MGSM-Pro: A Simple Strategy for Robust Multilingual Mathematical Reasoning Evaluation
作者: Tianyi Xu, Kosei Uemura, Alfred Malengo Kondoro, Tadesse Destaw Belay, Catherine Nana Nyaah Essuman, Ifeoma Okoh, Ganiyat Afolabi, Ayodele Awokoya, David Ifeoluwa Adelani
分类: cs.CL, cs.AI
发布日期: 2026-01-29
💡 一句话要点
MGSM-Pro:一种稳健的多语言数学推理评估策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言数学推理 鲁棒性评估 大型语言模型 低资源语言 问题实例化
📋 核心要点
- 现有数学推理基准测试在多语言支持和对抗样本鲁棒性方面存在不足,尤其是在低资源语言上。
- MGSM-Pro通过引入数字、名称和上下文变化的多样化实例化,增强了数学推理评估的鲁棒性。
- 实验表明,不同模型在数字实例化上的鲁棒性差异显著,强调了使用多样化实例评估的重要性。
📝 摘要(中文)
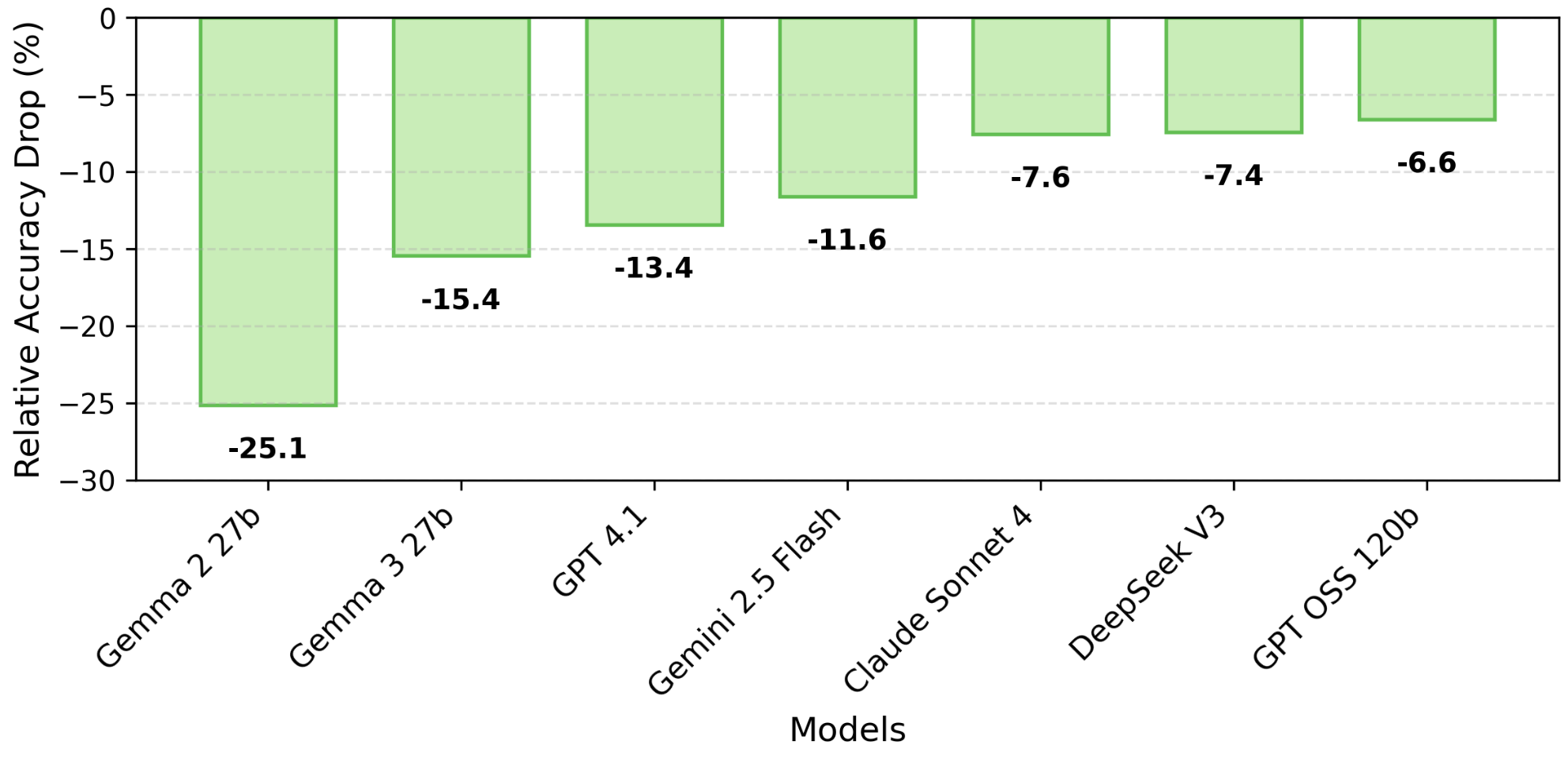
大型语言模型在数学推理方面取得了显著进展。然而,多语言评估的基准测试在难度和时效性上都落后于英语。最近,GSM-Symbolic表明,当模型在同一问题的不同实例化上进行评估时,存在很大的方差;然而,该评估仅以英语进行。在本文中,我们介绍了MGSM-Pro,它是MGSM数据集的扩展,采用了GSM-Symbolic方法。我们的数据集为每个MGSM问题提供了五个实例化,通过改变名称、数字和无关上下文来实现。跨九种语言的评估表明,许多低资源语言在测试与原始测试集中不同的数字实例化时,性能会大幅下降。