TACLer: Tailored Curriculum Reinforcement Learning for Efficient Reasoning
作者: Huiyuan Lai, Malvina Nissim
分类: cs.CL, cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出TACLer以提高长链推理的学习与推理效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长链推理 强化学习 课程学习 模型定制 推理效率 混合推理 自然语言处理
📋 核心要点
- 现有方法在长链推理中往往导致冗余步骤,影响学习效率和推理准确性。
- TACLer通过定制课程学习和混合推理模式,逐步提高数据复杂性,优化学习过程。
- 实验显示,TACLer在计算成本和推理准确性上均有显著提升,超越了现有基线模型。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理任务上表现出色,尤其是当其具备长链推理(CoT)能力时。然而,长链推理通常需要大规模的强化学习(RL)训练,容易导致冗余的中间步骤。为提高学习和推理效率,同时保持或增强性能,本文提出了TACLer,一个模型定制的课程强化学习框架,逐步增加数据复杂性。TACLer的两个核心组件包括:定制课程学习和混合思维/非思维推理范式。实验结果表明,TACLer在学习和推理上具有双重优势:计算成本降低超过50%,推理令牌使用减少超过42%,同时准确率提高超过9%。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在长链推理中因冗余步骤导致的学习效率低下和推理准确性不足的问题。现有方法在训练过程中往往需要大量计算资源,且容易出现过度思考现象。
核心思路:TACLer的核心思路是通过模型定制的课程学习,逐步增加数据的复杂性,以适应模型的学习能力。同时,采用混合思维/非思维推理范式,灵活调整推理模式以平衡准确性与效率。
技术框架:TACLer的整体架构包括两个主要模块:定制课程学习模块和混合推理模块。定制课程学习模块负责识别模型的知识缺口,并在多个阶段中逐步引导模型学习;混合推理模块则根据任务需求切换思维模式。
关键创新:TACLer的创新在于其定制化的课程学习策略和混合推理模式,这与传统的强化学习方法形成鲜明对比,后者通常不考虑模型的学习进度。
关键设计:在参数设置上,TACLer采用了动态调整的学习率和损失函数,以适应不同阶段的学习需求。同时,网络结构设计上考虑了推理模式的切换机制,以提高模型的灵活性和适应性。
🖼️ 关键图片
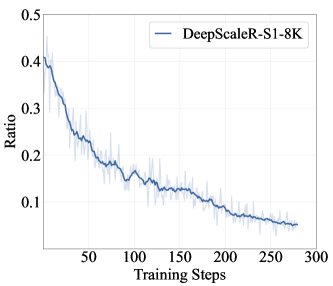
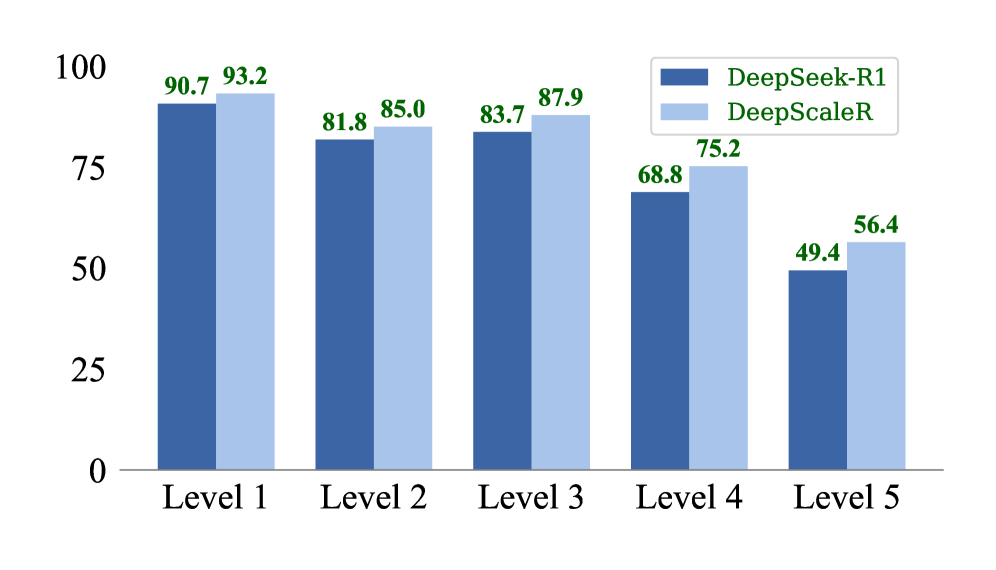
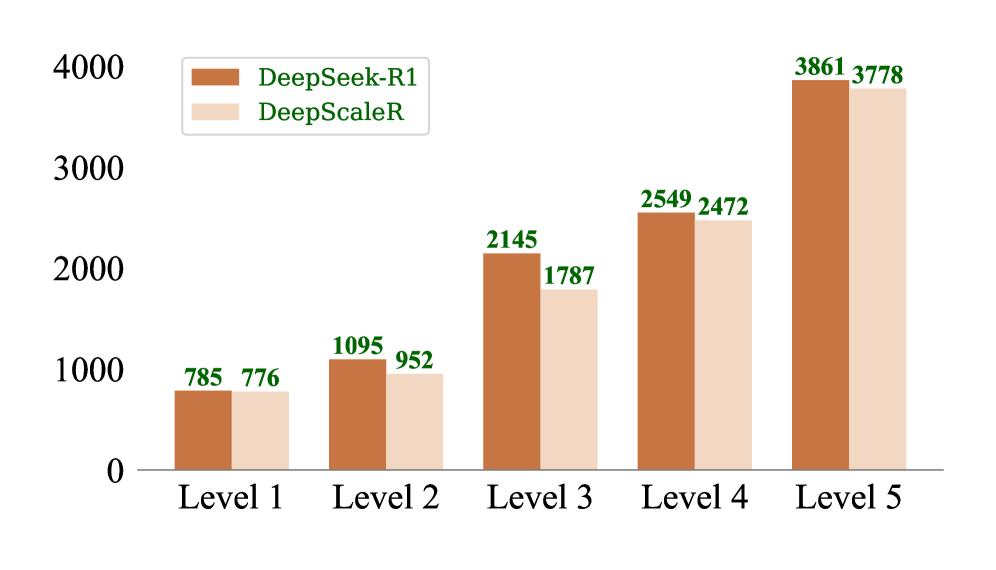
📊 实验亮点
实验结果表明,TACLer在计算成本上减少超过50%,推理令牌使用量降低超过42%。同时,准确率提升超过9%,在四个复杂数学数据集上均优于现有的思维和非思维基线模型,展现出显著的性能优势。
🎯 应用场景
