Dissecting Multimodal In-Context Learning: Modality Asymmetries and Circuit Dynamics in modern Transformers
作者: Yiran Huang, Karsten Roth, Quentin Bouniot, Wenjia Xu, Zeynep Akata
分类: cs.CL, cs.LG
发布日期: 2026-01-28
💡 一句话要点
揭示多模态上下文学习机制:Transformer中的模态不对称性和回路动态
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 上下文学习 Transformer 模态不对称性 机制分析
📋 核心要点
- 现有方法缺乏对多模态Transformer上下文学习机制的深入理解,尤其是在模态间信息关联方面。
- 该论文通过控制数据统计和模型架构,在小型Transformer上进行实验,揭示了多模态ICL中的模态不对称性。
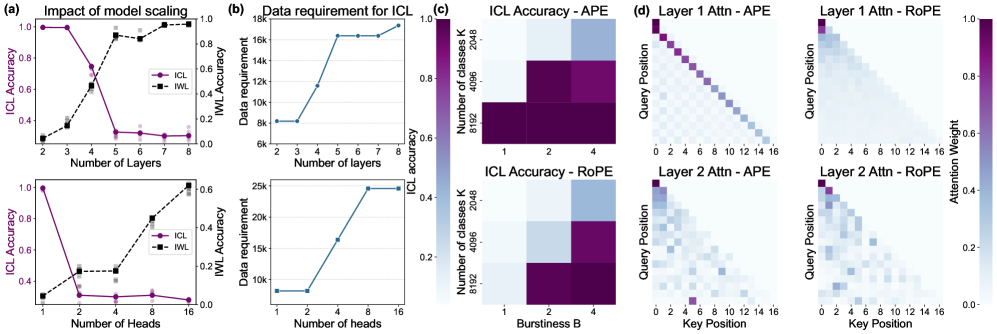
- 实验表明,主要模态预训练后,次要模态仅需较低的数据复杂度即可实现多模态ICL,并揭示了归纳式复制机制。
📝 摘要(中文)
基于Transformer的多模态大型语言模型通常表现出上下文学习(ICL)能力。受此现象的驱动,我们提出问题:Transformer如何从上下文示例中学习关联跨模态的信息?我们通过在小型Transformer上进行受控实验来研究这个问题,这些Transformer在合成分类任务上进行训练,从而能够精确地操纵数据统计和模型架构。我们首先回顾了现代Transformer中单模态ICL的核心原则。虽然复制了之前的几个发现,但我们发现旋转位置嵌入(RoPE)增加了ICL的数据复杂性阈值。扩展到多模态设置揭示了一种基本的学习不对称性:当在来自主要模态的高多样性数据上进行预训练时,次要模态中出人意料的低数据复杂性足以使多模态ICL出现。机制分析表明,两种设置都依赖于一种归纳式机制,该机制从匹配的上下文示例中复制标签;多模态训练改进并将这些回路扩展到跨模态。我们的发现为理解现代Transformer中的多模态ICL提供了机制基础,并为未来的研究引入了一个受控的测试平台。
🔬 方法详解
问题定义:论文旨在理解多模态Transformer如何通过上下文学习(ICL)关联不同模态的信息。现有方法缺乏对多模态ICL机制的深入理解,特别是模态间不对称性以及信息如何在模型内部传递和处理的细节。现有研究未能充分解释为何某些模态的数据复杂度要求较低即可实现有效的多模态ICL。
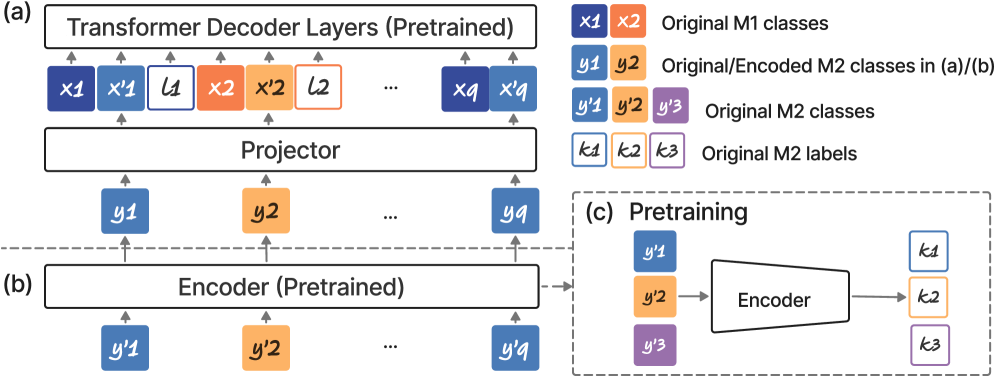
核心思路:论文的核心思路是通过构建可控的实验环境,使用小型Transformer在合成数据集上进行训练和分析,从而精确地操纵数据统计和模型架构。通过这种方式,研究者可以隔离并研究不同因素对多模态ICL的影响,例如模态数据复杂度、位置编码方式等。核心在于揭示模型内部的机制,例如信息如何在不同模态之间传递,以及哪些神经元或子网络负责执行特定的任务。
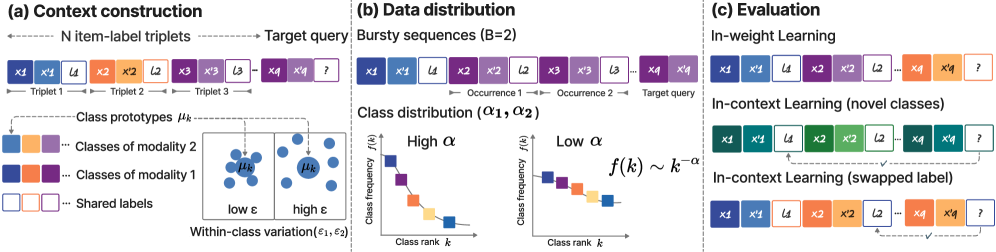
技术框架:整体框架包括以下几个主要阶段:1) 构建合成的多模态数据集,控制不同模态的数据复杂度;2) 使用小型Transformer模型进行训练,包括单模态预训练和多模态联合训练;3) 设计实验来评估模型的ICL能力,例如通过改变上下文示例的数量和质量;4) 使用机制分析技术,例如激活分析和权重分析,来理解模型内部的信息处理过程。
关键创新:论文最重要的技术创新点在于揭示了多模态ICL中的模态不对称性。具体来说,当模型在主要模态上进行预训练后,次要模态仅需较低的数据复杂度即可实现有效的多模态ICL。这表明模型能够利用从主要模态学习到的知识来加速次要模态的学习。此外,论文还通过机制分析揭示了模型内部的归纳式复制机制,解释了信息如何在不同模态之间传递。
