OVD: On-policy Verbal Distillation
作者: Jing Xiong, Hui Shen, Shansan Gong, Yuxin Cheng, Jianghan Shen, Chaofan Tao, Haochen Tan, Haoli Bai, Lifeng Shang, Ngai Wong
分类: cs.CL
发布日期: 2026-01-29
备注: Technical Report
💡 一句话要点
提出On-policy Verbal Distillation,解决强化学习中知识蒸馏的内存瓶颈问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 On-policy学习 强化学习 模型压缩 Web问答 数学推理 轨迹匹配 Verbal分数
📋 核心要点
- 现有token级On-policy蒸馏方法需token对齐,限制学生模型探索,且在强化学习中存在严重内存瓶颈。
- OVD使用教师模型的离散verbal分数进行轨迹匹配,替代token级概率匹配,实现高效的On-policy蒸馏。
- 实验表明,OVD在Web问答和数学推理任务上显著优于现有方法,并具有更高的训练效率。
📝 摘要(中文)
知识蒸馏为将大型教师模型的推理能力迁移到高效的学生模型提供了一条有希望的途径。然而,现有的token级别On-policy蒸馏方法需要学生模型和教师模型之间的token级别对齐,这限制了学生模型的探索能力,阻碍了交互式环境反馈的有效利用,并遭受强化学习中严重的内存瓶颈。我们引入了On-policy Verbal Distillation (OVD),这是一个内存高效的框架,它使用来自教师模型的离散verbal分数(0-9)进行轨迹匹配,取代了token级别的概率匹配。OVD显著降低了内存消耗,同时实现了来自具有verbal反馈的教师模型的On-policy蒸馏,并避免了token级别的对齐,允许学生模型自由探索输出空间。在Web问答和数学推理任务上的大量实验表明,OVD显著优于现有方法,在Web问答任务上的平均EM值绝对提升高达+12.9%,在数学基准测试中提升高达+25.7%(仅使用一个随机样本进行训练时),同时还表现出卓越的训练效率。
🔬 方法详解
问题定义:现有token级别的On-policy知识蒸馏方法,在强化学习环境中,需要学生模型和教师模型在token级别上进行对齐。这种对齐限制了学生模型的探索能力,无法有效利用环境的交互反馈,并且由于需要存储大量的token级别信息,导致严重的内存瓶颈。
核心思路:OVD的核心思路是用离散的verbal分数(0-9)来表示教师模型的行为,并使用这些分数进行轨迹匹配,而不是直接匹配token级别的概率分布。通过这种方式,避免了学生模型和教师模型在token级别上的强制对齐,允许学生模型自由探索输出空间,同时显著降低了内存消耗。
技术框架:OVD框架主要包含教师模型和学生模型。教师模型负责生成verbal分数,学生模型则根据环境反馈和教师模型的verbal分数进行学习。训练过程中,学生模型的目标是生成与教师模型相似的verbal分数序列,从而模仿教师模型的行为。整个框架采用On-policy的方式进行训练,即学生模型根据当前策略与环境交互,并利用交互数据进行学习。
关键创新:OVD最重要的创新点在于使用离散的verbal分数进行轨迹匹配,替代了传统的token级别概率匹配。这种方法避免了token级别的对齐,允许学生模型自由探索,同时显著降低了内存消耗。此外,OVD还能够有效利用环境的交互反馈,提高学生模型的学习效率。
关键设计:OVD的关键设计包括:1) 使用离散的verbal分数(0-9)来表示教师模型的行为;2) 设计合适的损失函数,用于衡量学生模型生成的verbal分数序列与教师模型之间的差异;3) 采用On-policy的训练方式,利用环境的交互反馈进行学习。具体的损失函数和网络结构等细节,论文中可能包含更详细的描述。
