Scaling Embeddings Outperforms Scaling Experts in Language Models
作者: Hong Liu, Jiaqi Zhang, Chao Wang, Xing Hu, Linkun Lyu, Jiaqi Sun, Xurui Yang, Bo Wang, Fengcun Li, Yulei Qian, Lingtong Si, Yerui Sun, Rumei Li, Peng Pei, Yuchen Xie, Xunliang Cai
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-29
💡 一句话要点
语言模型中,扩展嵌入层优于扩展专家层,并提出LongCat-Flash-Lite模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 嵌入扩展 混合专家模型 稀疏性 模型优化
📋 核心要点
- MoE模型在扩展大型语言模型时面临收益递减和系统瓶颈等问题。
- 论文提出通过扩展嵌入层作为一种新的稀疏扩展维度,并分析其有效性。
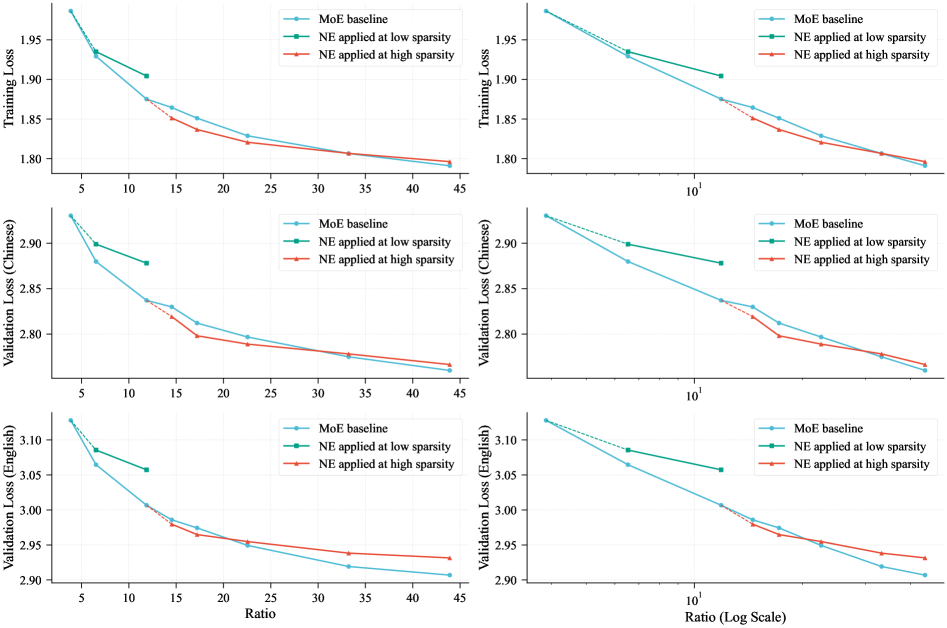
- 实验表明,嵌入扩展在特定情况下优于专家扩展,并提出了LongCat-Flash-Lite模型。
📝 摘要(中文)
混合专家模型(MoE)已成为大型语言模型中稀疏扩展的标准方法,但它们面临着收益递减和系统瓶颈。本文探索了嵌入扩展作为稀疏扩展的有效且正交的维度。通过全面的分析和实验,我们确定了嵌入扩展实现优于专家扩展的特定区域。我们系统地描述了影响这种效果的关键架构因素,包括参数预算以及与模型宽度和深度的相互作用。此外,通过集成定制的系统优化和推测解码,我们有效地将这种稀疏性转化为实际的推理加速。在这些见解的指导下,我们推出了LongCat-Flash-Lite,一个具有685亿参数和约30亿激活参数的从头开始训练的模型。尽管将超过300亿个参数分配给嵌入,但LongCat-Flash-Lite不仅超越了参数相当的MoE基线,而且在代理和编码领域表现出与现有同等规模模型相比的卓越竞争力。
🔬 方法详解
问题定义:现有的大型语言模型通常采用混合专家模型(MoE)进行扩展,但这种方法面临收益递减和系统瓶颈。论文旨在探索一种新的稀疏扩展方法,以克服MoE的局限性。MoE模型的痛点在于专家数量的增加会导致路由复杂性增加,以及专家之间的负载不平衡问题。
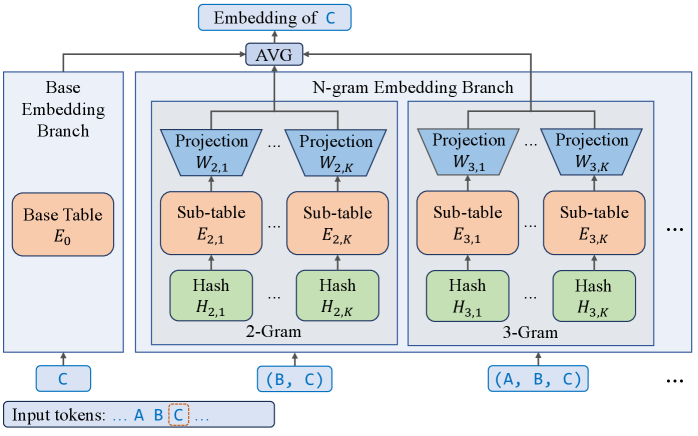
核心思路:论文的核心思路是利用嵌入层扩展作为一种替代的稀疏扩展维度。通过增加嵌入层的维度和参数量,模型可以学习更丰富的表示,从而提高性能。这种方法与MoE不同,它不需要复杂的路由机制,并且可以更有效地利用参数。
技术框架:论文提出的方法主要涉及对Transformer模型的嵌入层进行扩展。具体来说,增加了嵌入层的维度,并相应地调整了其他层的参数,以保持模型的整体平衡。此外,论文还采用了定制的系统优化和推测解码技术,以提高推理速度。LongCat-Flash-Lite模型是基于这种框架构建的,它具有685亿参数,其中超过300亿个参数分配给嵌入层。
关键创新:论文的关键创新在于发现了嵌入扩展在特定情况下优于专家扩展的潜力。与MoE相比,嵌入扩展可以更有效地利用参数,并且避免了复杂的路由机制。此外,论文还通过系统优化和推测解码,将嵌入扩展的优势转化为实际的推理加速。
