Why Attention Patterns Exist: A Unifying Temporal Perspective Analysis
作者: Qingyue Yang, Jie Wang, Xing Li, Yinqi Bai, Xialiang Tong, Huiling Zhen, Jianye Hao, Mingxuan Yuan, Bin Li
分类: cs.CL
发布日期: 2026-01-29
备注: ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出TAPPA框架,从时序角度统一解释LLM注意力模式并指导推理加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 注意力机制 模型压缩 模型剪枝 推理加速 时间序列分析 可预测性分析
📋 核心要点
- 现有工作对LLM注意力模式的理解是分散的,缺乏一个统一的解释框架。
- 论文提出TAPPA框架,从时序角度分析注意力模式的可预测性,从而统一解释不同模式。
- 实验表明,基于TAPPA的指标在KV缓存压缩和LLM剪枝任务中均优于基线方法。
📝 摘要(中文)
注意力模式在大型语言模型(LLM)的训练和推理中起着至关重要的作用。先前的工作已经识别出诸如检索头、sink头和对角线轨迹等个别模式,但这些观察结果仍然是分散的,缺乏统一的解释。为了弥合这一差距,我们引入了时间注意力模式可预测性分析(TAPPA),这是一个统一的框架,通过从时间连续的角度分析其底层数学公式来解释不同的注意力模式。TAPPA加深了对注意力行为的理解,并指导推理加速方法。具体来说,TAPPA将注意力模式描述为具有清晰规律的可预测模式和表现出有效随机性的不可预测模式。我们的分析进一步表明,这种区别可以通过查询沿时间维度的自相似程度来解释。着眼于可预测的模式,我们通过查询、键和旋转位置嵌入(RoPE)的联合效应,对三个代表性案例进行了详细的数学分析。我们通过将TAPPA的见解应用于KV缓存压缩和LLM剪枝任务来验证TAPPA。在这些任务中,由TAPPA驱动的简单指标始终优于基线方法。
🔬 方法详解
问题定义:现有研究对大型语言模型中各种注意力模式(如检索头、sink头、对角线轨迹等)的理解是孤立的,缺乏一个统一的理论框架来解释这些现象。这阻碍了我们对注意力机制的深入理解,也限制了我们设计更有效的模型压缩和加速方法。现有方法难以区分不同注意力模式的本质差异,无法针对性地进行优化。
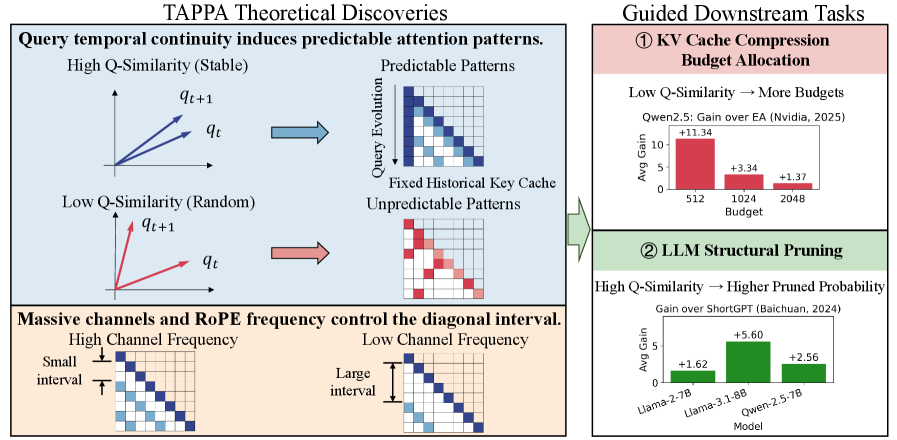
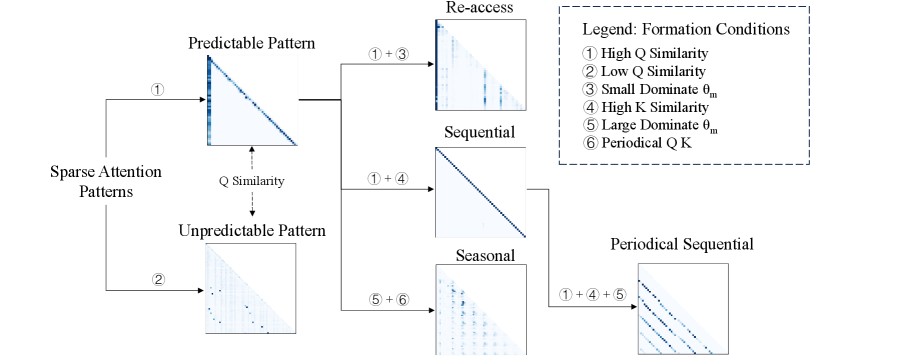
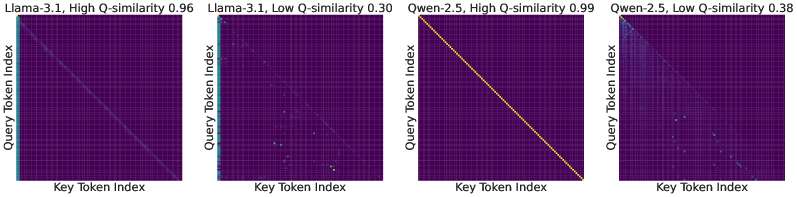
核心思路:论文的核心思路是从时间连续性的角度分析注意力模式。通过分析查询向量在时间维度上的自相似性,将注意力模式分为可预测模式和不可预测模式。可预测模式具有清晰的规律性,而不可预测模式则表现出随机性。这种区分能够帮助我们理解不同注意力模式的本质,并指导我们针对可预测模式进行优化。
技术框架:TAPPA框架主要包含以下几个步骤:1) 对注意力模式进行数学建模,从时间连续性的角度描述注意力计算过程。2) 分析查询向量在时间维度上的自相似性,并基于此将注意力模式分为可预测模式和不可预测模式。3) 对可预测模式进行详细的数学分析,揭示查询、键和旋转位置嵌入(RoPE)之间的相互作用。4) 基于TAPPA的分析结果,设计针对性的模型压缩和加速方法。
关键创新:论文的关键创新在于提出了TAPPA框架,首次从时间连续性的角度统一解释了LLM中各种注意力模式。通过分析查询向量的自相似性,将注意力模式分为可预测模式和不可预测模式,为理解注意力机制提供了新的视角。此外,论文还深入分析了可预测模式的数学特性,为模型压缩和加速提供了理论指导。
