Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers
作者: Xin Chen, Feng Jiang, Yiqian Zhang, Hardy Chen, Shuo Yan, Wenya Xie, Min Yang, Shujian Huang
分类: cs.CL, cs.AI
发布日期: 2026-01-29
备注: The manuscript is under review
🔗 代码/项目: GITHUB
💡 一句话要点
提出主动交互推理PIR,将LLM从被动求解器转变为主动询问者,提升推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动交互推理 大型语言模型 不确定性感知 策略优化 用户模拟器
📋 核心要点
- 现有LLM在推理时存在“盲目自思考”的局限,即使信息不足或模糊也进行大量内部推理。
- PIR的核心思想是让LLM在推理过程中主动与用户交互,澄清前提和意图的不确定性。
- 实验表明,PIR在数学推理、代码生成和文档编辑等任务上显著优于现有方法,并减少了计算量。
📝 摘要(中文)
面向推理的大型语言模型(LLMs)通过思维链(CoT)提示取得了显著进展,但仍然受到“盲目自我思考”模式的限制:即使在关键信息缺失或不明确时也进行广泛的内部推理。本文提出了主动交互推理(PIR),一种新的推理范式,将LLM从被动求解器转变为主动询问者,通过澄清来交错推理。与主要通过查询外部环境来解决知识不确定性的现有基于搜索或工具的框架不同,PIR通过与用户的直接交互来针对前提和意图层面的不确定性。PIR通过两个核心组件实现:(1)一种不确定性感知的监督微调程序,使模型具备交互式推理能力;(2)一个基于用户模拟器的策略优化框架,由复合奖励驱动,使模型行为与用户意图对齐。在数学推理、代码生成和文档编辑方面的大量实验表明,PIR始终优于强大的基线,实现了高达32.70%的准确率提升、22.90%的通过率提升和41.36 BLEU的改进,同时减少了近一半的推理计算和不必要的交互轮次。对事实知识、问题回答和缺失前提场景的进一步可靠性评估证实了PIR的强大泛化性和鲁棒性。模型和代码已公开。
🔬 方法详解
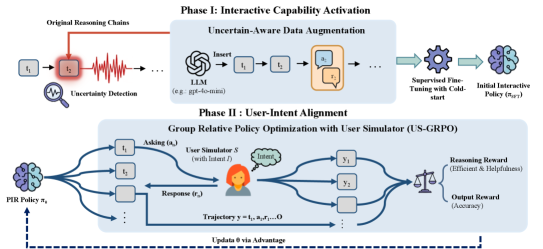
问题定义:现有的大型语言模型在进行复杂推理时,即使面临信息缺失或不明确的情况,仍然会进行大量的内部推理,导致效率低下甚至错误的结果。这种“盲目自思考”的模式忽略了与用户交互以获取必要信息的可能性。因此,需要一种新的推理范式,使模型能够主动识别并解决推理过程中的不确定性。
核心思路:PIR的核心思路是将LLM从被动的求解者转变为主动的询问者。模型在推理过程中,如果遇到不确定性,会主动向用户提问以获取更多信息,从而避免在不完整的信息基础上进行推理。这种交互式的推理方式能够提高推理的准确性和效率。
技术框架:PIR的整体框架包含两个主要组件:不确定性感知的监督微调和基于用户模拟器的策略优化。首先,通过监督微调,模型学会识别推理过程中的不确定性,并生成合适的提问。然后,利用用户模拟器与模型进行交互,并通过策略优化,使模型的提问策略与用户意图对齐。用户模拟器提供反馈,指导模型学习更有效的提问方式。
关键创新:PIR的关键创新在于引入了主动交互的推理范式,与传统的被动推理方式不同,PIR允许模型在推理过程中主动获取信息。此外,PIR还设计了不确定性感知的微调方法和基于用户模拟器的策略优化框架,使模型能够有效地进行交互式推理。这与以往主要依赖外部知识库查询或工具调用的方法有本质区别,PIR直接针对前提和意图层面的不确定性。
关键设计:不确定性感知的监督微调通过构造包含提问和回答的数据集来实现。策略优化使用复合奖励函数,综合考虑推理的准确性、交互的次数和与用户意图的对齐程度。用户模拟器模拟用户的行为,并根据模型的提问给出相应的回答。具体的损失函数和网络结构细节在论文中进行了详细描述,但此处未提供。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PIR在数学推理任务上取得了高达32.70%的准确率提升,在代码生成任务上取得了22.90%的通过率提升,在文档编辑任务上取得了41.36 BLEU的改进。同时,PIR还减少了近一半的推理计算和不必要的交互轮次。这些结果表明,PIR能够显著提高LLM的推理性能和效率。
🎯 应用场景
PIR具有广泛的应用前景,可以应用于数学问题求解、代码生成、文档编辑等需要复杂推理的场景。通过主动与用户交互,PIR能够提高这些任务的准确性和效率。此外,PIR还可以应用于智能客服、人机协作等领域,提升用户体验和工作效率。未来,PIR有望成为构建更智能、更可靠的人工智能系统的关键技术。
📄 摘要(原文)
Reasoning-oriented Large Language Models (LLMs) have achieved remarkable progress with Chain-of-Thought (CoT) prompting, yet they remain fundamentally limited by a \emph{blind self-thinking} paradigm: performing extensive internal reasoning even when critical information is missing or ambiguous. We propose Proactive Interactive Reasoning (PIR), a new reasoning paradigm that transforms LLMs from passive solvers into proactive inquirers that interleave reasoning with clarification. Unlike existing search- or tool-based frameworks that primarily address knowledge uncertainty by querying external environments, PIR targets premise- and intent-level uncertainty through direct interaction with the user. PIR is implemented via two core components: (1) an uncertainty-aware supervised fine-tuning procedure that equips models with interactive reasoning capability, and (2) a user-simulator-based policy optimization framework driven by a composite reward that aligns model behavior with user intent. Extensive experiments on mathematical reasoning, code generation, and document editing demonstrate that PIR consistently outperforms strong baselines, achieving up to 32.70\% higher accuracy, 22.90\% higher pass rate, and 41.36 BLEU improvement, while reducing nearly half of the reasoning computation and unnecessary interaction turns. Further reliability evaluations on factual knowledge, question answering, and missing-premise scenarios confirm the strong generalization and robustness of PIR. Model and code are publicly available at: \href{https://github.com/SUAT-AIRI/Proactive-Interactive-R1}