关键设计:论文的关键设计包括参数预算的分配、模型宽度和深度的调整,以及系统优化和推测解码技术的应用。具体来说,论文通过实验确定了嵌入层参数的最佳比例,并调整了其他层的参数以保持模型的平衡。此外,论文还采用了定制的系统优化技术,以提高模型的训练和推理效率。推测解码技术则用于加速模型的推理过程。
🖼️ 关键图片

📊 实验亮点
LongCat-Flash-Lite模型在参数量相当的情况下,超越了MoE基线模型,并在代理和编码领域表现出卓越的竞争力。该模型具有685亿参数,其中约30亿激活参数,超过300亿参数分配给嵌入层。实验结果表明,嵌入扩展是一种有效的稀疏扩展方法,可以提高语言模型的性能和效率。
🎯 应用场景
该研究成果可应用于各种需要大规模语言模型的场景,例如智能助手、代码生成、文本摘要等。通过采用嵌入扩展技术,可以构建更高效、更强大的语言模型,从而提高这些应用的性能和用户体验。此外,该研究还为未来的语言模型架构设计提供了新的思路。
📄 摘要(原文)
While Mixture-of-Experts (MoE) architectures have become the standard for sparsity scaling in large language models, they increasingly face diminishing returns and system-level bottlenecks. In this work, we explore embedding scaling as a potent, orthogonal dimension for scaling sparsity. Through a comprehensive analysis and experiments, we identify specific regimes where embedding scaling achieves a superior Pareto frontier compared to expert scaling. We systematically characterize the critical architectural factors governing this efficacy -- ranging from parameter budgeting to the interplay with model width and depth. Moreover, by integrating tailored system optimizations and speculative decoding, we effectively convert this sparsity into tangible inference speedups. Guided by these insights, we introduce LongCat-Flash-Lite, a 68.5B parameter model with ~3B activated trained from scratch. Despite allocating over 30B parameters to embeddings, LongCat-Flash-Lite not only surpasses parameter-equivalent MoE baselines but also exhibits exceptional competitiveness against existing models of comparable scale, particularly in agentic and coding domains.