SOUP: Token-level Single-sample Mix-policy Reinforcement Learning for Large Language Models
作者: Lei Yang, Wei Bi, Chenxi Sun, Renren Jin, Deyi Xiong
分类: cs.CL
发布日期: 2026-01-29
💡 一句话要点
SOUP:用于大语言模型的Token级单样本混合策略强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 策略优化 Off-policy学习 On-policy学习 Token级别 混合策略 语言模型后训练
📋 核心要点
- 现有On-policy强化学习方法在语言模型后训练中存在探索不足和过早饱和的问题,限制了性能提升。
- SOUP框架通过在Token级别混合On-policy和Off-policy数据,在单个样本内实现策略的探索和利用。
- 实验结果表明,SOUP在性能上显著优于传统的On-policy方法和现有的Off-policy扩展方法,提升了LLM的强化学习效果。
📝 摘要(中文)
针对语言模型后训练中常用的On-policy强化学习方法(如GRPO)因采样多样性不足而导致的探索受限和早期饱和问题,本文提出了一种单样本混合策略统一范式(SOUP)。SOUP框架在Token级别统一了Off-policy和On-policy学习。它将Off-policy的影响限制在从历史策略采样的生成序列的前缀部分,而延续部分则采用On-policy生成。通过Token级别的重要性比率,SOUP有效地利用了Off-policy信息,同时保持了训练的稳定性。大量实验表明,SOUP始终优于标准的On-policy训练和现有的Off-policy扩展方法。进一步的分析阐明了SOUP的细粒度、单样本混合策略训练如何改善LLM强化学习中的探索和最终性能。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)通过强化学习进行后训练时,On-policy方法因采样多样性不足而导致的探索受限和早期饱和问题。现有方法要么探索不足,要么直接混合整个轨迹,导致策略不匹配和训练不稳定。
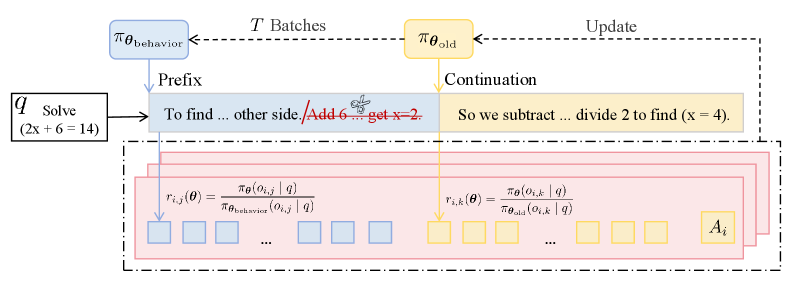
核心思路:SOUP的核心思路是在Token级别混合On-policy和Off-policy数据,即对于一个生成的序列,其前缀部分由Off-policy生成(利用历史策略的经验),而剩余部分由On-policy生成(保证策略的及时更新)。这种混合方式既能利用Off-policy数据进行更广泛的探索,又能避免直接混合整个轨迹带来的策略不匹配问题。
技术框架:SOUP框架的主要流程如下:1) 从历史策略中采样生成序列的前缀;2) 使用当前策略生成序列的剩余部分;3) 计算Token级别的重要性比率,用于调整Off-policy数据的影响;4) 使用混合的On-policy和Off-policy数据进行策略更新。整体架构是一个统一的框架,能够在单个样本内实现On-policy和Off-policy的混合。
关键创新:SOUP的关键创新在于Token级别的单样本混合策略。与传统的On-policy方法相比,SOUP引入了Off-policy数据进行更广泛的探索。与现有的Off-policy扩展方法相比,SOUP避免了直接混合整个轨迹带来的策略不匹配问题,从而提高了训练的稳定性。
关键设计:SOUP的关键设计包括:1) Token级别的重要性比率计算,用于调整Off-policy数据的影响,避免策略偏差;2) 前缀长度的选择,需要在探索和策略匹配之间进行权衡;3) 损失函数的设计,需要同时考虑On-policy和Off-policy数据的贡献,以实现稳定的策略更新。
🖼️ 关键图片
📊 实验亮点
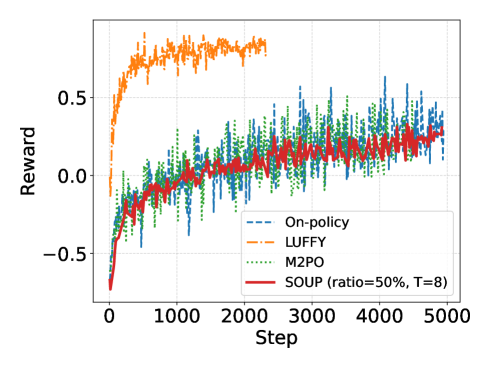
实验结果表明,SOUP在多个任务上均优于标准的On-policy训练和现有的Off-policy扩展方法。具体而言,SOUP在奖励指标上取得了显著提升,并且在生成文本的多样性和流畅性方面也表现更好。这些结果验证了SOUP在LLM强化学习中的有效性。
🎯 应用场景
SOUP方法可应用于各种需要通过强化学习进行后训练的大语言模型,例如对话生成、文本摘要、代码生成等。该方法能够提升模型的生成质量、多样性和对齐程度,具有广泛的应用前景和实际价值。未来,SOUP可以进一步扩展到其他序列生成任务和模型架构中。
📄 摘要(原文)
On-policy reinforcement learning (RL) methods widely used for language model post-training, like Group Relative Policy Optimization (GRPO), often suffer from limited exploration and early saturation due to low sampling diversity. While off-policy data can help, current approaches that mix entire trajectories cause significant policy mismatch and instability. In this work, we propose the $\textbf{S}$ingle-sample Mix-p$\textbf{O}$licy $\textbf{U}$nified $\textbf{P}$aradigm (SOUP), a framework that unifies off- and on-policy learning within individual samples at the token level. It confines off-policy influence to the prefix of a generated sequence sampled from historical policies, while the continuation is generated on-policy. Through token-level importance ratios, SOUP effectively leverages off-policy information while preserving training stability. Extensive experiments demonstrate that SOUP consistently outperforms standard on-policy training and existing off-policy extensions. Our further analysis clarifies how our fine-grained, single-sample mix-policy training can improve both exploration and final performance in LLM RL.