Learn-to-Distance: Distance Learning for Detecting LLM-Generated Text
作者: Hongyi Zhou, Jin Zhu, Erhan Xu, Kai Ye, Ying Yang, Chengchun Shi
分类: cs.CL, cs.AI, stat.ML
发布日期: 2026-01-29
备注: Accepted by ICLR2026
💡 一句话要点
提出Learn-to-Distance算法,自适应学习文本距离以检测LLM生成内容
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM文本检测 自适应距离学习 重写检测 对比学习 自然语言处理
📋 核心要点
- 现有基于重写的LLM文本检测算法缺乏对文本距离的有效建模,限制了检测性能和泛化能力。
- 提出Learn-to-Distance算法,通过自适应学习原始文本和重写文本之间的距离,更准确地判断文本是否由LLM生成。
- 实验结果表明,该方法在多种LLM生成文本检测任务中,显著优于现有基线方法,提升幅度高达80.6%。
📝 摘要(中文)
现代大型语言模型(LLM),如GPT、Claude和Gemini,已经改变了我们的学习、工作和交流方式。然而,它们生成高度类人文本的能力引发了对虚假信息和学术诚信的严重担忧,因此迫切需要可靠的算法来检测LLM生成的内容。本文首先提出了一种几何方法来揭示基于重写的检测算法,阐明其内在原理并展示其泛化能力。在此基础上,我们提出了一种新的基于重写的检测算法,该算法能够自适应地学习原始文本和重写文本之间的距离。理论上,我们证明了采用自适应学习的距离函数比使用固定距离更有效。实验方面,我们进行了超过100种设置的广泛实验,发现我们的方法在大多数情况下都优于基线算法。特别是在不同的目标LLM(例如,GPT、Claude和Gemini)上,相对于最强的基线,我们的方法实现了57.8%到80.6%的相对改进。
🔬 方法详解
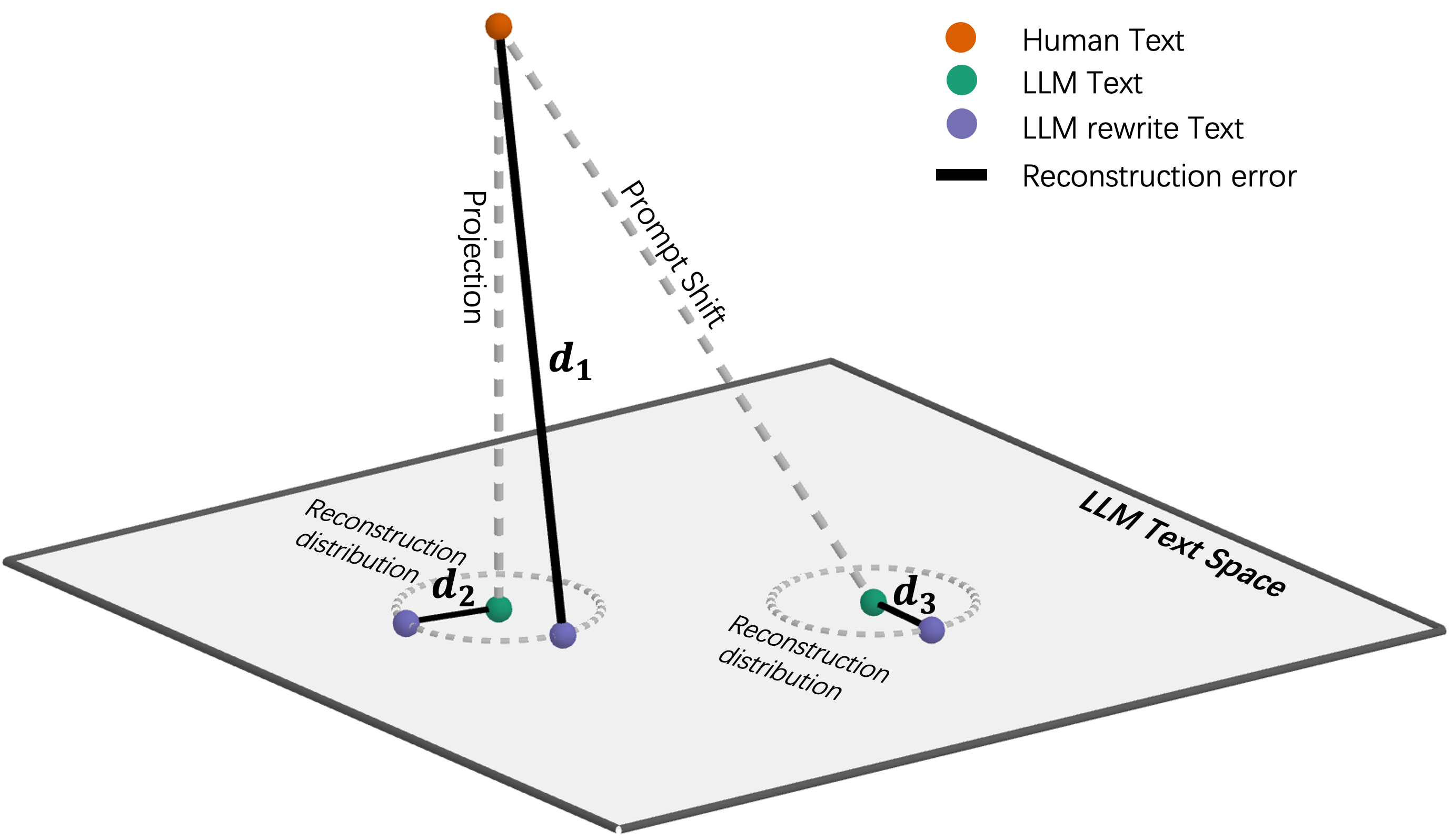
问题定义:论文旨在解决如何更准确地检测由大型语言模型(LLM)生成的文本的问题。现有的基于重写的检测算法通常使用固定的距离度量来比较原始文本和重写文本,这无法适应不同LLM和不同文本风格的变化,导致检测精度不高。
核心思路:论文的核心思路是自适应地学习原始文本和重写文本之间的距离。通过训练一个距离函数,使其能够根据文本的特征动态地调整距离度量,从而更准确地判断文本是否由LLM生成。这种自适应学习的方法可以更好地捕捉LLM生成文本的细微特征,提高检测的准确性和泛化能力。
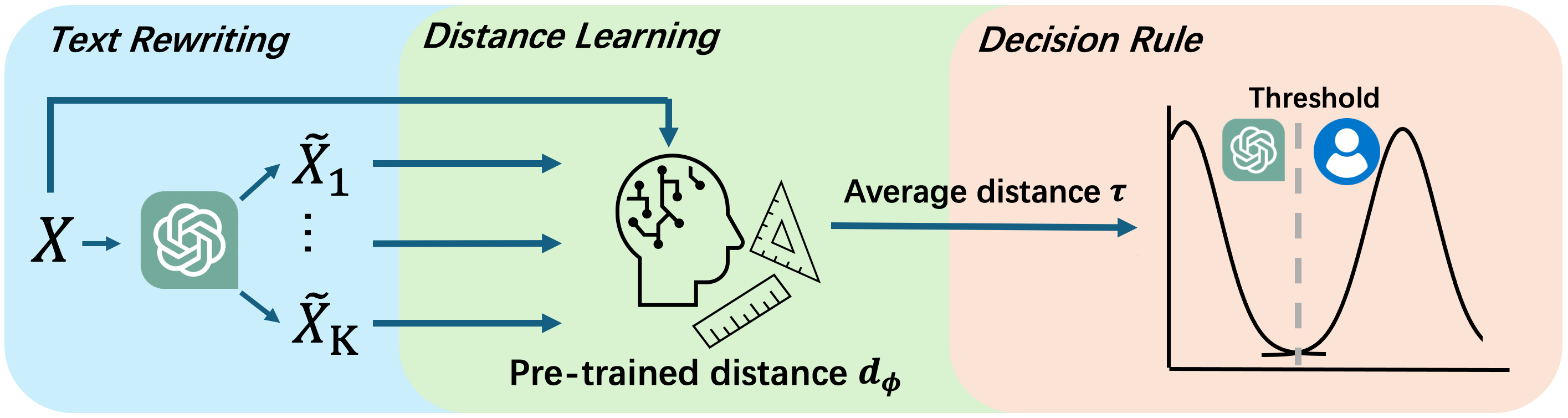
技术框架:该方法的技术框架主要包括以下几个步骤:1) 对原始文本进行重写,生成多个重写文本;2) 提取原始文本和重写文本的特征;3) 使用这些特征训练一个距离函数,该函数能够预测原始文本和重写文本之间的距离;4) 使用训练好的距离函数来判断给定的文本是否由LLM生成。如果原始文本和重写文本之间的距离小于某个阈值,则认为该文本是由LLM生成的。
关键创新:该方法最重要的技术创新点在于自适应地学习文本距离。与传统的基于固定距离度量的检测算法不同,该方法能够根据文本的特征动态地调整距离度量,从而更准确地捕捉LLM生成文本的细微特征。这种自适应学习的方法可以显著提高检测的准确性和泛化能力。