关键设计:论文的关键设计包括:1) 使用旋转位置嵌入(RoPE)来研究位置编码对ICL的影响;2) 设计合成数据集,精确控制不同模态的数据复杂度;3) 使用小型Transformer模型,便于进行机制分析;4) 使用激活分析和权重分析等技术,追踪信息在模型内部的流动。
🖼️ 关键图片
📊 实验亮点
实验结果表明,旋转位置嵌入(RoPE)增加了ICL的数据复杂性阈值。更重要的是,研究揭示了多模态学习中的不对称性:在主要模态上预训练后,次要模态仅需较低的数据复杂度即可实现多模态ICL。机制分析证实,模型依赖于归纳式复制机制,且多模态训练能够改进并扩展这些回路。
🎯 应用场景
该研究成果可应用于多模态信息检索、跨模态生成、以及需要理解和推理多模态数据的机器人等领域。通过理解多模态ICL的机制,可以设计更高效、更鲁棒的多模态学习系统,并提升模型在实际应用中的泛化能力。未来的研究可以进一步探索如何利用模态不对称性来优化多模态学习策略。
📄 摘要(原文)
Transformer-based multimodal large language models often exhibit in-context learning (ICL) abilities. Motivated by this phenomenon, we ask: how do transformers learn to associate information across modalities from in-context examples? We investigate this question through controlled experiments on small transformers trained on synthetic classification tasks, enabling precise manipulation of data statistics and model architecture. We begin by revisiting core principles of unimodal ICL in modern transformers. While several prior findings replicate, we find that Rotary Position Embeddings (RoPE) increases the data complexity threshold for ICL. Extending to the multimodal setting reveals a fundamental learning asymmetry: when pretrained on high-diversity data from a primary modality, surprisingly low data complexity in the secondary modality suffices for multimodal ICL to emerge. Mechanistic analysis shows that both settings rely on an induction-style mechanism that copies labels from matching in-context exemplars; multimodal training refines and extends these circuits across modalities. Our findings provide a mechanistic foundation for understanding multimodal ICL in modern transformers and introduce a controlled testbed for future investigation.