Scaling Reasoning Hop Exposes Weaknesses: Demystifying and Improving Hop Generalization in Large Language Models
作者: Zhaoyi Li, Jiatong Li, Gangwei Jiang, Linqi Song, Defu Lian, Ying Wei
分类: cs.CL, cs.LG
发布日期: 2026-01-29
备注: 52 pages, accepted by ICLR 2026 main conference
💡 一句话要点
提出测试时推理修正方法,提升大语言模型在推理跳数泛化上的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理跳数泛化 思维链 注意力机制 测试时修正
📋 核心要点
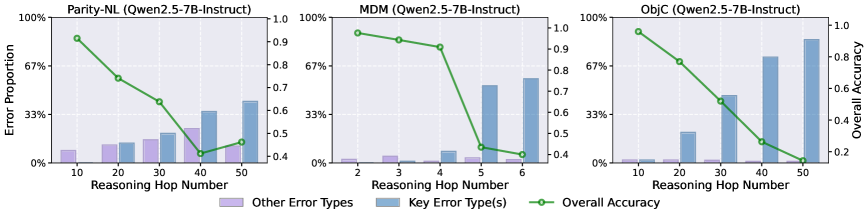
- 现有大语言模型在推理跳数泛化方面存在显著的性能下降,尤其是在推理步骤超出训练分布时。
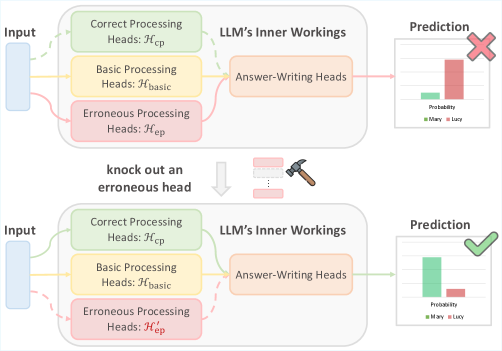
- 该论文提出了一种测试时推理修正方法,通过动态识别并停用推理过程中的错误处理头(ep heads)来纠正错误。
- 实验结果表明,该方法在不同任务和大型语言模型上均能有效提升推理跳数泛化能力。
📝 摘要(中文)
思维链(CoT)推理已成为使大型语言模型(LLM)解决复杂问题的标准范式。然而,最近的研究表明,在推理跳数泛化场景中,当所需的推理步骤数超过训练分布时,性能会急剧下降,而底层算法保持不变。驱动这种失败的内部机制仍然知之甚少。在这项工作中,我们对来自多个领域的任务进行了系统研究,发现错误集中在少数关键错误类型的token位置,而不是均匀分布。更仔细的检查表明,这些token级别的错误预测源于内部竞争机制:某些注意力头,称为错误处理头(ep heads),通过放大不正确的推理轨迹同时抑制正确的推理轨迹来打破平衡。值得注意的是,在推理过程中移除单个ep head通常可以恢复正确的预测。受这些见解的启发,我们提出了推理的测试时修正,这是一种轻量级的干预方法,可以动态地识别和停用推理过程中的ep head。跨不同任务和LLM的广泛实验表明,它始终如一地提高了推理跳数泛化能力,突出了其有效性和潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推理跳数泛化(reasoning hop generalization)中表现出的性能下降问题。具体来说,当LLM需要执行比训练数据中更长的推理链时,其性能会显著降低。现有的方法未能充分理解这种性能下降的根本原因,并且缺乏有效的干预手段。
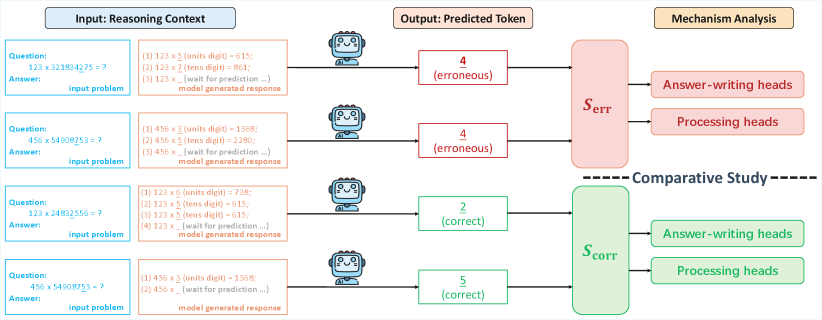
核心思路:论文的核心思路是识别并消除导致推理错误的“错误处理头”(erroneous processing heads, ep heads)。作者发现,推理错误并非均匀分布,而是集中在某些特定的token位置,这些位置的错误预测是由某些注意力头引起的。通过在测试时动态地停用这些ep heads,可以有效地纠正推理过程中的错误。
技术框架:该方法主要包含以下几个步骤:1) 错误定位:通过分析LLM的推理过程,识别出导致错误预测的关键token位置。2) ep head识别:确定负责处理这些错误token的注意力头,即ep heads。3) 测试时修正:在推理过程中,动态地停用这些ep heads,阻止它们对推理过程产生负面影响。4) 推理执行:在修正后的模型上执行推理,得到更准确的结果。
关键创新:该论文的关键创新在于发现了“错误处理头”(ep heads)这一概念,并提出了一种基于动态停用ep heads的测试时修正方法。与传统的模型训练或微调方法不同,该方法无需额外的训练数据,可以直接应用于现有的LLM,具有轻量级和高效的特点。
关键设计:该方法的关键设计包括:1) ep head的识别策略:论文可能采用某种指标(例如,注意力权重的方差或梯度)来衡量注意力头对错误预测的影响程度,从而识别出ep heads。2) 停用策略:论文可能采用直接屏蔽(masking)或权重衰减等方法来停用ep heads。3) 动态性:该方法强调在测试时动态地识别和停用ep heads,这意味着ep heads的识别和停用是根据具体的输入和推理过程进行的,而不是预先设定的。
🖼️ 关键图片
📊 实验亮点
该论文通过实验证明,提出的测试时推理修正方法能够显著提升LLM在推理跳数泛化上的性能。具体而言,在多个任务和不同的LLM上,该方法都取得了持续的改进。通过动态停用ep heads,模型能够更准确地执行长链推理,从而在超出训练分布的场景下表现出更好的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如问答系统、知识图谱推理、代码生成等。通过提升LLM的推理能力,可以提高这些应用在复杂任务上的性能和可靠性。此外,该研究也为理解LLM的内部机制提供了新的视角,有助于开发更高效、更可靠的LLM。
📄 摘要(原文)
Chain-of-thought (CoT) reasoning has become the standard paradigm for enabling Large Language Models (LLMs) to solve complex problems. However, recent studies reveal a sharp performance drop in reasoning hop generalization scenarios, where the required number of reasoning steps exceeds training distributions while the underlying algorithm remains unchanged. The internal mechanisms driving this failure remain poorly understood. In this work, we conduct a systematic study on tasks from multiple domains, and find that errors concentrate at token positions of a few critical error types, rather than being uniformly distributed. Closer inspection reveals that these token-level erroneous predictions stem from internal competition mechanisms: certain attention heads, termed erroneous processing heads (ep heads), tip the balance by amplifying incorrect reasoning trajectories while suppressing correct ones. Notably, removing individual ep heads during inference can often restore the correct predictions. Motivated by these insights, we propose test-time correction of reasoning, a lightweight intervention method that dynamically identifies and deactivates ep heads in the reasoning process. Extensive experiments across different tasks and LLMs show that it consistently improves reasoning hop generalization, highlighting both its effectiveness and potential.