Parametric Knowledge is Not All You Need: Toward Honest Large Language Models via Retrieval of Pretraining Data
作者: Christopher Adrian Kusuma, Muhammad Reza Qorib, Hwee Tou Ng
分类: cs.CL
发布日期: 2026-01-29
💡 一句话要点
利用预训练数据检索,提升大语言模型回答问题的诚实度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 诚实度 预训练数据 知识检索 幻觉问题
📋 核心要点
- 现有LLM在知识不足时易产生幻觉,缺乏对自身知识边界的认知,影响回答的可靠性。
- 论文提出利用LLM的预训练数据,通过检索相关知识来辅助模型判断自身是否具备回答问题的能力。
- 论文使用Pythia模型构建评估基准,并验证了所提方法能有效提升LLM的诚实度。
📝 摘要(中文)
大型语言模型(LLM)在回答问题方面表现出色,但常常缺乏对其自身知识边界的认知,即不清楚自己知道什么和不知道什么。这导致它们在不熟悉的领域生成不准确的回答,即产生幻觉。相比于幻觉,语言模型更应该在知识不足时诚实地回答“我不知道”。虽然已经有许多方法旨在提高LLM的诚实度,但它们的评估缺乏鲁棒性,因为没有考虑到LLM在预训练期间吸收的知识。本文提出了一种更鲁棒的LLM诚实度评估基准数据集,该数据集基于Pythia,一个真正开放的LLM,并具有公开可用的预训练数据。此外,我们还提出了一种利用预训练数据构建更诚实LLM的新方法。
🔬 方法详解
问题定义:现有的大语言模型在回答问题时,即使对其不熟悉的领域,也倾向于生成答案,而不是坦诚地承认“不知道”。这种“幻觉”问题降低了LLM的可信度。现有的评估方法往往忽略了LLM在预训练阶段已经学习到的知识,导致评估结果不够鲁棒。
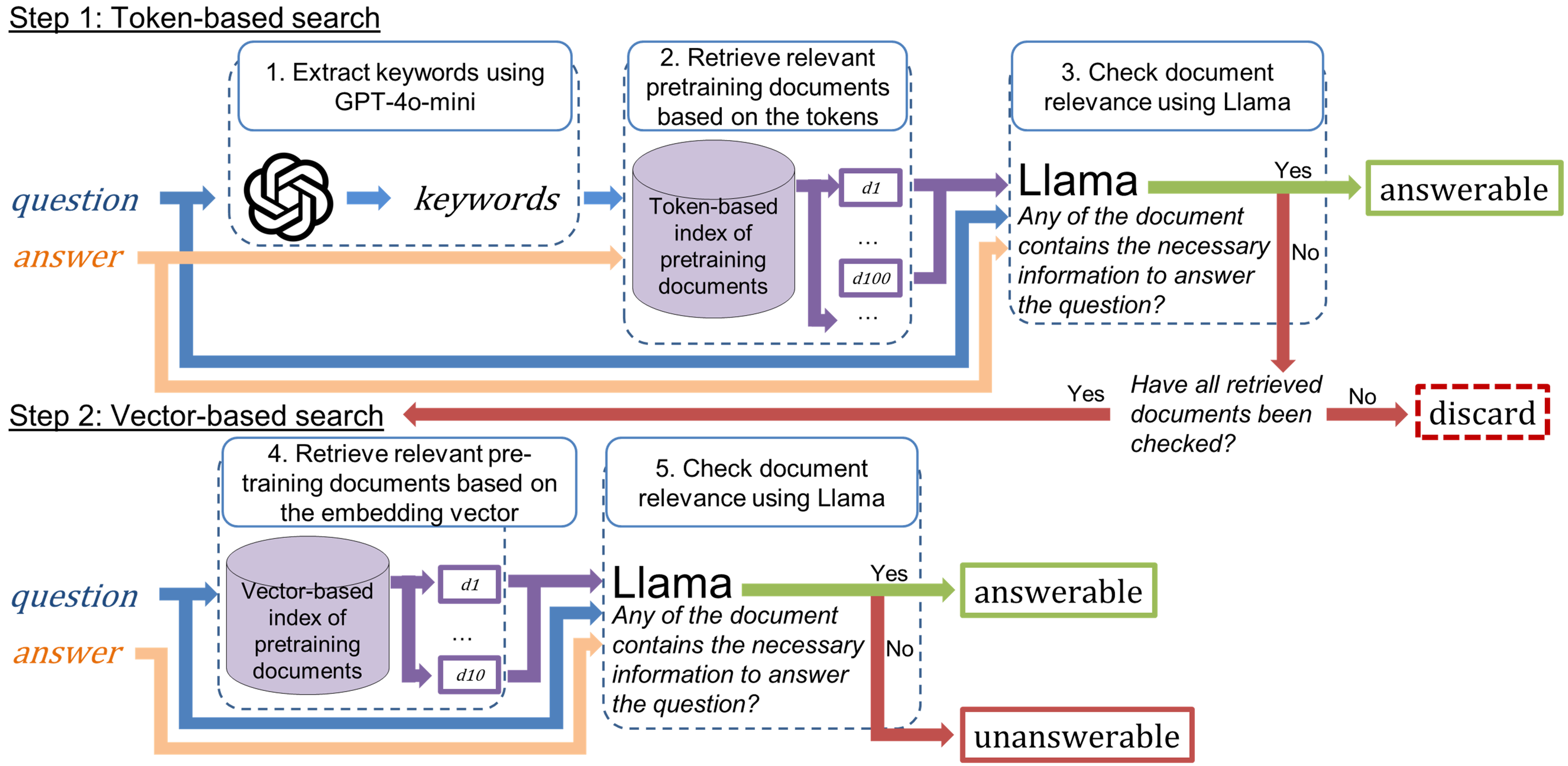
核心思路:论文的核心思路是利用LLM的预训练数据,通过检索与问题相关的预训练文本片段,来判断LLM是否具备回答该问题的知识。如果检索到的预训练数据表明LLM已经接触过相关知识,则可以尝试回答;否则,更倾向于回答“不知道”,从而提高诚实度。
技术框架:该方法主要包含以下几个阶段:1) 问题输入;2) 预训练数据检索:使用问题作为query,在预训练数据集中检索相关文本片段;3) 知识判断:基于检索到的文本片段,判断LLM是否具备回答问题的知识;4) 回答生成:如果判断LLM具备相关知识,则生成答案;否则,回答“不知道”。
关键创新:该方法最重要的创新点在于利用预训练数据作为外部知识库,通过检索来辅助LLM进行知识判断,从而提高回答的诚实度。与现有方法相比,该方法更充分地利用了LLM在预训练阶段学习到的知识,避免了盲目自信的回答。
关键设计:具体的检索方法可以使用现有的信息检索技术,例如基于向量相似度的检索。知识判断模块可以设计为一个二分类器,输入为问题和检索到的文本片段,输出为LLM是否具备回答问题的知识。损失函数的设计需要考虑提高回答的准确率和诚实度,例如可以加入惩罚项,惩罚不诚实的回答。