TACLer的研究成果在多个领域具有广泛的应用潜力,尤其是在需要复杂推理的任务中,如数学问题求解、自然语言理解和智能问答系统。其高效的学习和推理能力将推动这些领域的技术进步,提升用户体验和系统性能。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable performance on complex reasoning tasks, especially when equipped with long chain-of-thought (CoT) reasoning. However, eliciting long CoT typically requires large-scale reinforcement learning (RL) training, while often leading to overthinking with redundant intermediate steps. To improve learning and reasoning efficiency, while preserving or even enhancing performance, we propose TACLer, a model-tailored curriculum reinforcement learning framework that gradually increases the complexity of the data based on the model's proficiency in multi-stage RL training. TACLer features two core components: (i) tailored curriculum learning that determines what knowledge the model lacks and needs to learn in progressive stages; (ii) a hybrid Thinking/NoThinking reasoning paradigm that balances accuracy and efficiency by enabling or disabling the Thinking mode. Our experiments show that TACLer yields a twofold advantage in learning and reasoning: (i) it reduces computational cost, cutting training compute by over 50% compared to long thinking models and reducing inference token usage by over 42% relative to the base model; and (ii) it improves accuracy by over 9% on the base model, consistently outperforming state-of-the-art Nothinking and Thinking baselines across four math datasets with complex problems.