FIT: Defying Catastrophic Forgetting in Continual LLM Unlearning
作者: Xiaoyu Xu, Minxin Du, Kun Fang, Zi Liang, Yaxin Xiao, Zhicong Huang, Cheng Hong, Qingqing Ye, Haibo Hu
分类: cs.CL, cs.AI, cs.CR, cs.LG
发布日期: 2026-01-29
备注: 20 Pages
💡 一句话要点
FIT框架:应对LLM持续卸载中的灾难性遗忘问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 持续学习 信息卸载 灾难性遗忘 隐私保护
📋 核心要点
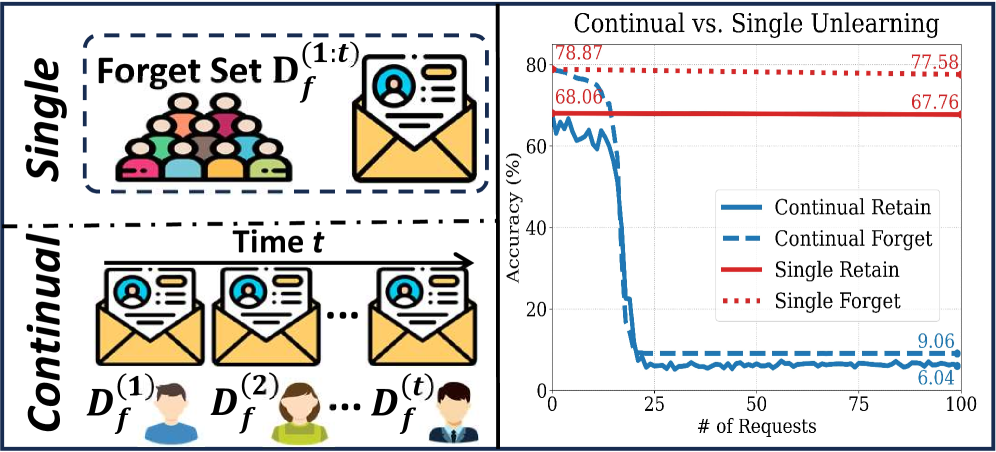
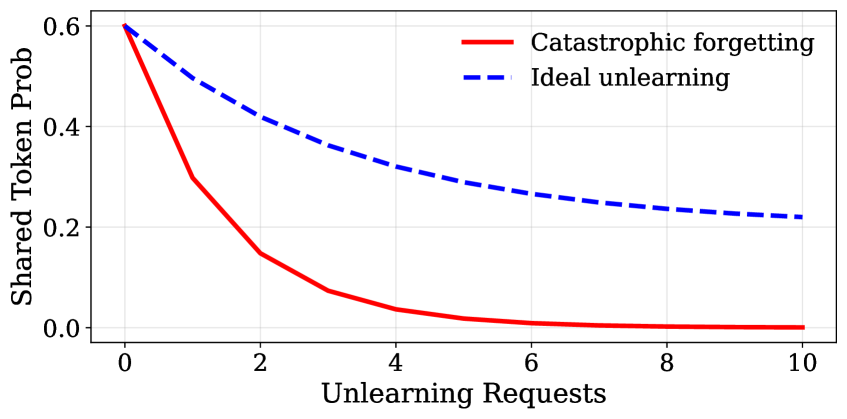
- 现有LLM卸载方法难以应对持续高量的删除请求,导致模型性能下降和灾难性遗忘。
- FIT框架通过数据过滤、重要性感知更新和目标层属性,实现持续卸载过程中的稳定性能。
- 实验表明,FIT在遗忘度与效用保持间取得最佳平衡,并在多个基准测试中超越现有方法。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出令人印象深刻的能力,但也引发了对隐私、版权和有害材料的担忧。现有的LLM卸载方法很少考虑现实世界删除请求的持续性和高容量特性,这可能导致效用降低和灾难性遗忘,因为请求会不断累积。为了应对这一挑战,我们提出了 it,一个用于持续卸载的框架,它可以处理大量的删除请求,同时保持对灾难性遗忘和卸载后恢复的鲁棒性。 it通过严格的数据过滤、重要性感知更新和目标层属性来减轻性能下降,从而在长时间的卸载操作序列中实现稳定的性能,并在遗忘有效性和效用保持之间取得良好的平衡。为了支持现实的评估,我们提出了 extbf{PCH},一个涵盖顺序删除场景中 extbf{P}ersonal信息、 extbf{C}opyright和 extbf{H}armful内容的基准,以及两个对称的指标,遗忘度(F.D.)和保留效用(R.U.),它们共同评估遗忘质量和效用保持。在具有数百个删除请求的四个开源LLM上的大量实验表明, it在F.D.和R.U.之间实现了最强的权衡,在MMLU、CommonsenseQA和GSM8K上超过了现有方法,并且对重新学习和量化恢复攻击具有抵抗力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在持续接收大量删除请求时,出现的灾难性遗忘和模型效用下降问题。现有的卸载方法无法很好地处理这种持续性和高容量的删除请求,导致模型在遗忘特定信息的同时,也损失了通用能力。
核心思路:论文的核心思路是通过精细化的数据管理和模型更新策略,在持续卸载过程中保持模型的性能。具体来说,通过过滤不相关数据减少干扰,根据数据重要性调整更新幅度,并针对性地调整模型特定层,从而在遗忘目标信息的同时,尽可能保留模型的通用知识。
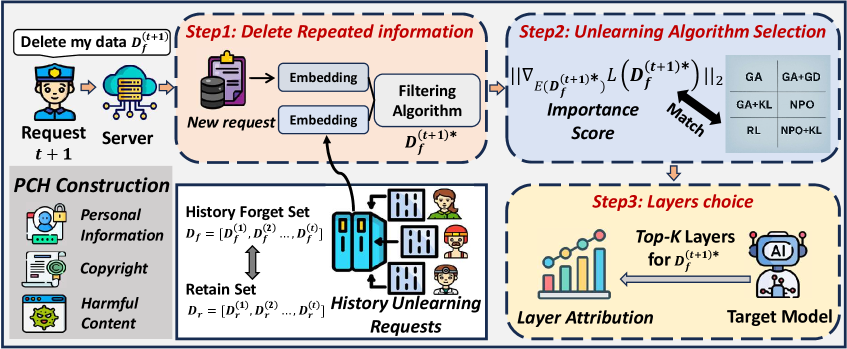
技术框架:FIT框架包含三个主要模块:数据过滤(Filtering)、重要性感知更新(Importance-aware updates)和目标层属性(Targeted layer attribution)。首先,数据过滤模块筛选出与删除请求高度相关的数据,减少无关数据对卸载过程的干扰。然后,重要性感知更新模块根据数据对模型的重要性,调整更新的幅度,避免过度更新导致灾难性遗忘。最后,目标层属性模块识别对特定信息影响最大的模型层,并针对性地进行调整,以实现更精确的卸载。
关键创新:FIT框架的关键创新在于其综合考虑了数据、参数和模型结构三个层面的因素,实现了精细化的持续卸载。与现有方法相比,FIT不仅关注如何遗忘特定信息,更关注如何在遗忘的同时保持模型的通用能力。这种综合性的方法使得FIT在持续卸载场景下表现出更强的鲁棒性和更好的性能。