🖼️ 关键图片

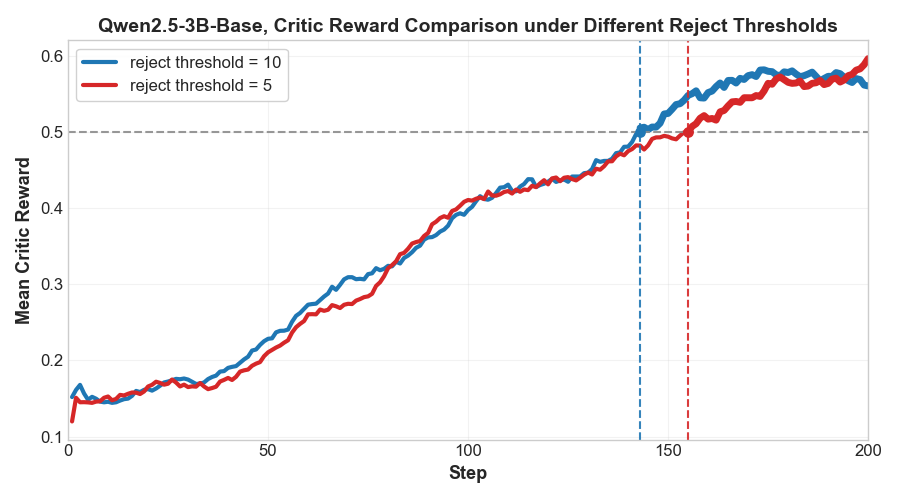
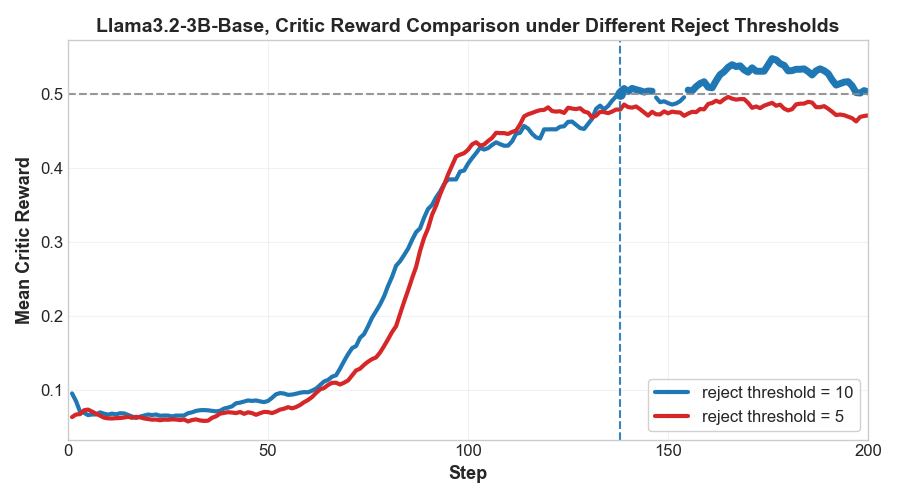
📊 实验亮点
OVD在Web问答任务上取得了显著的性能提升,平均EM值绝对提升高达+12.9%。在数学推理任务中,OVD的性能提升高达+25.7%(仅使用一个随机样本进行训练时)。此外,OVD还表现出卓越的训练效率,证明了其在知识蒸馏方面的优越性。这些实验结果表明,OVD是一种有效的知识蒸馏方法,能够显著提高学生模型的性能。
🎯 应用场景
OVD具有广泛的应用前景,可应用于各种需要知识迁移和模型压缩的强化学习任务中,例如机器人控制、游戏AI、自然语言处理等。该方法能够有效降低模型大小和计算复杂度,使其更容易部署在资源受限的设备上,并加速模型的训练过程。此外,OVD还可以用于提高模型的鲁棒性和泛化能力。
📄 摘要(原文)
Knowledge distillation offers a promising path to transfer reasoning capabilities from large teacher models to efficient student models; however, existing token-level on-policy distillation methods require token-level alignment between the student and teacher models, which restricts the student model's exploration ability, prevent effective use of interactive environment feedback, and suffer from severe memory bottlenecks in reinforcement learning. We introduce On-policy Verbal Distillation (OVD), a memory-efficient framework that replaces token-level probability matching with trajectory matching using discrete verbal scores (0--9) from teacher models. OVD dramatically reduces memory consumption while enabling on-policy distillation from teacher models with verbal feedback, and avoids token-level alignment, allowing the student model to freely explore the output space. Extensive experiments on Web question answering and mathematical reasoning tasks show that OVD substantially outperforms existing methods, delivering up to +12.9% absolute improvement in average EM on Web Q&A tasks and a up to +25.7% gain on math benchmarks (when trained with only one random samples), while also exhibiting superior training efficiency. Our project page is available at https://OVD.github.io