ECO: Quantized Training without Full-Precision Master Weights
作者: Mahdi Nikdan, Amir Zandieh, Dan Alistarh, Vahab Mirrokni
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-29
💡 一句话要点
ECO:无需全精度Master Weights的量化训练方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化训练 大型语言模型 误差补偿 无Master Weights 内存优化 稀疏混合专家模型 低精度训练
📋 核心要点
- 现有量化训练方法依赖高精度master weights,导致显著的内存开销,尤其在SMoE模型中。
- ECO通过直接更新量化参数并利用误差反馈机制,消除了master weights,降低了内存需求。
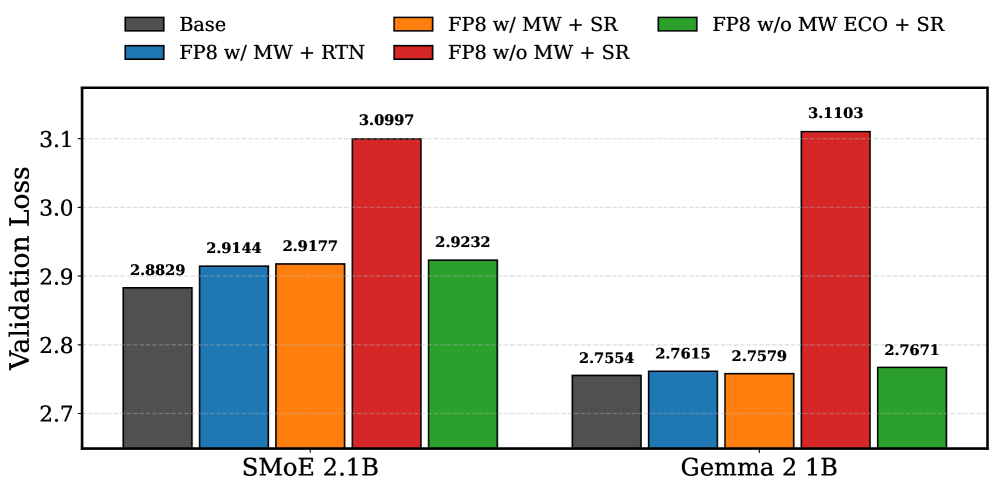
- 实验表明,ECO在预训练和微调任务中,能以接近无损的精度匹配使用master weights的基线。
📝 摘要(中文)
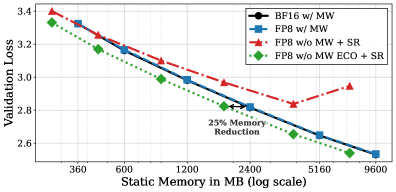
量化显著提高了大型语言模型(LLM)训练的计算和内存效率。然而,现有方法仍然依赖于在高精度下累积更新:具体而言,梯度更新必须应用于高精度的权重缓冲区,即所谓的“master weights”。该缓冲区引入了大量的内存开销,特别是对于稀疏混合专家(SMoE)模型,其中模型参数和优化器状态占据了主要的内存使用。为了解决这个问题,我们引入了误差补偿优化器(ECO),它通过直接将更新应用于量化参数来消除master weights。ECO在每个步骤后量化权重,并将由此产生的量化误差谨慎地注入到优化器的动量中,形成一个没有额外内存的误差反馈循环。我们证明,在标准假设和衰减学习率下,ECO收敛到最优解的恒定半径邻域,而naive的master-weight移除可能导致与学习率成反比的误差。我们展示了预训练小型Transformer(30-800M)、Gemma-3 1B模型和具有FP8量化的2.1B参数稀疏MoE模型的实验结果,以及在INT4精度下微调DeepSeek-MoE-16B模型的实验结果。在整个过程中,ECO匹配了具有master weights的基线,达到了接近无损的精度,显著改变了静态内存与验证损失的帕累托前沿。
🔬 方法详解
问题定义:现有量化训练方法在训练大型语言模型时,为了保证精度,需要维护一份高精度的权重副本(master weights),用于累积梯度更新。这导致了巨大的内存开销,尤其是在参数量巨大的稀疏混合专家模型(SMoE)中,内存瓶颈问题更加突出。直接对量化后的权重进行更新会导致精度损失,难以收敛。
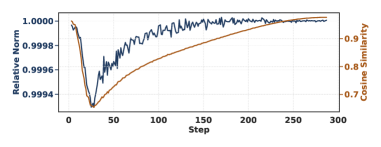
核心思路:ECO的核心思想是通过误差补偿机制,直接对量化后的权重进行更新,从而避免使用master weights。它将量化过程中产生的误差注入到优化器的动量中,形成一个误差反馈循环,从而在不增加额外内存开销的情况下,保证训练的收敛性。
技术框架:ECO的整体框架如下:1. 前向传播和反向传播,计算梯度;2. 将梯度应用到量化后的权重上,更新权重;3. 量化更新后的权重;4. 计算量化误差,并将该误差注入到优化器的动量中;5. 使用更新后的动量进行下一步的权重更新。该过程循环进行,直到模型收敛。
关键创新:ECO最关键的创新在于它消除了对master weights的依赖,通过误差补偿机制实现了在量化权重上的直接训练。与传统的量化训练方法相比,ECO不需要额外的内存来存储master weights,从而显著降低了内存开销。此外,ECO的误差反馈机制能够有效地补偿量化误差,保证了训练的收敛性。
关键设计:ECO的关键设计在于如何将量化误差有效地注入到优化器的动量中。具体来说,ECO使用动量优化器(如Adam或SGD with Momentum),并将量化误差添加到动量的更新项中。这样,动量不仅包含了历史梯度的信息,还包含了历史量化误差的信息,从而能够更好地补偿量化带来的精度损失。学习率采用衰减策略,以保证收敛性。