我们进一步发现,一些专有模型,特别是Gemini 2.5 Flash和GPT-4.1,对数字实例化不太稳健,而Claude 4.0 Sonnet则更稳健。在开放模型中,GPT-OSS 120B和DeepSeek V3表现出更强的鲁棒性。基于这些发现,我们建议使用至少五个数字变化的实例化来评估每个问题,以获得更稳健和真实的数学推理评估。
🔬 方法详解
问题定义:现有的大型语言模型在数学推理方面取得了进展,但多语言数学推理的评估基准,特别是对于低资源语言,在难度和多样性上存在不足。GSM-Symbolic方法揭示了模型在相同问题的不同实例化上的性能方差很大,但之前的研究主要集中在英语上。因此,需要一个更鲁棒的多语言数学推理评估基准,能够有效衡量模型在不同语言和不同问题实例化上的泛化能力。
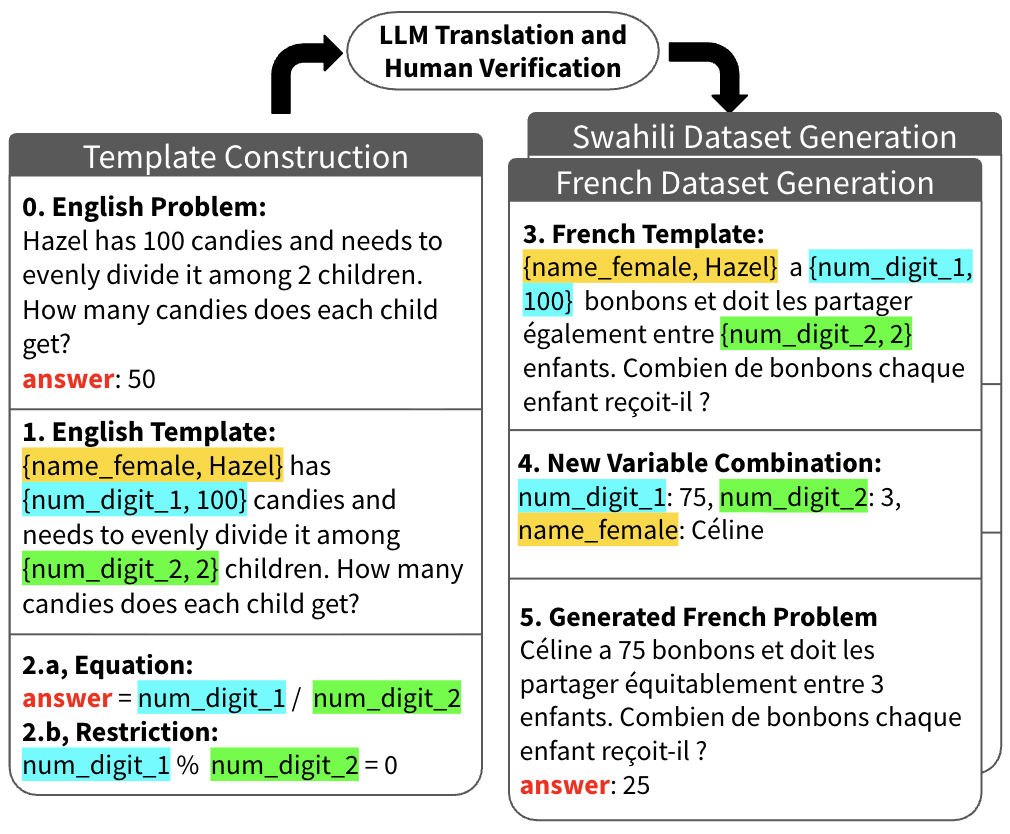
核心思路:MGSM-Pro的核心思路是通过对现有MGSM数据集中的每个问题生成多个实例化,从而提高评估的鲁棒性。这些实例化通过改变问题中的数字、名称和无关上下文来实现,旨在模拟真实世界中问题的多样性,并测试模型在面对这些变化时的推理能力。通过评估模型在多个实例化上的平均性能,可以更准确地评估模型的数学推理能力。
技术框架:MGSM-Pro的构建主要包含以下几个阶段:1) 基于MGSM数据集,选择需要扩展的数学推理问题。2) 对于每个问题,生成五个不同的实例化,通过随机替换数字、名称和修改无关上下文来实现。3) 使用这些实例化后的问题,在多个大型语言模型上进行评估。4) 分析模型在不同实例化上的性能差异,并计算平均性能,作为模型鲁棒性的指标。
关键创新:MGSM-Pro的关键创新在于它提供了一种简单而有效的方法来提高多语言数学推理评估的鲁棒性。通过引入问题实例化的概念,MGSM-Pro能够更全面地评估模型在面对真实世界问题时的泛化能力。此外,MGSM-Pro还揭示了不同模型在数字实例化上的鲁棒性差异,为模型选择和改进提供了有价值的信息。
