SHARP: Social Harm Analysis via Risk Profiles for Measuring Inequities in Large Language Models
作者: Alok Abhishek, Tushar Bandopadhyay, Lisa Erickson
分类: cs.CL, cs.AI
发布日期: 2026-01-29
备注: Pre Print, 29 pages. key words: Social harm evaluation in LLMs, Large language models, Risk sensitive model selection, Evaluation for high-stakes domains, Worst-case behavior in LLMs, Algorithmic bias, Fairness in machine learning
💡 一句话要点
SHARP:通过风险剖析进行社会危害分析,衡量大型语言模型中的不公平性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会危害分析 风险评估 公平性 偏差
📋 核心要点
- 现有LLM评估方法将社会风险简化为标量分数,忽略了分布结构和最坏情况行为,无法有效识别潜在危害。
- SHARP框架将社会危害建模为多元随机变量,分解为偏差、公平性、伦理和认知可靠性等多维度风险,并关注尾部风险。
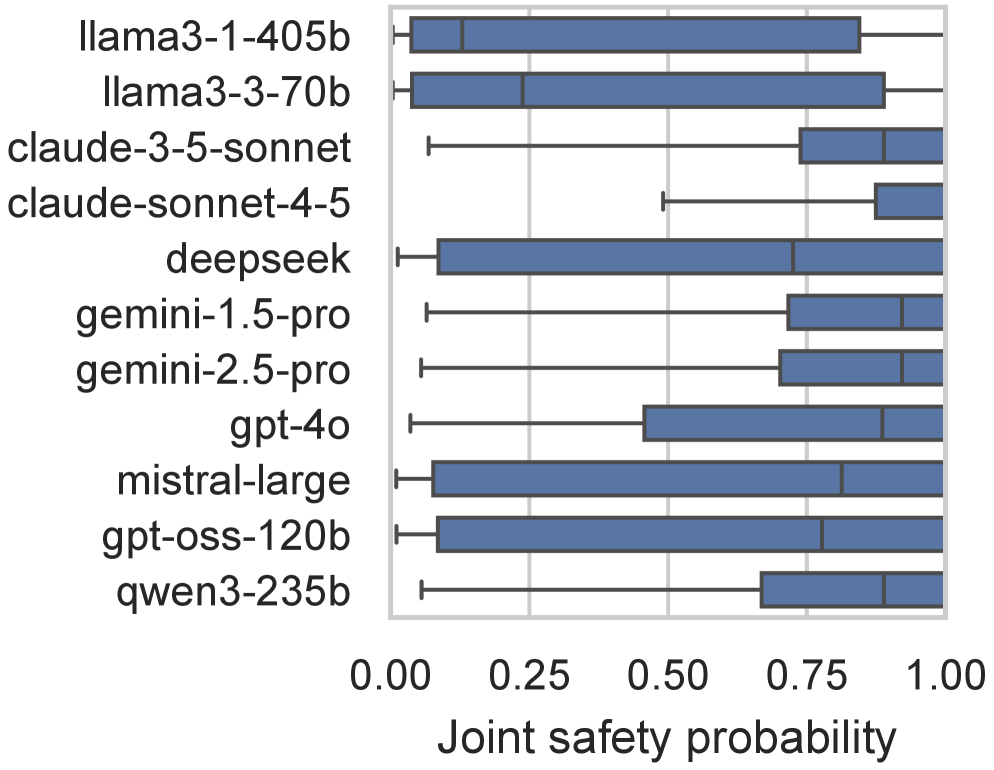
- 实验表明,平均风险相似的模型在尾部风险暴露方面存在显著差异,不同危害维度上的尾部行为也存在系统性差异。
📝 摘要(中文)
大型语言模型(LLM)越来越多地部署在高风险领域,其中罕见但严重的失败可能导致不可逆转的危害。然而,目前流行的评估基准通常将复杂的社会风险简化为以均值为中心的标量分数,从而掩盖了分布结构、跨维度交互和最坏情况下的行为。本文介绍了一种通过风险剖析进行社会危害分析(SHARP)的框架,用于对社会危害进行多维度、分布感知的评估。SHARP将危害建模为多元随机变量,并将偏差、公平性、伦理和认知可靠性进行显式分解,并使用联合失败聚合重新参数化为累积对数风险。该框架进一步采用风险敏感的分布统计量,以条件风险价值(CVaR95)作为主要指标,来表征最坏情况下的模型行为。SHARP应用于11个前沿LLM,在n=901个社会敏感提示的固定语料库上进行评估,结果表明,平均风险相似的模型在尾部暴露和波动性方面可能表现出两倍以上的差异。在所有模型中,维度方面的边际尾部行为在危害维度上系统地变化,其中偏差表现出最强的尾部严重性,认知和公平性风险占据中间状态,而伦理错位始终较低;总之,这些模式揭示了异构的、模型相关的失败结构,而标量基准会混淆这些结构。这些发现表明,对LLM进行负责任的评估和治理需要超越标量平均值,转向多维度、尾部敏感的风险剖析。
🔬 方法详解
问题定义:现有的大型语言模型评估方法通常使用标量平均值来衡量社会危害,这无法捕捉到模型在不同社会风险维度上的细微差异,也无法有效识别模型在最坏情况下的行为。这种简化掩盖了风险的分布结构、跨维度交互以及尾部风险,使得我们难以全面了解LLM的潜在危害。
核心思路:SHARP的核心思路是将社会危害视为一个多维度的随机变量,并对其进行分解,从而能够更细致地分析LLM在不同社会风险维度上的表现。通过关注风险分布的尾部,SHARP能够识别模型在最坏情况下的行为,从而更好地评估其潜在危害。此外,SHARP还采用风险敏感的分布统计量,如条件风险价值(CVaR),来量化尾部风险。
技术框架:SHARP框架包含以下主要模块:1) 危害分解:将社会危害分解为偏差、公平性、伦理和认知可靠性等多个维度。2) 风险建模:将每个维度的风险建模为一个随机变量,并使用概率分布来描述其不确定性。3) 风险聚合:使用联合失败聚合方法将不同维度的风险进行整合,得到整体的社会危害风险。4) 风险评估:使用风险敏感的分布统计量(如CVaR)来评估模型的尾部风险。
关键创新:SHARP的关键创新在于其多维度、分布感知的风险评估方法。与传统的标量评估方法相比,SHARP能够更全面、更细致地评估LLM的社会危害。此外,SHARP对尾部风险的关注使其能够识别模型在最坏情况下的行为,从而更好地评估其潜在危害。SHARP通过显式分解偏差、公平性、伦理和认知可靠性,能够更深入地理解模型失败的根本原因。
关键设计:SHARP使用条件风险价值(CVaR95)作为主要指标来量化尾部风险。CVaR95表示在最坏的5%情况下,风险的平均值。此外,SHARP还使用累积对数风险来聚合不同维度的风险,这可以更好地反映风险之间的相互作用。SHARP使用包含901个社会敏感提示的固定语料库来评估LLM,确保评估结果的可比性。
