MasalBench: A Benchmark for Contextual and Cross-Cultural Understanding of Persian Proverbs in LLMs
作者: Ghazal Kalhor, Behnam Bahrak
分类: cs.CL
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
MasalBench:构建波斯谚语理解基准,评估LLM的语境和跨文化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低资源语言 波斯语 谚语理解 跨文化理解
📋 核心要点
- 现有工作对LLM在高资源语言中的比喻理解进行了评估,但对低资源语言的探索不足。
- 论文构建了MasalBench基准,用于评估LLM对波斯谚语的语境和跨文化理解能力。
- 实验表明,LLM在识别波斯谚语方面表现良好,但在识别等效英语谚语时性能显著下降。
📝 摘要(中文)
近年来,多语言大型语言模型(LLMs)已成为日常生活中不可或缺的一部分,因此它们掌握会话语言的规则以与用户有效沟通至关重要。虽然之前的工作已经评估了LLMs对高资源语言中比喻语言的理解,但它们在低资源语言中的表现仍未得到充分探索。在本文中,我们介绍了MasalBench,这是一个综合基准,用于评估LLMs对波斯谚语的语境和跨文化理解,波斯谚语是这种低资源语言中对话的关键组成部分。我们评估了八个最先进的LLMs在MasalBench上的表现,发现它们在识别语境中的波斯谚语方面表现良好,准确率超过0.90。然而,当要求识别等效的英语谚语时,它们的表现显着下降,最佳模型的准确率为0.79。我们的研究结果突出了当前LLMs在文化知识和类比推理方面的局限性,并为评估其他低资源语言的跨文化理解提供了一个框架。MasalBench可在https://github.com/kalhorghazal/MasalBench上获取。
🔬 方法详解
问题定义:论文旨在解决LLM在低资源语言(特别是波斯语)中,对谚语的语境理解和跨文化理解不足的问题。现有方法主要集中在高资源语言上,忽略了低资源语言的特殊性和文化背景,导致LLM在处理这些语言时表现不佳。现有方法缺乏针对低资源语言谚语理解的专门评估基准。
核心思路:论文的核心思路是构建一个专门针对波斯谚语的基准数据集MasalBench,通过设计不同的任务来评估LLM在语境中理解和翻译谚语的能力。通过分析LLM在这些任务上的表现,揭示其在文化知识和类比推理方面的局限性,并为未来的研究提供方向。
技术框架:MasalBench基准包含两个主要任务:1) 在给定的语境中识别波斯谚语;2) 找到与给定波斯谚语等价的英语谚语。研究者使用该基准评估了八个最先进的LLM。评估流程包括将测试用例输入LLM,然后根据LLM的输出计算准确率等指标。
关键创新:该论文的关键创新在于构建了MasalBench,这是第一个专门用于评估LLM对波斯谚语理解的基准数据集。该基准不仅关注LLM识别谚语的能力,还关注其跨文化理解和类比推理能力。与现有方法相比,MasalBench更侧重于低资源语言和文化背景。
关键设计:MasalBench包含语境化的波斯谚语,并要求模型识别谚语并将其翻译成对应的英文谚语。数据集的设计考虑了谚语的多样性和复杂性,以及不同文化背景下谚语的差异。评估指标主要采用准确率,用于衡量模型在识别和翻译谚语方面的性能。
🖼️ 关键图片

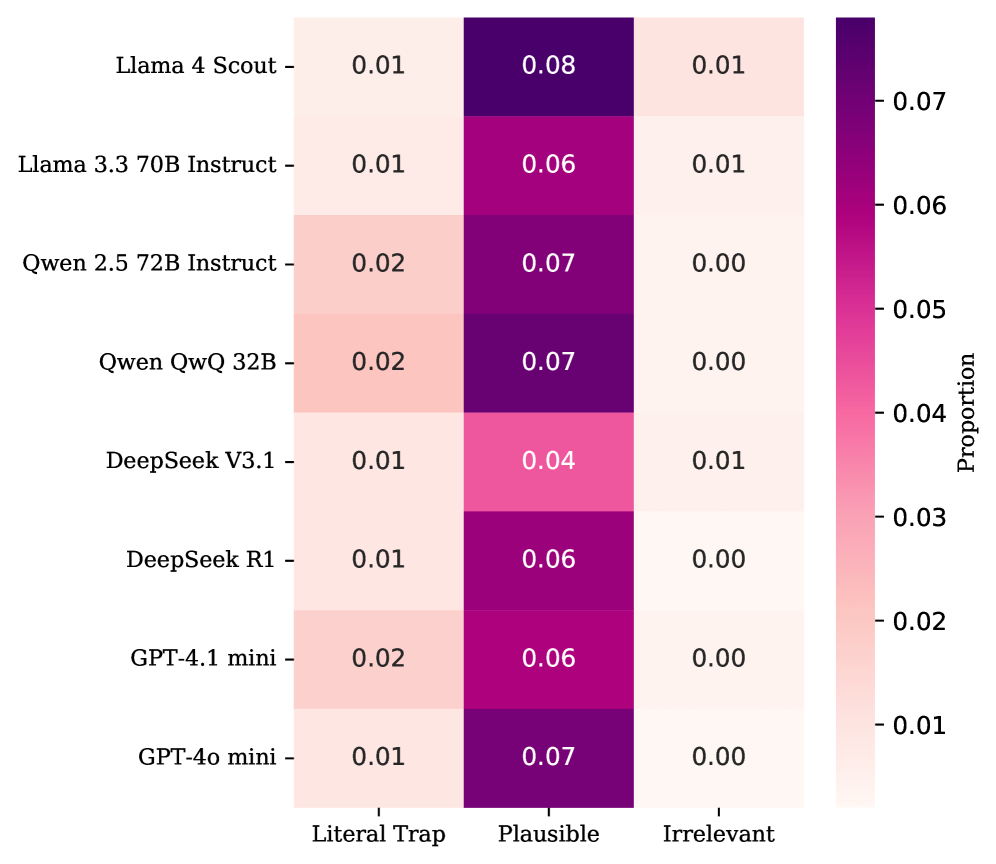