关键设计:MGSM-Pro的关键设计包括:1) 每个问题生成五个实例化,以平衡评估的准确性和计算成本。2) 实例化的生成策略,包括随机替换数字、名称和修改无关上下文,以确保实例化的多样性。3) 使用多个大型语言模型进行评估,以获得更全面的结果。4) 性能指标的选择,例如平均准确率,以衡量模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
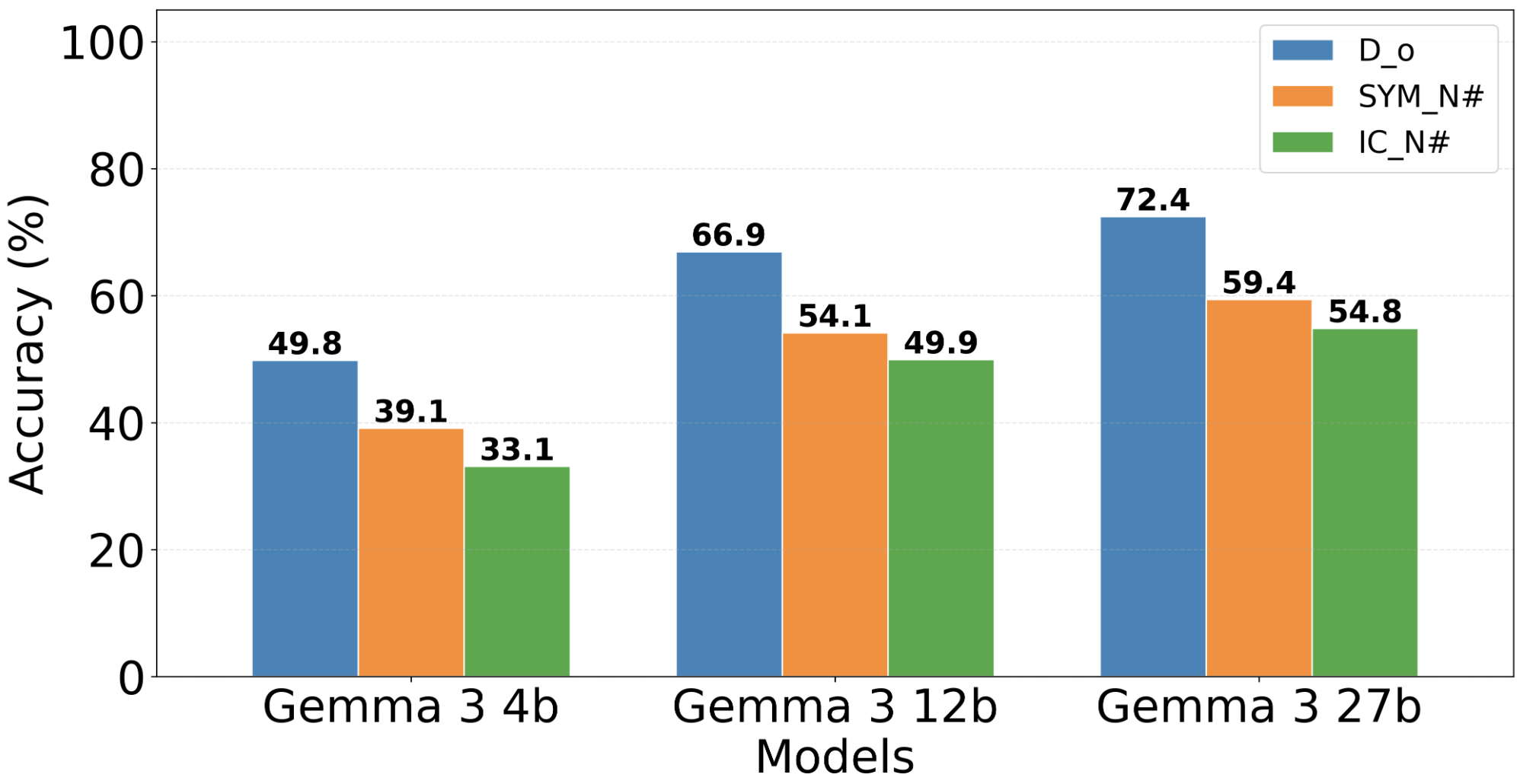
实验结果表明,许多低资源语言在数字实例化上的性能下降显著,突显了现有模型在多语言数学推理方面的局限性。同时,Gemini 2.5 Flash和GPT-4.1等专有模型在数字实例化上的鲁棒性较差,而Claude 4.0 Sonnet则表现出更强的鲁棒性。在开源模型中,GPT-OSS 120B和DeepSeek V3表现出较好的鲁棒性。这些发现强调了使用多样化实例评估的重要性。
🎯 应用场景
MGSM-Pro可用于评估和比较不同大型语言模型在多语言数学推理任务上的性能。它有助于识别模型的优势和劣势,并指导模型改进。此外,该数据集可以促进对低资源语言数学推理能力的研究,并推动相关技术的进步。该研究的成果可以应用于教育、金融等领域,提高自动化问题解决的准确性和可靠性。
📄 摘要(原文)
Large language models have made substantial progress in mathematical reasoning. However, benchmark development for multilingual evaluation has lagged behind English in both difficulty and recency. Recently, GSM-Symbolic showed a strong evidence of high variance when models are evaluated on different instantiations of the same question; however, the evaluation was conducted only in English. In this paper, we introduce MGSM-Pro, an extension of MGSM dataset with GSM-Symbolic approach. Our dataset provides five instantiations per MGSM question by varying names, digits and irrelevant context. Evaluations across nine languages reveal that many low-resource languages suffer large performance drops when tested on digit instantiations different from those in the original test set. We further find that some proprietary models, notably Gemini 2.5 Flash and GPT-4.1, are less robust to digit instantiation, whereas Claude 4.0 Sonnet is more robust. Among open models, GPT-OSS 120B and DeepSeek V3 show stronger robustness. Based on these findings, we recommend evaluating each problem using at least five digit-varying instantiations to obtain a more robust and realistic assessment of math reasoning.