🖼️ 关键图片
📊 实验亮点
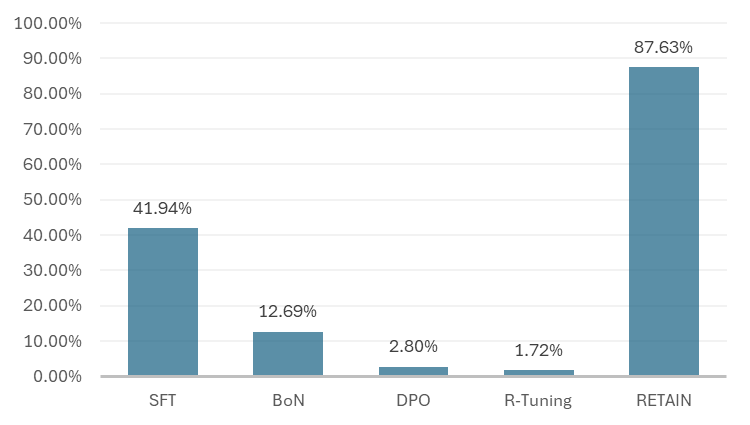
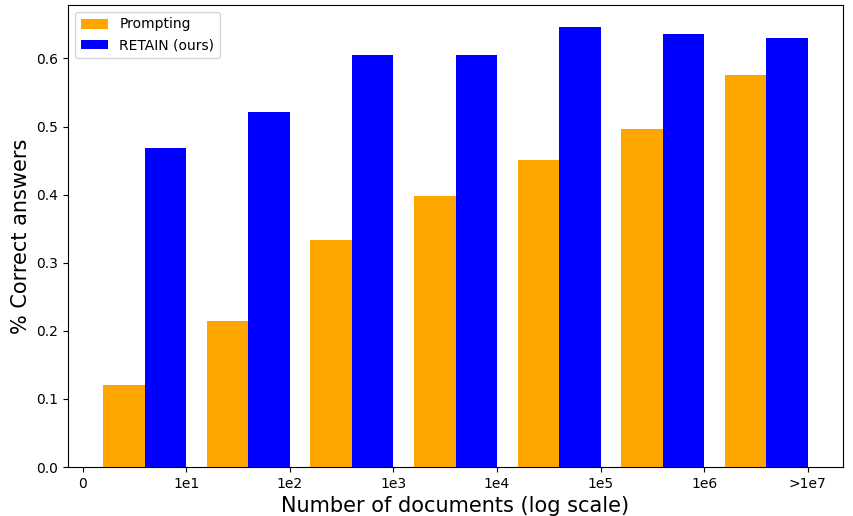
论文使用Pythia模型进行了实验,并构建了更鲁棒的评估基准。实验结果表明,所提出的方法能够有效提高LLM回答问题的诚实度,在保证准确率的同时,显著减少了幻觉现象。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要LLM提供问答服务的场景,例如智能客服、知识问答系统、教育辅导等。通过提高LLM的诚实度,可以增强用户对LLM的信任,并减少因错误信息带来的负面影响。未来,该方法可以进一步扩展到其他类型的知识密集型任务中。
📄 摘要(原文)
Large language models (LLMs) are highly capable of answering questions, but they are often unaware of their own knowledge boundary, i.e., knowing what they know and what they don't know. As a result, they can generate factually incorrect responses on topics they do not have enough knowledge of, commonly known as hallucination. Rather than hallucinating, a language model should be more honest and respond with "I don't know" when it does not have enough knowledge about a topic. Many methods have been proposed to improve LLM honesty, but their evaluations lack robustness, as they do not take into account the knowledge that the LLM has ingested during its pretraining. In this paper, we propose a more robust evaluation benchmark dataset for LLM honesty by utilizing Pythia, a truly open LLM with publicly available pretraining data. In addition, we also propose a novel method for harnessing the pretraining data to build a more honest LLM.