FineInstructions: Scaling Synthetic Instructions to Pre-Training Scale
作者: Ajay Patel, Colin Raffel, Chris Callison-Burch
分类: cs.CL, cs.LG
发布日期: 2026-01-29
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
FineInstructions:通过扩展合成指令数据到预训练规模,提升LLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令调优 合成数据 预训练 自然语言处理
📋 核心要点
- 现有LLM依赖大量非结构化文本的自监督预训练,但缺乏与用户指令直接相关的监督数据。
- FineInstructions通过将互联网规模的预训练文档转化为大规模合成指令和答案对,弥补了这一差距。
- 实验表明,使用FineInstructions进行预训练的LLM在自由形式响应质量方面优于标准预训练方法。
📝 摘要(中文)
由于监督训练数据的限制,大型语言模型(LLM)通常通过在大量非结构化文本数据上进行自监督的“预测下一个词”目标进行预训练。为了使生成的模型对用户有用,需要进一步在少量“指令调优”数据上进行训练,这些数据由指令和响应的监督训练样本组成。为了克服监督数据的限制,我们提出了一种程序,可以将互联网规模的预训练文档中的知识转化为数十亿个合成指令和答案训练对。由此产生的数据集称为FineInstructions,它使用了约1800万个从真实用户编写的查询和提示中创建的指令模板。这些指令模板与来自非结构化预训练语料库的人工编写的源文档进行匹配和实例化。通过这种规模生成的“监督”合成训练数据,LLM可以完全使用指令调优目标从头开始进行预训练,这与LLM的预期下游使用(响应用户提示)更加一致。我们进行了受控的token-for-token训练实验,发现FineInstructions上的预训练在衡量自由形式响应质量的标准基准上优于标准预训练和其他提出的合成预训练技术。我们的资源可以在https://huggingface.co/fineinstructions找到。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的预训练主要依赖于自监督学习,即在海量无标注文本上预测下一个词。这种方法虽然能够学习到丰富的语言知识,但与LLM最终的应用场景(即响应用户指令)存在差距。指令调优(Instruction Tuning)是弥补这一差距的关键步骤,但高质量的指令数据获取成本高昂,限制了模型性能的进一步提升。
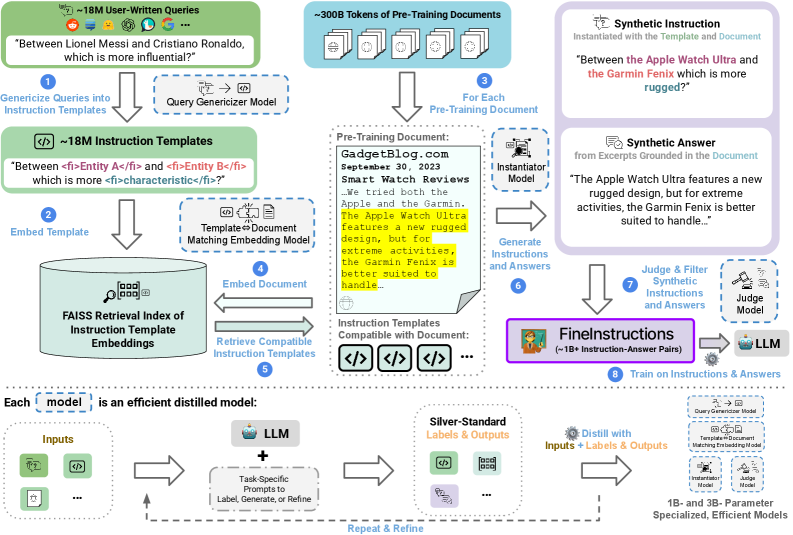
核心思路:FineInstructions的核心思路是利用已有的海量预训练语料,通过自动化的方式生成大规模的合成指令数据。具体来说,该方法首先收集大量的用户查询和提示,作为指令模板。然后,将这些指令模板与预训练语料中的文档进行匹配,并根据文档内容生成相应的答案。通过这种方式,可以将预训练语料中的知识转化为指令和答案对,从而构建大规模的指令数据集。
技术框架:FineInstructions的整体框架包括以下几个主要步骤:1) 指令模板生成:从真实用户查询和提示中提取指令模板。2) 文档匹配:将指令模板与预训练语料库中的文档进行匹配。3) 答案生成:根据匹配的文档内容,生成相应的答案。4) 数据集构建:将指令和答案对组合成FineInstructions数据集。
关键创新:FineInstructions的关键创新在于其能够以低成本的方式生成大规模的合成指令数据。与人工标注的指令数据相比,FineInstructions数据集的规模更大,覆盖范围更广,并且可以随着预训练语料的更新而不断扩展。此外,FineInstructions数据集的生成过程是自动化的,可以避免人工标注的主观性和偏差。
关键设计:FineInstructions使用了约1800万个指令模板,这些模板来源于真实的用户查询和提示。在文档匹配阶段,该方法使用了基于关键词和语义相似度的匹配算法,以确保指令模板能够与相关的文档进行匹配。在答案生成阶段,该方法使用了简单的文本抽取和生成技术,以确保答案的准确性和流畅性。该论文没有详细说明损失函数和网络结构,因为其重点在于数据集的构建和预训练效果的验证。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用FineInstructions进行预训练的LLM在标准基准测试中表现优异,超过了使用标准预训练方法和其他合成预训练技术训练的模型。具体来说,在衡量自由形式响应质量的指标上,FineInstructions预训练的模型取得了显著的提升,证明了该方法的有效性。
🎯 应用场景
FineInstructions数据集可以用于预训练或微调各种LLM,提高模型在问答、文本生成、对话等任务中的性能。该方法降低了指令数据的获取成本,使得研究人员和开发者能够更容易地构建和训练高性能的LLM。未来,该方法可以扩展到其他领域,例如代码生成、图像描述等。
📄 摘要(原文)
Due to limited supervised training data, large language models (LLMs) are typically pre-trained via a self-supervised "predict the next word" objective on a vast amount of unstructured text data. To make the resulting model useful to users, it is further trained on a far smaller amount of "instruction-tuning" data comprised of supervised training examples of instructions and responses. To overcome the limited amount of supervised data, we propose a procedure that can transform the knowledge in internet-scale pre-training documents into billions of synthetic instruction and answer training pairs. The resulting dataset, called FineInstructions, uses ~18M instruction templates created from real user-written queries and prompts. These instruction templates are matched to and instantiated with human-written source documents from unstructured pre-training corpora. With "supervised" synthetic training data generated at this scale, an LLM can be pre-trained from scratch solely with the instruction-tuning objective, which is far more in-distribution with the expected downstream usage of LLMs (responding to user prompts). We conduct controlled token-for-token training experiments and find pre-training on FineInstructions outperforms standard pre-training and other proposed synthetic pre-training techniques on standard benchmarks measuring free-form response quality. Our resources can be found at https://huggingface.co/fineinstructions .