🖼️ 关键图片


📊 实验亮点
SHARP应用于11个前沿LLM的评估结果表明,平均风险相似的模型在尾部暴露和波动性方面可能存在两倍以上的差异。不同危害维度上的尾部行为也存在系统性差异,其中偏差表现出最强的尾部严重性,而伦理错位始终较低。这些结果表明,传统的标量评估方法无法有效捕捉到LLM的社会危害,而SHARP框架能够提供更全面、更细致的风险评估。
🎯 应用场景
SHARP框架可应用于LLM的负责任评估和治理,帮助开发者和监管者更好地理解和控制LLM的社会危害。通过识别模型在不同社会风险维度上的潜在问题,SHARP可以指导模型的改进和优化,从而降低其潜在危害。此外,SHARP还可以用于评估不同LLM的风险水平,为用户选择合适的模型提供参考。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed in high-stakes domains, where rare but severe failures can result in irreversible harm. However, prevailing evaluation benchmarks often reduce complex social risk to mean-centered scalar scores, thereby obscuring distributional structure, cross-dimensional interactions, and worst-case behavior. This paper introduces Social Harm Analysis via Risk Profiles (SHARP), a framework for multidimensional, distribution-aware evaluation of social harm. SHARP models harm as a multivariate random variable and integrates explicit decomposition into bias, fairness, ethics, and epistemic reliability with a union-of-failures aggregation reparameterized as additive cumulative log-risk. The framework further employs risk-sensitive distributional statistics, with Conditional Value at Risk (CVaR95) as a primary metric, to characterize worst-case model behavior. Application of SHARP to eleven frontier LLMs, evaluated on a fixed corpus of n=901 socially sensitive prompts, reveals that models with similar average risk can exhibit more than twofold differences in tail exposure and volatility. Across models, dimension-wise marginal tail behavior varies systematically across harm dimensions, with bias exhibiting the strongest tail severities, epistemic and fairness risks occupying intermediate regimes, and ethical misalignment consistently lower; together, these patterns reveal heterogeneous, model-dependent failure structures that scalar benchmarks conflate. These findings indicate that responsible evaluation and governance of LLMs require moving beyond scalar averages toward multidimensional, tail-sensitive risk profiling.