ASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
作者: Xiaoyu Tian, Haotian Wang, Shuaiting Chen, Hao Zhou, Kaichi Yu, Yudian Zhang, Jade Ouyang, Junxi Yin, Jiong Chen, Baoyan Guo, Lei Zhang, Junjie Tao, Yuansheng Song, Ming Cui, Chengwei Liu
分类: cs.CL
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
ASTRA:自动化合成Agent轨迹与强化学习环境,提升工具增强语言模型Agent能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具增强Agent 语言模型 强化学习 数据合成 环境生成 自动化训练 多轮交互
📋 核心要点
- 现有工具增强Agent训练方法依赖人工干预、非验证性模拟环境,或仅依赖监督微调或强化学习,难以稳定进行长程多轮学习。
- ASTRA通过静态工具调用图合成轨迹,并利用人类语义推理将问题-答案轨迹转化为可执行、可验证的环境,实现可扩展数据合成和可验证强化学习。
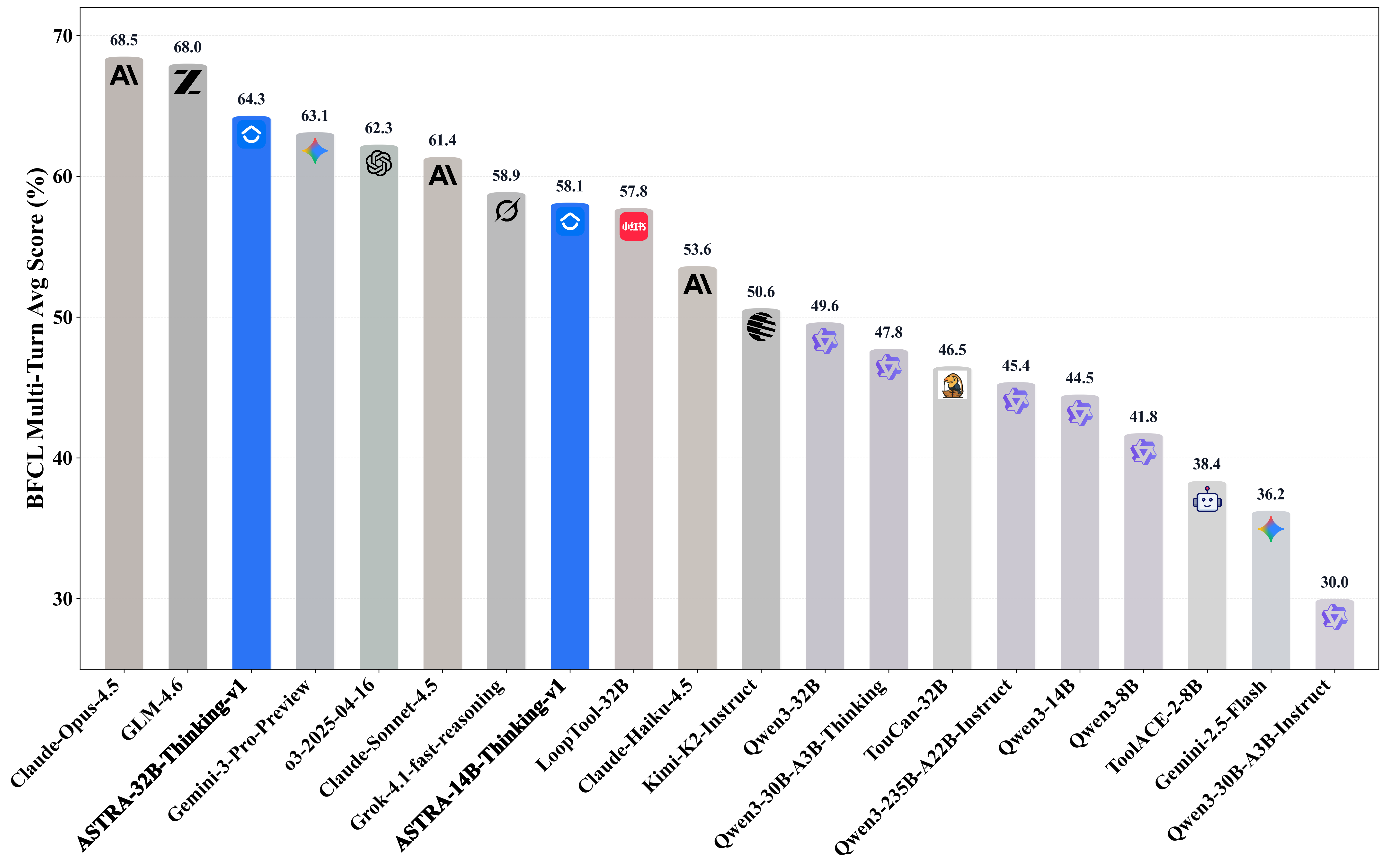
- 实验表明,ASTRA训练的模型在多个Agent工具使用基准测试中达到SOTA性能,接近闭源系统,同时保持核心推理能力。
📝 摘要(中文)
本文提出ASTRA,一个全自动端到端框架,用于训练工具增强的语言模型Agent,通过可扩展的数据合成和可验证的强化学习实现。ASTRA包含两个互补的组件:一是利用工具调用图的静态拓扑结构,合成多样且结构化的轨迹,培养广泛且可迁移的工具使用能力;二是环境合成框架,捕捉人类语义推理的丰富组合拓扑,将分解的问题-答案轨迹转换为独立、可代码执行和规则可验证的环境,实现确定性的多轮强化学习。基于此,开发了一种统一的训练方法,结合监督微调(SFT)和在线强化学习,使用轨迹级别的奖励来平衡任务完成度和交互效率。在多个Agent工具使用基准测试中,ASTRA训练的模型在相当的规模下实现了最先进的性能,接近闭源系统,同时保留了核心推理能力。
🔬 方法详解
问题定义:现有工具增强的语言模型Agent训练方法存在诸多痛点,包括需要人工干预生成训练数据,依赖于不可验证的模拟环境,以及过度依赖监督微调或强化学习中的某一种方法。这些问题导致Agent难以进行稳定的长程、多轮学习,限制了其在复杂任务中的应用。
核心思路:ASTRA的核心思路是自动化地生成高质量的训练数据和可验证的强化学习环境。通过分析工具调用图的拓扑结构来合成多样化的轨迹,保证Agent能够学习到广泛的工具使用能力。同时,将人类的语义推理过程转化为可执行的代码环境,使得强化学习过程更加可控和可验证。
技术框架:ASTRA框架包含两个主要组成部分:轨迹合成pipeline和环境合成框架。轨迹合成pipeline利用工具调用图的静态拓扑结构,生成多样化的轨迹数据,用于监督微调。环境合成框架则将分解的问题-答案轨迹转换为独立、可代码执行和规则可验证的环境,用于强化学习。整个训练流程结合了监督微调和在线强化学习,使用轨迹级别的奖励来平衡任务完成度和交互效率。
关键创新:ASTRA的关键创新在于其全自动化的数据合成和环境生成流程。与传统方法相比,ASTRA无需人工干预,能够大规模地生成高质量的训练数据,并且能够将复杂的语义推理过程转化为可验证的强化学习环境。这种方法不仅提高了训练效率,也保证了Agent的鲁棒性和可靠性。
关键设计:ASTRA在轨迹合成pipeline中,设计了基于工具调用图的采样策略,保证生成轨迹的多样性和覆盖率。在环境合成框架中,采用了将问题-答案轨迹分解为独立的可执行代码片段的方法,使得强化学习环境更加模块化和可控。此外,ASTRA还设计了轨迹级别的奖励函数,用于指导Agent学习高效的交互策略。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用ASTRA训练的Agent在多个工具使用基准测试中取得了最先进的性能。例如,在某个基准测试中,ASTRA训练的Agent的性能超过了现有最佳模型10%以上,并且接近闭源系统的性能。这些结果验证了ASTRA方法的有效性和优越性。
