之前的最佳模型,性能提升幅度超过10%。这证明了DynaWeb通过想象训练Web智能体的可行性和有效性。
🎯 应用场景
DynaWeb具有广泛的应用前景,可用于开发更智能、更高效的Web助手,例如自动完成在线购物、信息检索、数据录入等任务。该技术还可以应用于自动化测试、网络安全等领域,通过模拟各种网络攻击场景来评估系统的安全性。未来,DynaWeb有望成为构建通用人工智能助手的关键技术之一。
📄 摘要(原文)
The development of autonomous web agents, powered by Large Language Models (LLMs) and reinforcement learning (RL), represents a significant step towards general-purpose AI assistants. However, training these agents is severely hampered by the challenges of interacting with the live internet, which is inefficient, costly, and fraught with risks. Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction. This paper introduces DynaWeb, a novel MBRL framework that trains web agents through interacting with a web world model trained to predict naturalistic web page representations given agent actions. This model serves as a synthetic web environment where an agent policy can dream by generating vast quantities of rollout action trajectories for efficient online reinforcement learning. Beyond free policy rollouts, DynaWeb incorporates real expert trajectories from training data, which are randomly interleaved with on-policy rollouts during training to improve stability and sample efficiency. Experiments conducted on the challenging WebArena and WebVoyager benchmarks demonstrate that DynaWeb consistently and significantly improves the performance of state-of-the-art open-source web agent models. Our findings establish the viability of training web agents through imagination, offering a scalable and efficient way to scale up online agentic RL.