📊 实验亮点
实验结果表明,LLM在识别语境中的波斯谚语方面表现良好,准确率超过0.90。然而,在识别等效的英语谚语时,性能显著下降,最佳模型的准确率为0.79。这表明当前LLM在文化知识和类比推理方面存在局限性,需要进一步改进。MasalBench的发布为后续研究提供了一个有价值的评估工具。
🎯 应用场景
该研究成果可应用于提升LLM在低资源语言环境下的自然语言处理能力,尤其是在机器翻译、跨文化交流和智能对话系统等领域。通过提高LLM对谚语等文化元素的理解,可以使其更好地适应不同文化背景的用户,从而提升用户体验和应用效果。未来,该研究可以扩展到其他低资源语言,构建更全面的跨文化理解评估体系。
📄 摘要(原文)
In recent years, multilingual Large Language Models (LLMs) have become an inseparable part of daily life, making it crucial for them to master the rules of conversational language in order to communicate effectively with users. While previous work has evaluated LLMs' understanding of figurative language in high-resource languages, their performance in low-resource languages remains underexplored. In this paper, we introduce MasalBench, a comprehensive benchmark for assessing LLMs' contextual and cross-cultural understanding of Persian proverbs, which are a key component of conversation in this low-resource language. We evaluate eight state-of-the-art LLMs on MasalBench and find that they perform well in identifying Persian proverbs in context, achieving accuracies above 0.90. However, their performance drops considerably when tasked with identifying equivalent English proverbs, with the best model achieving 0.79 accuracy. Our findings highlight the limitations of current LLMs in cultural knowledge and analogical reasoning, and they provide a framework for assessing cross-cultural understanding in other low-resource languages. MasalBench is available at https://github.com/kalhorghazal/MasalBench.