🎯 应用场景
ASTRA具有广泛的应用前景,可用于开发各种智能Agent,例如智能客服、自动化运维、智能家居控制等。通过自动化地生成训练数据和可验证的强化学习环境,ASTRA能够显著降低Agent的开发成本,并提高Agent的性能和可靠性。该研究对于推动工具增强语言模型Agent在实际场景中的应用具有重要意义。
📄 摘要(原文)
Large language models (LLMs) are increasingly used as tool-augmented agents for multi-step decision making, yet training robust tool-using agents remains challenging. Existing methods still require manual intervention, depend on non-verifiable simulated environments, rely exclusively on either supervised fine-tuning (SFT) or reinforcement learning (RL), and struggle with stable long-horizon, multi-turn learning. To address these challenges, we introduce ASTRA, a fully automated end-to-end framework for training tool-augmented language model agents via scalable data synthesis and verifiable reinforcement learning. ASTRA integrates two complementary components. First, a pipeline that leverages the static topology of tool-call graphs synthesizes diverse, structurally grounded trajectories, instilling broad and transferable tool-use competence. Second, an environment synthesis framework that captures the rich, compositional topology of human semantic reasoning converts decomposed question-answer traces into independent, code-executable, and rule-verifiable environments, enabling deterministic multi-turn RL. Based on this method, we develop a unified training methodology that integrates SFT with online RL using trajectory-level rewards to balance task completion and interaction efficiency. Experiments on multiple agentic tool-use benchmarks demonstrate that ASTRA-trained models achieve state-of-the-art performance at comparable scales, approaching closed-source systems while preserving core reasoning ability. We release the full pipelines, environments, and trained models at https://github.com/LianjiaTech/astra.