关键设计:论文中关键的设计包括:1) 使用Transformer模型提取文本特征;2) 使用对比学习损失函数训练距离函数;3) 使用多种重写策略生成重写文本。对比学习损失函数旨在拉近同一文本的不同重写版本之间的距离,并推远不同文本之间的距离。重写策略的多样性有助于模型学习到更鲁棒的文本表示。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Learn-to-Distance算法在超过100种不同的实验设置下,均优于现有的基线方法。在不同的目标LLM(如GPT、Claude和Gemini)上,该算法相对于最强的基线方法,实现了57.8%到80.6%的相对改进。这些结果证明了该算法在LLM生成文本检测方面的优越性能。
🎯 应用场景
该研究成果可广泛应用于检测虚假信息、防止学术不端行为、识别AI生成内容等领域。通过提高LLM生成文本的检测准确率,有助于维护网络信息安全和学术诚信,并为内容审核和版权保护提供技术支持。未来,该技术还可应用于更广泛的AI生成内容检测场景。
📄 摘要(原文)
Modern large language models (LLMs) such as GPT, Claude, and Gemini have transformed the way we learn, work, and communicate. Yet, their ability to produce highly human-like text raises serious concerns about misinformation and academic integrity, making it an urgent need for reliable algorithms to detect LLM-generated content. In this paper, we start by presenting a geometric approach to demystify rewrite-based detection algorithms, revealing their underlying rationale and demonstrating their generalization ability. Building on this insight, we introduce a novel rewrite-based detection algorithm that adaptively learns the distance between the original and rewritten text. Theoretically, we demonstrate that employing an adaptively learned distance function is more effective for detection than using a fixed distance. Empirically, we conduct extensive experiments with over 100 settings, and find that our approach demonstrates superior performance over baseline algorithms in the majority of scenarios. In particular, it achieves relative improvements from 57.8\% to 80.6\% over the strongest baseline across different target LLMs (e.g., GPT, Claude, and Gemini).