Thinking Out of Order: When Output Order Stops Reflecting Reasoning Order in Diffusion Language Models
作者: Longxuan Yu, Yu Fu, Shaorong Zhang, Hui Liu, Mukund Varma T, Greg Ver Steeg, Yue Dong
分类: cs.CL, cs.AI
发布日期: 2026-01-29
备注: 18 pages, 13 figures, 5 tables
💡 一句话要点
提出掩蔽扩散语言模型以解决自回归模型的推理顺序问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 掩蔽扩散语言模型 自回归模型 推理顺序 顺序鲁棒性 机器学习 自然语言处理
📋 核心要点
- 自回归模型在推理顺序与输出结构不一致时,容易导致提前承诺,造成准确率下降。
- 掩蔽扩散语言模型通过并行处理所有标记,允许推理步骤在答案之前稳定,从而解决了这一问题。
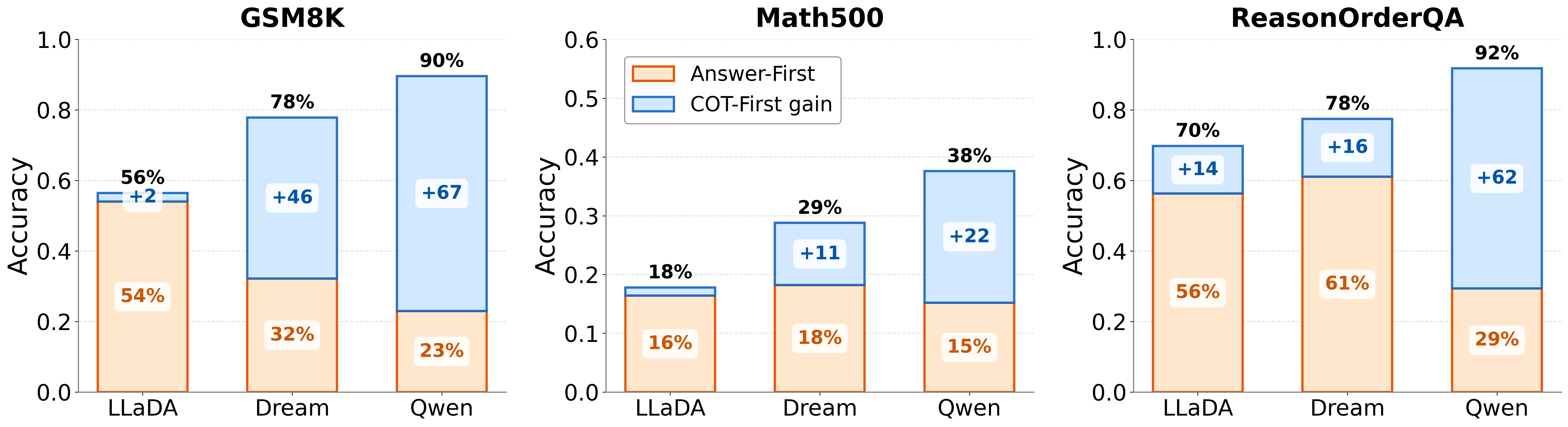
- 实验结果显示,MDLMs在要求先给出答案的情况下,准确率下降幅度小于14%,而自回归模型可达67%。
📝 摘要(中文)
自回归语言模型强制执行固定的从左到右的生成顺序,这在输出结构与自然推理相冲突时造成了根本性限制。掩蔽扩散语言模型(MDLMs)通过并行迭代精炼所有标记,提供了一种将计算顺序与输出结构解耦的方法。我们在GSM8K、Math500和我们引入的ReasonOrderQA基准上验证了这一能力。实验表明,当提示要求在推理之前给出答案时,自回归模型的准确率显著下降,而MDLMs保持稳定,这一特性被称为“顺序鲁棒性”。
🔬 方法详解
问题定义:本文解决自回归语言模型在输出顺序与推理顺序不一致时的准确率下降问题。现有方法在需要先给出答案时,往往导致模型提前承诺,影响推理质量。
核心思路:提出掩蔽扩散语言模型(MDLMs),通过并行处理所有标记,解耦计算顺序与输出结构,使得推理步骤可以在答案之前稳定,从而避免提前承诺。
技术框架:MDLMs的整体架构包括多个阶段:输入标记的并行处理、迭代精炼过程以及最终输出生成。每个阶段都允许模型在不受固定顺序限制的情况下进行推理。
关键创新:MDLMs的核心创新在于其“顺序鲁棒性”,即在推理过程中,简单标记(如推理步骤)比复杂标记(如最终答案)更早稳定,从而提高了模型在特定输出顺序下的表现。
关键设计:在模型设计中,采用了特定的损失函数和参数设置,以确保在推理过程中能够优先稳定简单标记,进而影响最终答案的生成。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当提示要求先给出答案时,自回归模型的准确率下降幅度可达67%,而MDLMs的下降幅度仅为14%。这一显著差异展示了MDLMs在处理推理顺序问题上的优势,验证了其“顺序鲁棒性”的有效性。
🎯 应用场景
该研究的潜在应用领域包括教育、自动问答系统和复杂推理任务等。通过提高模型在不同输出顺序下的鲁棒性,MDLMs能够在实际应用中提供更准确和可靠的结果,尤其是在需要复杂推理的场景中。
📄 摘要(原文)
Autoregressive (AR) language models enforce a fixed left-to-right generation order, creating a fundamental limitation when the required output structure conflicts with natural reasoning (e.g., producing answers before explanations due to presentation or schema constraints). In such cases, AR models must commit to answers before generating intermediate reasoning, and this rigid constraint forces premature commitment. Masked diffusion language models (MDLMs), which iteratively refine all tokens in parallel, offer a way to decouple computation order from output structure. We validate this capability on GSM8K, Math500, and ReasonOrderQA, a benchmark we introduce with controlled difficulty and order-level evaluation. When prompts request answers before reasoning, AR models exhibit large accuracy gaps compared to standard chain-of-thought ordering (up to 67% relative drop), while MDLMs remain stable ($\leq$14% relative drop), a property we term "order robustness". Using ReasonOrderQA, we present evidence that MDLMs achieve order robustness by stabilizing simpler tokens (e.g., reasoning steps) earlier in the diffusion process than complex ones (e.g., final answers), enabling reasoning tokens to stabilize before answer commitment. Finally, we identify failure conditions where this advantage weakens, outlining the limits required for order robustness.