🖼️ 关键图片
📊 实验亮点
ECO在多个模型和数据集上进行了实验验证。在预训练小型Transformer(30-800M)、Gemma-3 1B模型和具有FP8量化的2.1B参数稀疏MoE模型时,ECO的性能与使用master weights的基线相当,达到了接近无损的精度。在INT4精度下微调DeepSeek-MoE-16B模型时,ECO也取得了类似的结果,证明了其在不同模型和精度下的有效性。
🎯 应用场景
ECO具有广泛的应用前景,尤其适用于资源受限的场景下训练和部署大型语言模型。它可以降低训练所需的GPU内存,使得在消费级硬件上训练大型模型成为可能。此外,ECO还可以应用于边缘设备上的模型部署,降低模型的大小和计算复杂度,提高推理效率。
📄 摘要(原文)
Quantization has significantly improved the compute and memory efficiency of Large Language Model (LLM) training. However, existing approaches still rely on accumulating their updates in high-precision: concretely, gradient updates must be applied to a high-precision weight buffer, known as $\textit{master weights}$. This buffer introduces substantial memory overhead, particularly for Sparse Mixture of Experts (SMoE) models, where model parameters and optimizer states dominate memory usage. To address this, we introduce the Error-Compensating Optimizer (ECO), which eliminates master weights by applying updates directly to quantized parameters. ECO quantizes weights after each step and carefully injects the resulting quantization error into the optimizer momentum, forming an error-feedback loop with no additional memory. We prove that, under standard assumptions and a decaying learning rate, ECO converges to a constant-radius neighborhood of the optimum, while naive master-weight removal can incur an error that is inversely proportional to the learning rate. We show empirical results for pretraining small Transformers (30-800M), a Gemma-3 1B model, and a 2.1B parameter Sparse MoE model with FP8 quantization, and fine-tuning DeepSeek-MoE-16B in INT4 precision. Throughout, ECO matches baselines with master weights up to near-lossless accuracy, significantly shifting the static memory vs validation loss Pareto frontier.