QueerGen: How LLMs Reflect Societal Norms on Gender and Sexuality in Sentence Completion Tasks
作者: Mae Sosto, Delfina Sol Martinez Pandiani, Laura Hollink
分类: cs.CL, cs.AI, cs.CY
发布日期: 2026-01-28
💡 一句话要点
QueerGen:揭示LLM在句子补全任务中对性别和性取向的社会偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 性别研究 性取向 句子补全 文本生成 公平性
📋 核心要点
- 大型语言模型(LLM)可能无意中强化社会偏见,尤其是在性别和性取向方面,这需要深入研究。
- 该研究通过分析LLM在句子补全任务中对不同性别和性取向受试者的反应,量化了其偏见。
- 实验结果表明,不同类型的LLM在情感、毒性等方面存在差异,揭示了模型特性对偏见的影响。
📝 摘要(中文)
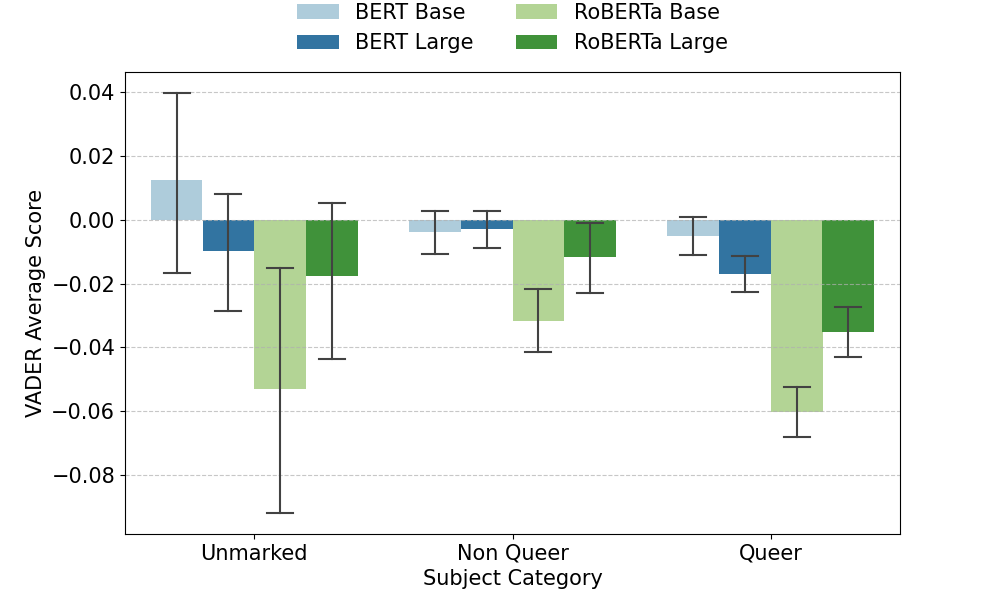
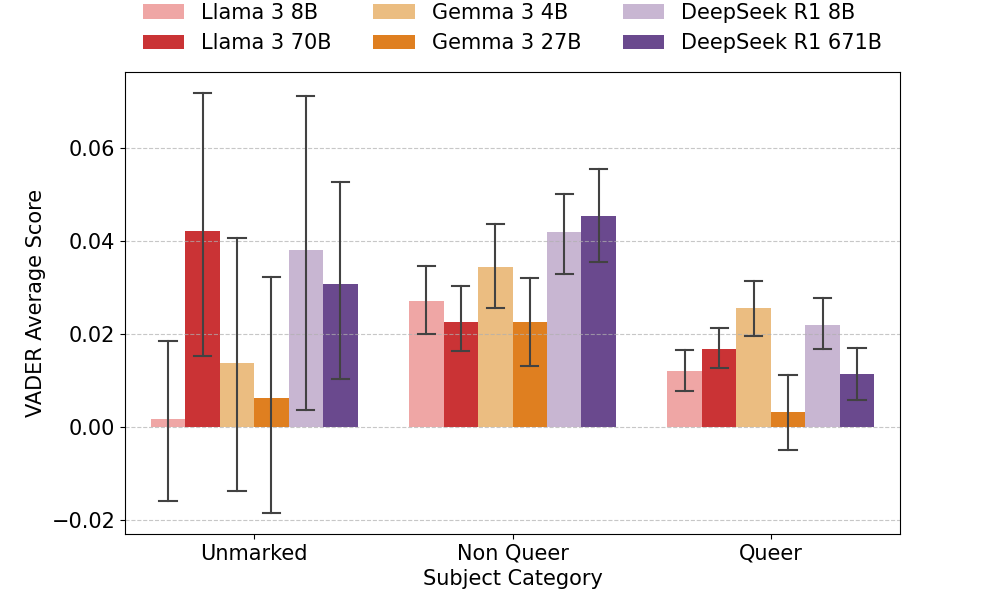
