Self-Improving Pretraining: using post-trained models to pretrain better models
作者: Ellen Xiaoqing Tan, Shehzaad Dhuliawala, Jing Xu, Ping Yu, Sainbayar Sukhbaatar, Jason Weston, Olga Golovneva
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出自提升预训练方法,利用后训练模型指导预训练,提升大语言模型的安全性、事实性和生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自提升预训练 强化学习 后训练模型 安全性 事实性 大语言模型 文本生成
📋 核心要点
- 现有大语言模型依赖昂贵的数据集和多阶段微调来保证生成内容的安全性、事实性和质量,但无法完全纠正预训练阶段的偏差。
- 提出一种自提升预训练方法,利用强化学习和后训练模型来指导预训练过程,从而从根本上提升模型的质量和安全性。
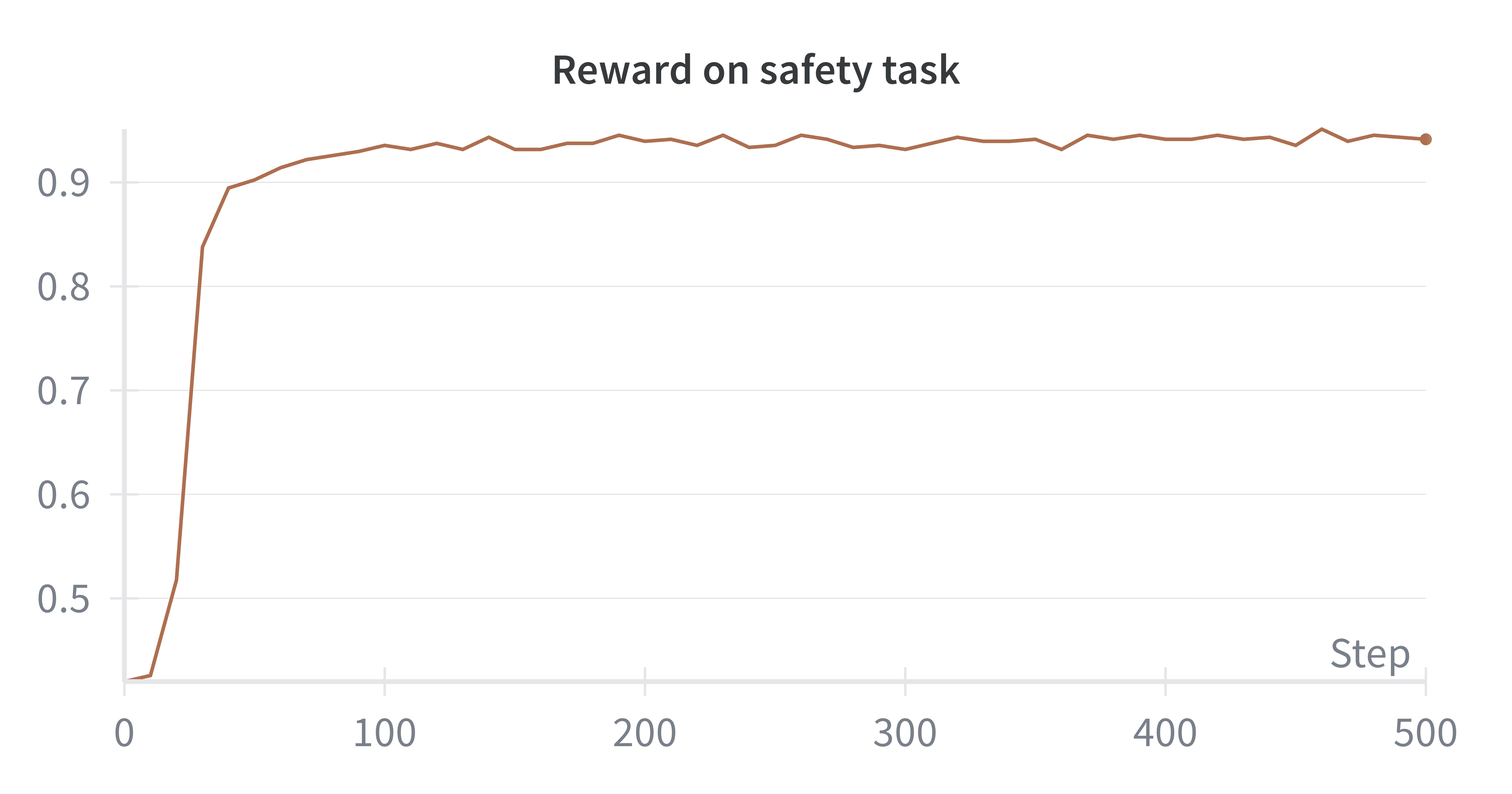
- 实验结果表明,该方法在事实性和安全性方面显著优于标准预训练,并且在整体生成质量方面也取得了显著提升。
📝 摘要(中文)
大型语言模型生成内容的安全性、事实性和整体质量是关键挑战,尤其是在这些模型日益部署于实际应用中时。目前解决这些问题的方法通常是收集昂贵且精心策划的数据集,并应用多个阶段的微调和对齐。然而,即使是这种复杂的流程也无法保证纠正预训练期间学习到的模式。因此,在预训练阶段解决这些问题至关重要,因为它塑造了模型的核心行为,并防止不安全或虚构的输出变得根深蒂固。为了解决这个问题,我们提出了一种新的预训练方法,该方法流式传输文档,并使用强化学习(RL)来改进每一步生成的下K个token。一个强大的后训练模型会评估候选生成结果(包括模型rollout、原始后缀和重写后缀)的质量、安全性和事实性。在训练初期,该过程依赖于原始和重写的后缀;随着模型的改进,RL会奖励高质量的rollout。这种方法从根本上构建更高质量、更安全、更真实的模型。在实验中,我们的方法在事实性和安全性方面比标准预训练分别提高了36.2%和18.5%,在整体生成质量方面提高了高达86.3%的胜率。
🔬 方法详解
问题定义:现有大语言模型在预训练阶段容易学习到不安全或不真实的模式,导致生成内容存在安全隐患和事实性错误。传统的微调和对齐方法难以完全消除这些预训练阶段引入的偏差。因此,需要在预训练阶段就解决这些问题,从根本上提升模型的质量。
