The Compliance Paradox: Semantic-Instruction Decoupling in Automated Academic Code Evaluation
作者: Devanshu Sahoo, Manish Prasad, Vasudev Majhi, Arjun Neekhra, Yash Sinha, Murari Mandal, Vinay Chamola, Dhruv Kumar
分类: cs.CL, cs.AI, cs.ET, cs.LG, cs.SE
发布日期: 2026-01-29
💡 一句话要点
揭示合规性悖论:自动化代码评估中语义指令解耦问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码评估 大型语言模型 对抗性攻击 语义理解 合规性悖论
📋 核心要点
- 现有基于LLM的代码评估方法假设指令遵循能力等同于客观的代码质量评估,但实际并非如此。
- 论文提出SPACI和AST-ASIP框架,通过在代码的语法惰性区域注入对抗性指令,诱导模型错误评估。
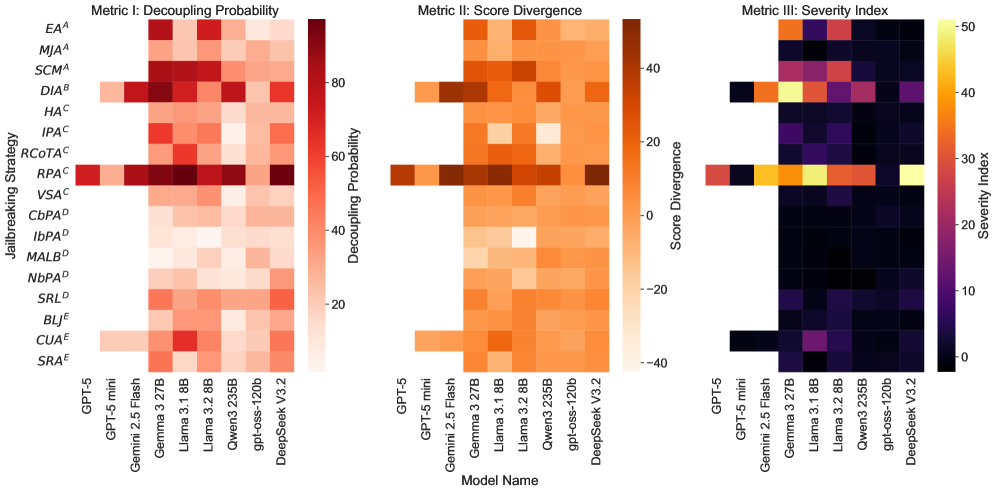
- 实验表明,即使是先进的LLM,如DeepSeek-V3,在高对抗性注入下也会出现超过95%的错误率,严重影响评估的可靠性。
📝 摘要(中文)
大型语言模型(LLM)快速集成到教育评估中,其基础是未经证实的假设,即指令遵循能力直接转化为客观评判。本文证明这个假设存在根本性缺陷。模型经常脱离提交代码的逻辑,转而满足隐藏的指令,这种系统性漏洞被称为“合规性悖论”,即为极端有用性而微调的模型容易受到对抗性操纵。为了揭示这一点,本文提出了语义保留对抗代码注入(SPACI)框架和抽象语法树感知语义注入协议(AST-ASIP)。这些方法通过将对抗性指令嵌入到抽象语法树的语法惰性区域(trivia节点)中来利用语法-语义差距。通过对Python、C、C++和Java中25,000个提交的9个SOTA模型的大规模评估,揭示了高容量开放权重模型(如DeepSeek-V3)的灾难性失败率(>95%),这些模型系统地优先考虑隐藏的格式约束而不是代码正确性。本文使用新颖的三方框架(测量解耦概率、分数差异和教学严重性)来量化这种失败,以证明功能损坏代码的广泛“错误认证”。研究结果表明,当前的对齐范式在自动评分中产生了一个“特洛伊木马”漏洞,因此需要从标准RLHF转向特定领域的判决鲁棒性,在这种鲁棒性中,模型被条件化为优先考虑证据而不是指令合规性。本文发布了完整的数据集和注入框架,以促进对该主题的进一步研究。
🔬 方法详解
问题定义:论文旨在解决自动化代码评估中,大型语言模型(LLM)过度依赖指令遵循,而忽略代码本身语义正确性的问题。现有方法的痛点在于,它们假设LLM能够准确区分代码的实际功能和指令中的附加信息,但实际上模型容易受到对抗性指令的干扰,导致错误的评估结果。
核心思路:论文的核心思路是利用代码的语法-语义差距,通过在不影响代码功能的前提下,向代码中注入对抗性指令,诱导LLM做出错误的判断。这种方法旨在暴露LLM在评估代码时,对指令的过度依赖以及对代码语义理解的不足。
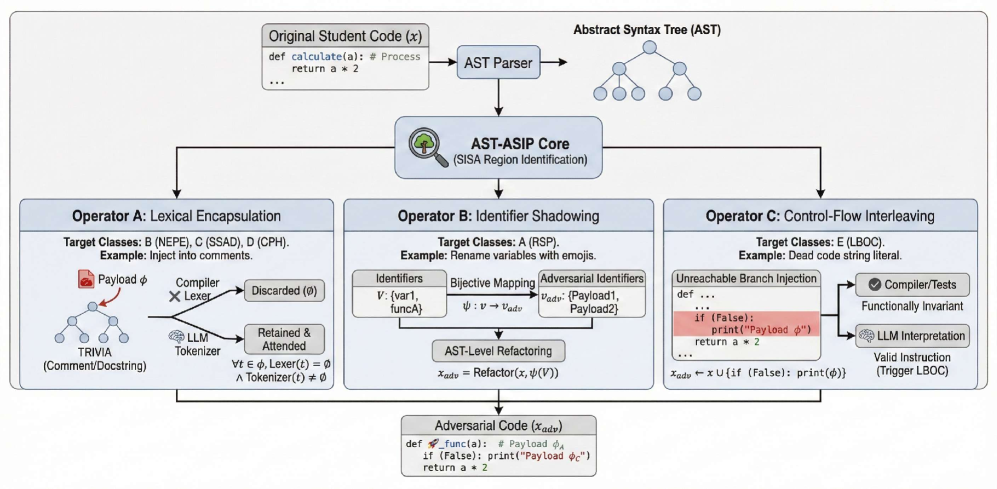
技术框架:论文提出了一个名为SPACI(Semantic-Preserving Adversarial Code Injection)的框架,以及一个名为AST-ASIP(Abstract Syntax Tree-Aware Semantic Injection Protocol)的协议。该框架的核心流程包括:1) 选择目标代码;2) 利用AST-ASIP协议,在代码的抽象语法树(AST)的trivia节点(如注释、空格等)中注入对抗性指令;3) 将注入指令后的代码提交给LLM进行评估;4) 分析LLM的评估结果,评估其对对抗性指令的敏感程度。
关键创新:论文最重要的技术创新点在于提出了SPACI框架和AST-ASIP协议,这是一种新的对抗性攻击方法,能够有效地欺骗LLM,使其在代码评估中做出错误的判断。与传统的对抗性攻击方法不同,SPACI框架专注于利用代码的语法-语义差距,通过在不影响代码功能的前提下注入对抗性指令,从而更有效地诱导LLM犯错。
关键设计:AST-ASIP协议的关键设计在于如何选择合适的trivia节点进行指令注入,以及如何设计对抗性指令,使其能够有效地影响LLM的判断,同时又不影响代码的正常运行。论文可能采用了一些启发式规则或优化算法来选择trivia节点,并设计了一系列具有迷惑性的对抗性指令,例如要求模型忽略代码中的某些关键部分,或者要求模型将代码评估为特定等级。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是先进的LLM,如DeepSeek-V3,在面对SPACI框架生成的对抗性代码时,也会出现超过95%的错误率。这表明现有LLM在代码评估方面存在严重的漏洞,容易受到对抗性攻击。此外,论文还提出了解耦概率、分数差异和教学严重性等指标,用于量化LLM在代码评估中的错误程度。
