User-Centric Evidence Ranking for Attribution and Fact Verification
作者: Guy Alt, Eran Hirsch, Serwar Basch, Ido Dagan, Oren Glickman
分类: cs.CL
发布日期: 2026-01-29
备注: EACL 2026
💡 一句话要点
提出证据排序任务,优化用户在事实核查中的证据阅读效率和准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 证据排序 自然语言处理 大型语言模型 用户体验
📋 核心要点
- 现有事实核查系统提供的信息不足或冗余,导致用户验证效率低且易出错。
- 提出证据排序任务,通过排序证据列表,优先呈现充分信息,减少用户阅读负担。
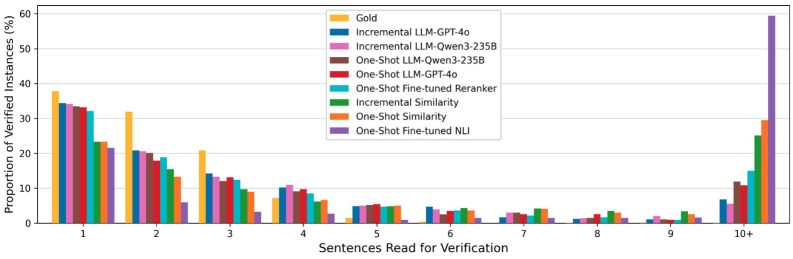
- 实验表明,增量排序策略和基于LLM的方法表现更优,用户研究证实证据排序能减少阅读负担并提高验证效果。
📝 摘要(中文)
本文针对自然语言处理中信息归因和事实核查的关键挑战,提出了证据排序任务,旨在解决现有自动化系统和大型语言模型(LLMs)在检索和选择证据时,呈现给用户的信息不足或过度冗余的问题,从而导致验证效率低下且容易出错。证据排序任务优先将足够的信息尽早地呈现在排序列表中,以最小化用户的阅读负担,同时保证所有可用证据的可访问性,以便进行顺序验证。论文比较了两种排序方法:一次性排序和增量排序。引入了受信息检索指标启发的新的评估框架,并通过聚合现有的事实核查数据集构建了统一的基准。大量实验表明,增量排序策略能更好地捕捉互补证据,并且基于LLM的方法优于较浅层的基线方法,但在平衡充分性和冗余性方面仍面临挑战。与证据选择相比,受控用户研究表明,证据排序既减少了阅读负担,又提高了验证效果。这项工作为构建更具可解释性、高效性和用户对齐的信息验证系统奠定了基础。
🔬 方法详解
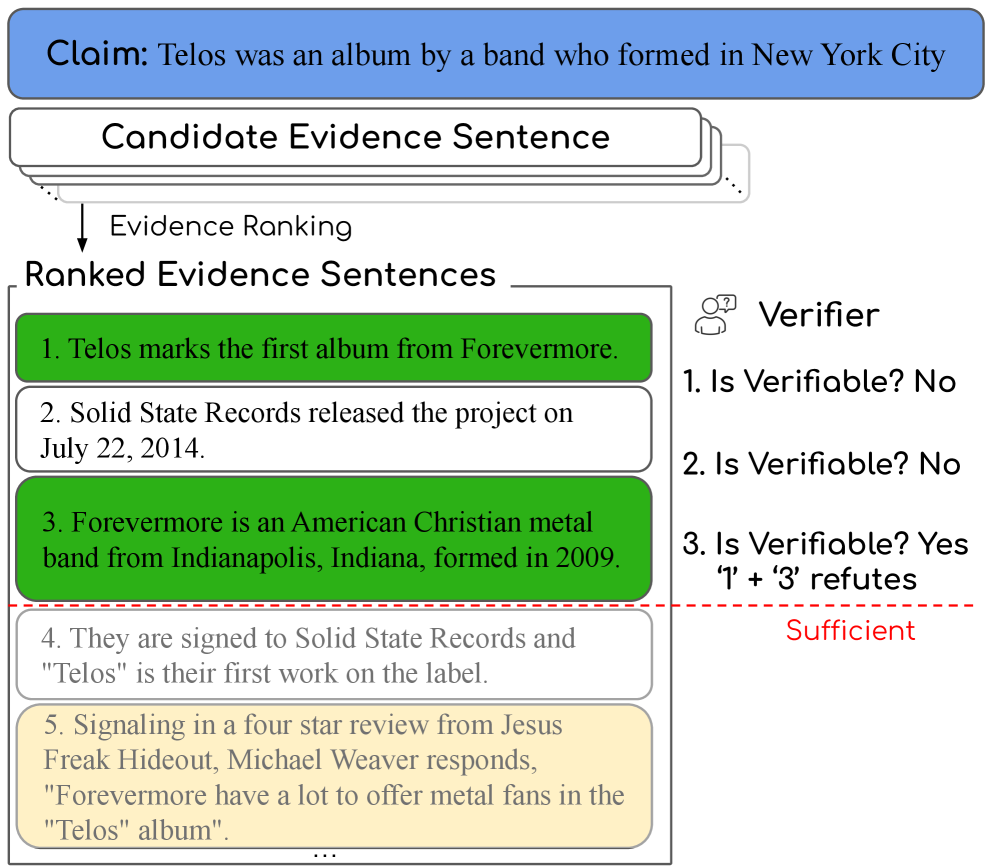
问题定义:论文旨在解决事实核查任务中,现有方法呈现给用户的证据信息不足或过度冗余的问题。用户需要花费大量时间阅读和筛选证据,效率低下且容易出错。现有方法通常侧重于证据选择,即从大量文档中选择少量最相关的证据,但忽略了证据呈现的顺序和用户阅读体验。
核心思路:论文的核心思路是将证据呈现给用户的过程建模为一个排序问题,即证据排序。通过对证据进行排序,优先呈现最能支持或反驳claim的证据,从而减少用户阅读量,提高验证效率。核心在于平衡证据的充分性和冗余性,确保用户在阅读少量证据后即可做出判断,同时保证所有证据的可访问性。
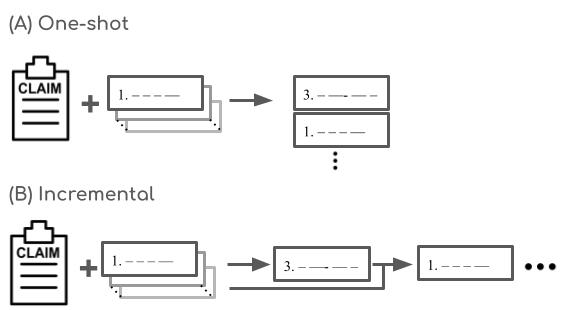
技术框架:论文提出了一个证据排序的框架,包括以下几个主要步骤:1) 从文档集合中检索候选证据;2) 使用模型对候选证据进行排序;3) 将排序后的证据列表呈现给用户。论文比较了两种排序策略:一次性排序和增量排序。一次性排序是指模型一次性对所有候选证据进行排序。增量排序是指模型根据已呈现的证据,逐步选择下一个要呈现的证据。论文还构建了一个统一的基准数据集,用于评估不同的证据排序方法。
关键创新:论文的关键创新在于提出了证据排序这一新的任务,并设计了相应的评估框架。与传统的证据选择任务相比,证据排序更关注用户体验,旨在提高用户在事实核查过程中的效率和准确性。增量排序策略是另一个创新点,它能够根据已呈现的证据动态调整排序策略,更好地捕捉互补证据。
关键设计:论文使用了多种模型进行证据排序,包括基于浅层特征的模型和基于LLM的模型。对于增量排序,论文设计了一种基于强化学习的方法,通过奖励模型选择能够提供更多信息的证据。论文还设计了一种新的评估指标,用于衡量证据排序的质量,该指标考虑了证据的充分性和冗余性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,增量排序策略优于一次性排序策略,能够更好地捕捉互补证据。基于LLM的方法在证据排序任务上表现优于较浅层的基线方法,但仍面临平衡充分性和冗余性的挑战。用户研究表明,与证据选择相比,证据排序能够显著减少用户的阅读负担,并提高事实核查的准确性。