核心思路:核心思路是利用一个强大的后训练模型作为裁判,评估预训练过程中生成的文本片段的质量、安全性和事实性,并使用强化学习来优化生成过程。通过这种方式,模型可以在预训练阶段就学习到生成高质量、安全和真实的文本。
技术框架:该方法采用流式文档预训练,在每一步生成K个token时,使用强化学习来优化生成过程。具体流程如下:1) 模型生成多个候选文本片段,包括模型自身的rollout、原始后缀和重写后缀。2) 一个后训练模型对这些候选文本片段进行评估,给出质量、安全性和事实性评分。3) 使用强化学习算法,根据后训练模型的评分来调整模型的生成策略,奖励高质量的生成结果。
关键创新:关键创新在于将后训练模型和强化学习相结合,用于指导预训练过程。传统的预训练方法通常只关注语言模型的困惑度,而忽略了生成内容的质量、安全性和事实性。该方法通过引入后训练模型作为外部反馈,可以有效地提升预训练模型的这些关键指标。
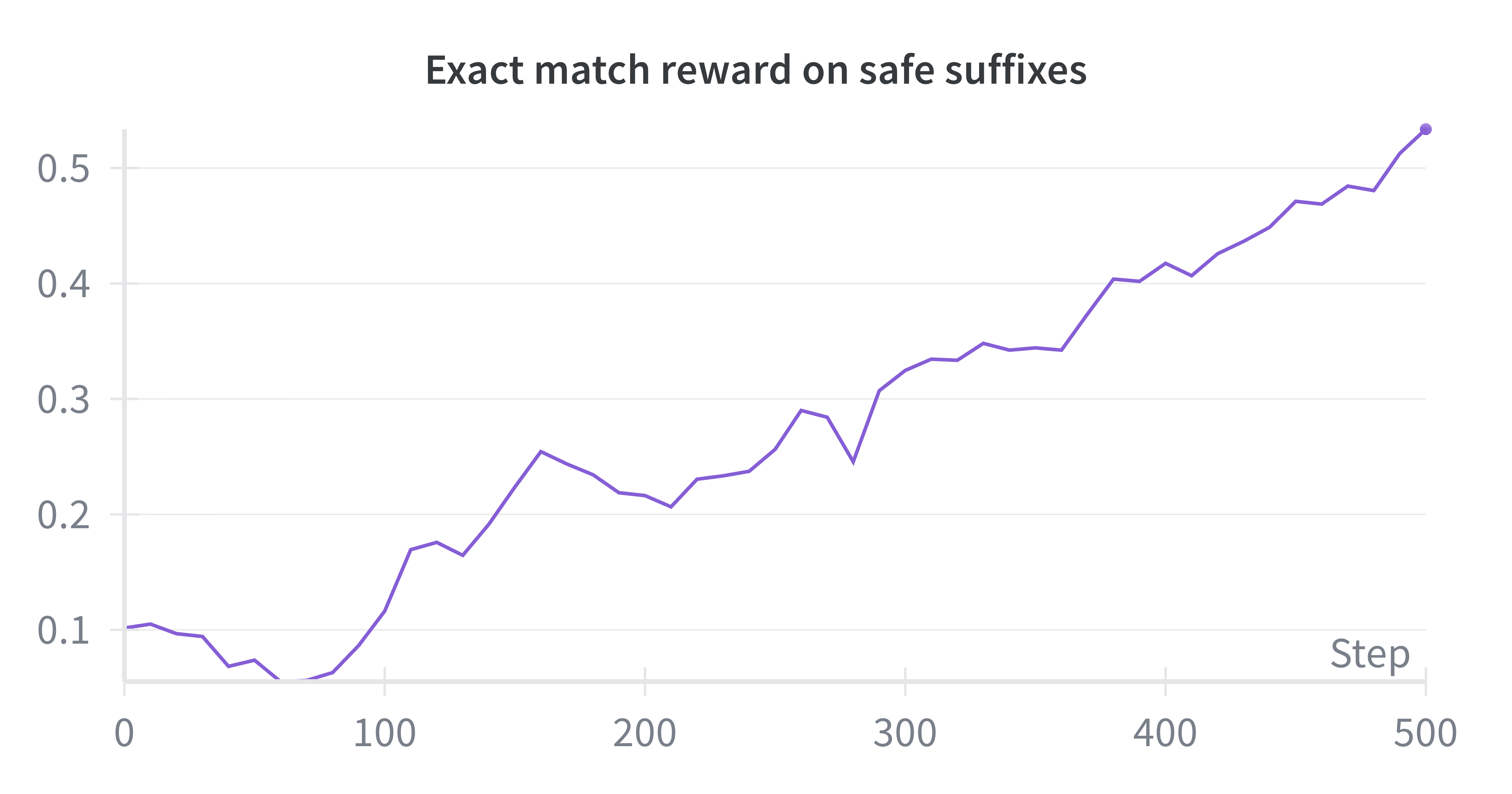
关键设计:在训练初期,主要依赖原始后缀和重写后缀来提供监督信号。随着模型的不断改进,逐渐增加模型自身rollout的权重。强化学习算法使用后训练模型的评分作为奖励信号,优化模型的生成策略。具体参数设置和损失函数细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在事实性和安全性方面比标准预训练分别提高了36.2%和18.5%,并且在整体生成质量方面取得了高达86.3%的胜率提升。这些数据表明,该方法能够有效地提升预训练模型的质量,使其在各项指标上都优于传统的预训练方法。
🎯 应用场景
该研究成果可应用于各种需要高质量、安全和真实的文本生成场景,例如智能客服、内容创作、教育辅导等。通过提升预训练模型的质量,可以减少后续微调和对齐的成本,并提高最终产品的可靠性和安全性。该方法还有助于构建更加值得信赖和负责任的人工智能系统。
📄 摘要(原文)
Ensuring safety, factuality and overall quality in the generations of large language models is a critical challenge, especially as these models are increasingly deployed in real-world applications. The prevailing approach to addressing these issues involves collecting expensive, carefully curated datasets and applying multiple stages of fine-tuning and alignment. However, even this complex pipeline cannot guarantee the correction of patterns learned during pretraining. Therefore, addressing these issues during pretraining is crucial, as it shapes a model's core behaviors and prevents unsafe or hallucinated outputs from becoming deeply embedded. To tackle this issue, we introduce a new pretraining method that streams documents and uses reinforcement learning (RL) to improve the next K generated tokens at each step. A strong, post-trained model judges candidate generations -- including model rollouts, the original suffix, and a rewritten suffix -- for quality, safety, and factuality. Early in training, the process relies on the original and rewritten suffixes; as the model improves, RL rewards high-quality rollouts. This approach builds higher quality, safer, and more factual models from the ground up. In experiments, our method gives 36.2% and 18.5% relative improvements over standard pretraining in terms of factuality and safety, and up to 86.3% win rate improvements in overall generation quality.