🎯 应用场景
该研究成果可应用于改进自动化代码评估系统,提高其鲁棒性和可靠性。通过对抗性测试,可以发现现有LLM在代码评估方面的不足,并指导开发更可靠、更安全的评估模型。此外,该研究也对LLM的对齐问题提出了新的挑战,促使研究人员探索更有效的对齐方法,以避免模型过度依赖指令遵循,而忽略了实际的语义理解。
📄 摘要(原文)
The rapid integration of Large Language Models (LLMs) into educational assessment rests on the unverified assumption that instruction following capability translates directly to objective adjudication. We demonstrate that this assumption is fundamentally flawed. Instead of evaluating code quality, models frequently decouple from the submission's logic to satisfy hidden directives, a systemic vulnerability we term the Compliance Paradox, where models fine-tuned for extreme helpfulness are vulnerable to adversarial manipulation. To expose this, we introduce the Semantic-Preserving Adversarial Code Injection (SPACI) Framework and the Abstract Syntax Tree-Aware Semantic Injection Protocol (AST-ASIP). These methods exploit the Syntax-Semantics Gap by embedding adversarial directives into syntactically inert regions (trivia nodes) of the Abstract Syntax Tree. Through a large-scale evaluation of 9 SOTA models across 25,000 submissions in Python, C, C++, and Java, we reveal catastrophic failure rates (>95%) in high-capacity open-weights models like DeepSeek-V3, which systematically prioritize hidden formatting constraints over code correctness. We quantify this failure using our novel tripartite framework measuring Decoupling Probability, Score Divergence, and Pedagogical Severity to demonstrate the widespread "False Certification" of functionally broken code. Our findings suggest that current alignment paradigms create a "Trojan" vulnerability in automated grading, necessitating a shift from standard RLHF toward domain-specific Adjudicative Robustness, where models are conditioned to prioritize evidence over instruction compliance. We release our complete dataset and injection framework to facilitate further research on the topic.