CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
作者: Jiahao Huo, Yu Huang, Yibo Yan, Ye Pan, Yi Cao, Mingdong Ou, Philip S. Yu, Xuming Hu
分类: cs.CL
发布日期: 2026-01-29
备注: Under review
💡 一句话要点
CausalEmbed:面向视觉文档嵌入的隐空间自回归多向量生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文档检索 多模态学习 自回归生成模型 对比学习 文档嵌入 隐空间表示 边际损失
📋 核心要点
- 现有MLLM在视觉文档检索中表现出色,但其高存储开销限制了实际应用。
- CausalEmbed采用自回归生成方法,结合迭代边际损失,学习紧凑的文档表示。
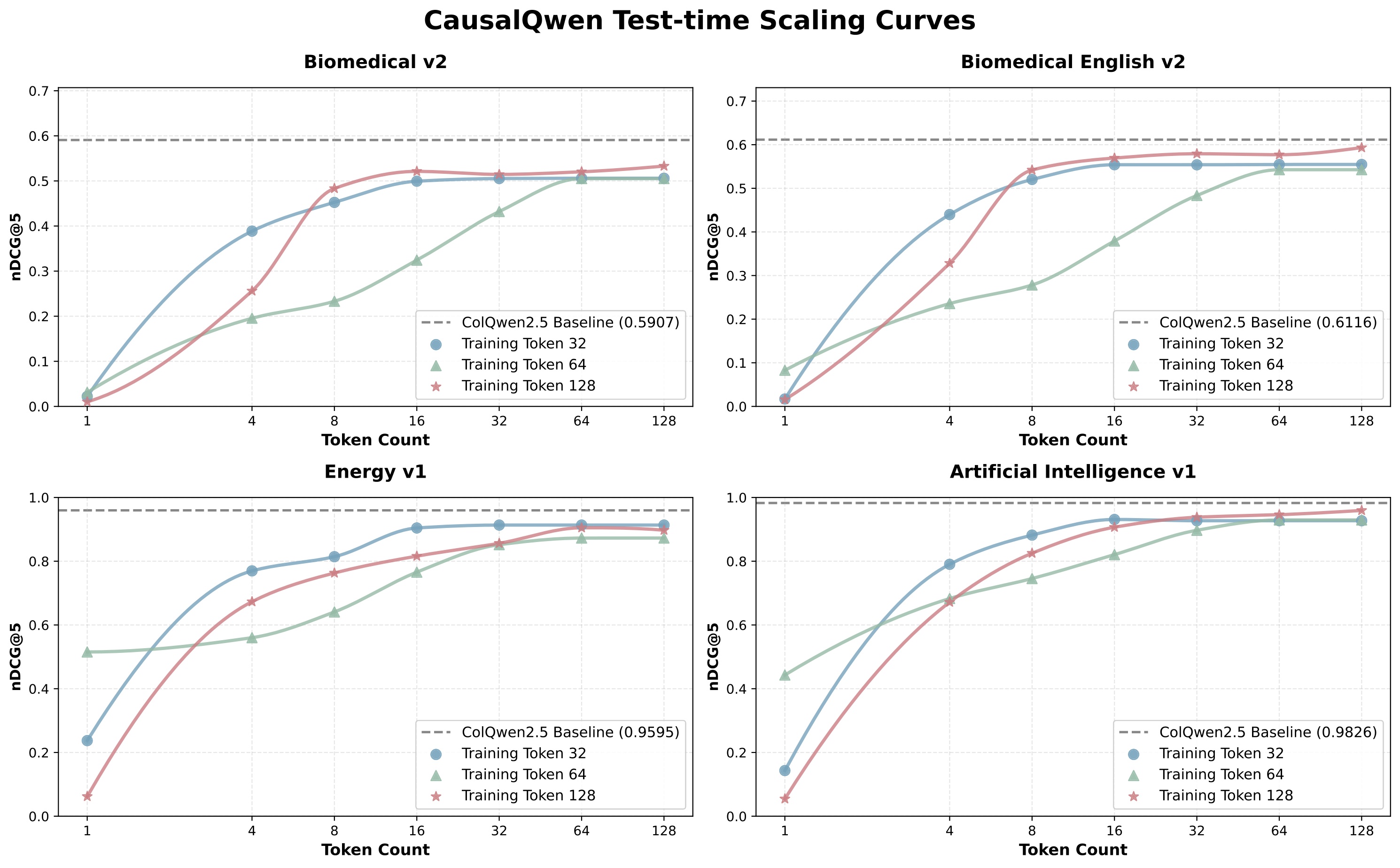
- 实验表明,CausalEmbed显著减少了token数量,同时保持了竞争力的检索性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉文档检索(VDR)中通过生成高质量的多向量嵌入展现了卓越的潜力,但用数千个视觉token表示一个页面导致了巨大的存储开销,限制了它们在实际应用中的可行性。为了解决这个挑战,我们提出了一种自回归生成方法CausalEmbed,用于构建多向量嵌入。通过在对比训练中加入迭代边际损失,CausalEmbed鼓励嵌入模型学习紧凑且结构良好的表示。我们的方法仅使用几十个视觉token就能实现高效的VDR任务,在各种骨干网络和基准测试中实现了30-155倍的token数量减少,同时保持了极具竞争力的性能。理论分析和实验结果证明了自回归嵌入生成在训练效率和测试时可扩展性方面的独特优势。因此,CausalEmbed为多向量VDR表示引入了一种灵活的测试时缩放策略,并揭示了多模态文档检索中的生成范式。
🔬 方法详解
问题定义:论文旨在解决视觉文档检索中,使用多模态大语言模型生成高质量多向量嵌入时,由于视觉token数量巨大而导致的存储开销问题。现有方法直接使用大量视觉token表示文档,导致存储和计算成本过高,限制了其在实际场景中的应用。
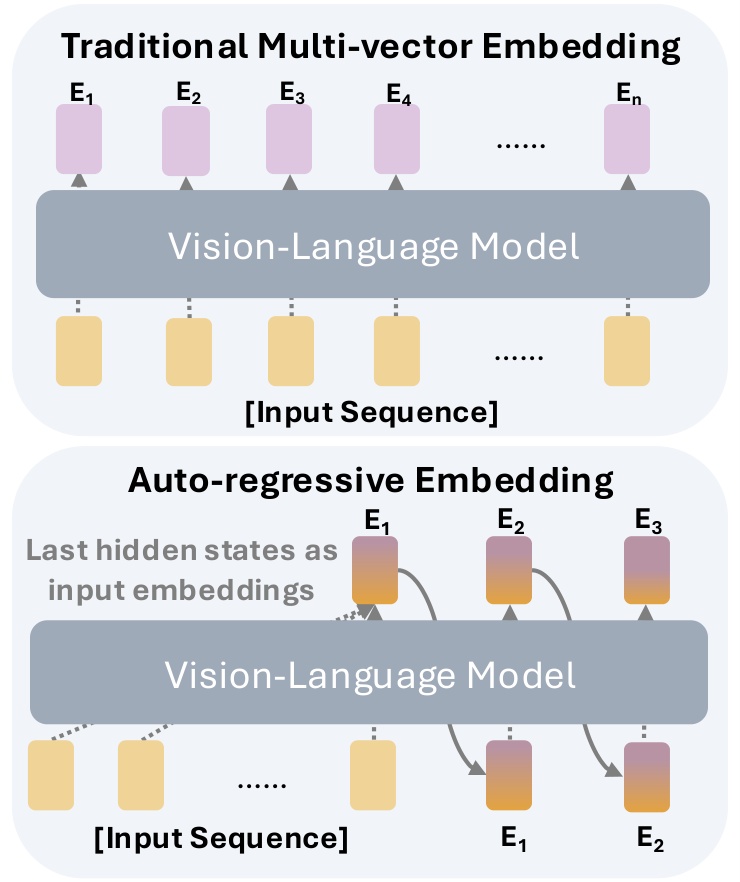