关键设计:论文的关键设计包括:1) 使用旋转位置嵌入(RoPE)来建模位置信息,并分析RoPE对注意力模式的影响。2) 定义了查询向量的自相似性度量,用于区分可预测模式和不可预测模式。3) 基于TAPPA的分析结果,设计了一种简单的指标来指导KV缓存压缩和LLM剪枝任务。该指标能够有效地识别冗余的注意力头,从而实现模型压缩和加速。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了TAPPA框架的有效性。在KV缓存压缩任务中,基于TAPPA的指标能够显著提高压缩率,同时保持模型性能。在LLM剪枝任务中,基于TAPPA的指标能够更准确地识别冗余的注意力头,从而在保证模型性能的前提下,实现更高的剪枝率。具体性能提升数据未明确给出,但强调了TAPPA驱动的指标始终优于基线方法。
🎯 应用场景
该研究成果可应用于大型语言模型的压缩和加速,降低模型部署的计算成本和内存需求。通过识别和去除冗余的注意力头,可以减小模型尺寸,提高推理速度,从而使LLM能够在资源受限的设备上运行。此外,该研究也有助于我们更深入地理解注意力机制的本质,为未来设计更高效的LLM架构提供理论指导。
📄 摘要(原文)
Attention patterns play a crucial role in both training and inference of large language models (LLMs). Prior works have identified individual patterns such as retrieval heads, sink heads, and diagonal traces, yet these observations remain fragmented and lack a unifying explanation. To bridge this gap, we introduce \textbf{Temporal Attention Pattern Predictability Analysis (TAPPA), a unifying framework that explains diverse attention patterns by analyzing their underlying mathematical formulations} from a temporally continuous perspective. TAPPA both deepens the understanding of attention behavior and guides inference acceleration approaches. Specifically, TAPPA characterizes attention patterns as predictable patterns with clear regularities and unpredictable patterns that appear effectively random. Our analysis further reveals that this distinction can be explained by the degree of query self-similarity along the temporal dimension. Focusing on the predictable patterns, we further provide a detailed mathematical analysis of three representative cases through the joint effect of queries, keys, and Rotary Positional Embeddings (RoPE). We validate TAPPA by applying its insights to KV cache compression and LLM pruning tasks. Across these tasks, a simple metric motivated by TAPPA consistently improves performance over baseline methods. The code is available at https://github.com/MIRALab-USTC/LLM-TAPPA.