关键设计:数据过滤模块可能使用相似度计算等方法,筛选出与删除请求相关的数据。重要性感知更新模块可能使用梯度信息或注意力权重来评估数据的重要性,并据此调整学习率。目标层属性模块可能使用敏感性分析等方法,识别对特定信息影响最大的模型层。具体的损失函数和网络结构细节可能根据不同的LLM架构进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FIT框架在四个开源LLM上实现了遗忘度(F.D.)和保留效用(R.U.)之间的最佳平衡。在MMLU、CommonsenseQA和GSM8K等基准测试中,FIT超越了现有方法,并且对重新学习和量化恢复攻击具有抵抗力。这些结果表明FIT在实际应用中具有很强的实用价值。
🎯 应用场景
该研究成果可应用于需要持续处理用户数据删除请求的在线服务,例如社交媒体平台、搜索引擎和内容创作平台。通过FIT框架,这些平台可以更有效地响应用户的删除请求,同时保持其LLM的性能和可用性,从而提升用户隐私保护水平并增强用户信任。
📄 摘要(原文)
Large language models (LLMs) demonstrate impressive capabilities across diverse tasks but raise concerns about privacy, copyright, and harmful materials. Existing LLM unlearning methods rarely consider the continual and high-volume nature of real-world deletion requests, which can cause utility degradation and catastrophic forgetting as requests accumulate. To address this challenge, we introduce \fit, a framework for continual unlearning that handles large numbers of deletion requests while maintaining robustness against both catastrophic forgetting and post-unlearning recovery. \fit mitigates degradation through rigorous data \underline{F}iltering, \underline{I}mportance-aware updates, and \underline{T}argeted layer attribution, enabling stable performance across long sequences of unlearning operations and achieving a favorable balance between forgetting effectiveness and utility retention. To support realistic evaluation, we present \textbf{PCH}, a benchmark covering \textbf{P}ersonal information, \textbf{C}opyright, and \textbf{H}armful content in sequential deletion scenarios, along with two symmetric metrics, Forget Degree (F.D.) and Retain Utility (R.U.), which jointly assess forgetting quality and utility preservation. Extensive experiments on four open-source LLMs with hundreds of deletion requests show that \fit achieves the strongest trade-off between F.D. and R.U., surpasses existing methods on MMLU, CommonsenseQA, and GSM8K, and remains resistant against both relearning and quantization recovery attacks.