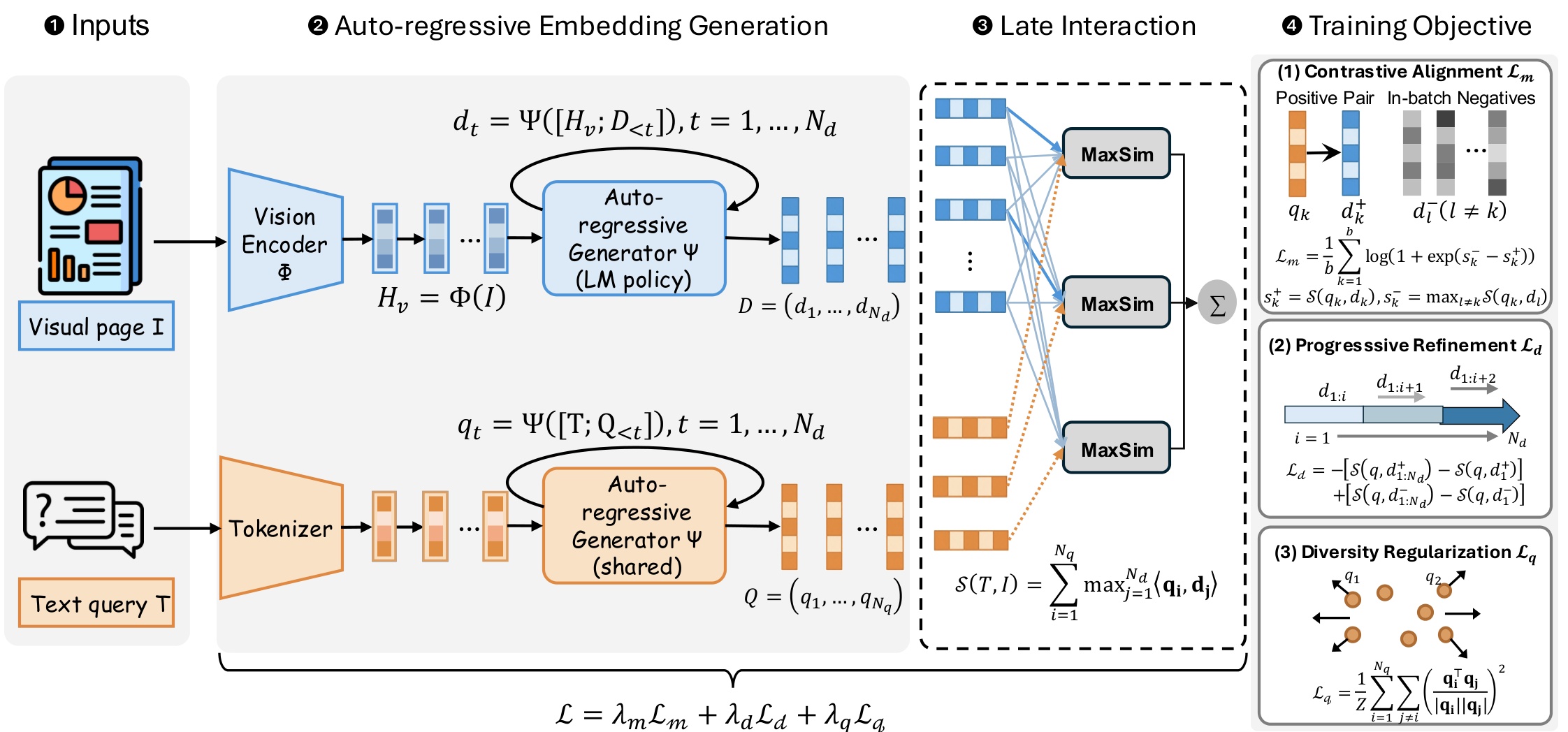
核心思路:论文的核心思路是利用自回归生成模型,在隐空间中生成多向量嵌入,从而用少量的token表示文档。通过迭代地生成向量,并结合对比学习和边际损失,模型能够学习到紧凑且结构化的文档表示,从而在保证检索性能的同时,显著降低存储开销。
技术框架:CausalEmbed的整体框架包括以下几个主要阶段:1) 使用视觉编码器(如ViT)提取文档的视觉特征;2) 使用自回归生成模型(如Transformer)在隐空间中迭代地生成多向量嵌入;3) 使用对比学习目标,结合迭代边际损失,训练生成模型,使其能够生成高质量的文档表示。
关键创新:论文的关键创新在于提出了自回归多向量生成方法,并将其应用于视觉文档嵌入。与现有方法直接使用大量视觉token不同,CausalEmbed通过生成的方式,用少量的向量表示文档,从而显著降低了存储开销。此外,迭代边际损失的设计也提高了嵌入的质量和区分度。
关键设计:CausalEmbed的关键设计包括:1) 自回归生成模型的选择,例如使用Transformer decoder;2) 迭代边际损失的设计,用于优化对比学习过程,鼓励模型学习更具区分性的嵌入;3) 灵活的测试时缩放策略,允许根据实际需求调整生成的向量数量,从而在性能和效率之间进行权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CausalEmbed在多个视觉文档检索基准测试中取得了显著的性能提升。例如,在保持竞争力的检索性能的同时,CausalEmbed能够将token数量减少30-155倍。此外,实验还验证了CausalEmbed在训练效率和测试时可扩展性方面的优势,证明了自回归嵌入生成方法的有效性。
🎯 应用场景
CausalEmbed在视觉文档检索领域具有广泛的应用前景,例如可以应用于大规模文档数据库的检索、信息抽取、文档分类等任务。该方法能够有效降低存储成本,提高检索效率,使得在资源受限的环境下也能部署高性能的文档检索系统。此外,该方法还可以推广到其他多模态检索任务中,例如图像检索、视频检索等。
📄 摘要(原文)
Although Multimodal Large Language Models (MLLMs) have shown remarkable potential in Visual Document Retrieval (VDR) through generating high-quality multi-vector embeddings, the substantial storage overhead caused by representing a page with thousands of visual tokens limits their practicality in real-world applications. To address this challenge, we propose an auto-regressive generation approach, CausalEmbed, for constructing multi-vector embeddings. By incorporating iterative margin loss during contrastive training, CausalEmbed encourages the embedding models to learn compact and well-structured representations. Our method enables efficient VDR tasks using only dozens of visual tokens, achieving a 30-155x reduction in token count while maintaining highly competitive performance across various backbones and benchmarks. Theoretical analysis and empirical results demonstrate the unique advantages of auto-regressive embedding generation in terms of training efficiency and scalability at test time. As a result, CausalEmbed introduces a flexible test-time scaling strategy for multi-vector VDR representations and sheds light on the generative paradigm within multimodal document retrieval.