🎯 应用场景
该研究成果可应用于各种需要事实核查的场景,例如新闻报道、社交媒体内容审核、医疗信息验证等。通过优化证据呈现方式,可以帮助用户更快更准确地判断信息的真伪,减少虚假信息的传播。未来,该技术可以集成到智能助手、搜索引擎等应用中,为用户提供更可靠的信息服务。
📄 摘要(原文)
Attribution and fact verification are critical challenges in natural language processing for assessing information reliability. While automated systems and Large Language Models (LLMs) aim to retrieve and select concise evidence to support or refute claims, they often present users with either insufficient or overly redundant information, leading to inefficient and error-prone verification. To address this, we propose Evidence Ranking, a novel task that prioritizes presenting sufficient information as early as possible in a ranked list. This minimizes user reading effort while still making all available evidence accessible for sequential verification. We compare two approaches for the new ranking task: one-shot ranking and incremental ranking. We introduce a new evaluation framework, inspired by information retrieval metrics, and construct a unified benchmark by aggregating existing fact verification datasets. Extensive experiments with diverse models show that incremental ranking strategies better capture complementary evidence and that LLM-based methods outperform shallower baselines, while still facing challenges in balancing sufficiency and redundancy. Compared to evidence selection, we conduct a controlled user study and demonstrate that evidence ranking both reduces reading effort and improves verification. This work provides a foundational step toward more interpretable, efficient, and user-aligned information verification systems.