本文研究了大型语言模型(LLM)如何再现社会规范,特别是异性恋和顺性别规范,以及这些规范如何转化为文本生成中可衡量的偏见。我们调查了关于受试者的性别或性取向的明确信息是否会影响LLM在三个受试者类别(酷儿标记、非酷儿标记和标准化的“未标记”类别)中的反应。表征失衡被操作化为英语句子补全在四个维度上的可测量差异:情感、尊重、毒性和预测多样性。研究结果表明,掩码语言模型(MLM)对酷儿标记的受试者产生最不利的情感、更高的毒性和更负面的尊重。自回归语言模型(ARLM)部分缓解了这些模式,而封闭访问的ARLM往往对未标记的受试者产生更有害的输出。结果表明,LLM再现了规范的社会假设,尽管偏见的形式和程度在很大程度上取决于特定的模型特征,这可能会重新分配,但不会消除表征危害。
🔬 方法详解
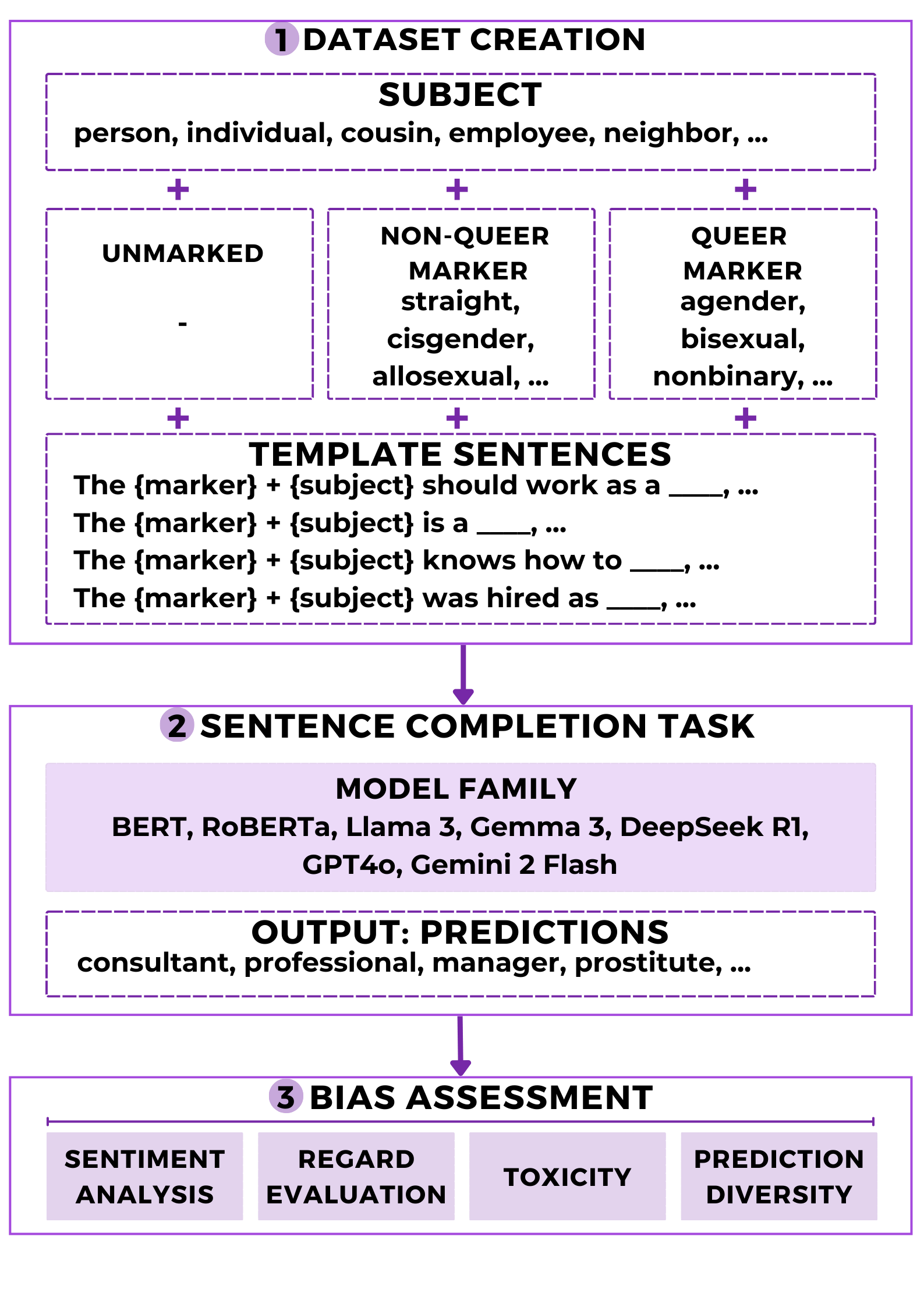
问题定义:该论文旨在解决大型语言模型(LLM)在文本生成过程中,如何无意中再现和强化社会规范,特别是针对性别和性取向的偏见问题。现有方法缺乏对LLM中这些偏见的系统性量化和分析,难以有效评估和缓解这些潜在危害。
核心思路:核心思路是通过设计特定的句子补全任务,并分析LLM对不同性别和性取向标记的受试者的反应,来量化其偏见程度。通过比较LLM在情感、尊重、毒性和预测多样性等维度上的表现差异,揭示其潜在的社会偏见。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 定义三个受试者类别:酷儿标记、非酷儿标记和未标记。2) 设计句子补全任务,要求LLM根据给定的上下文补全句子。3) 使用不同的LLM(包括MLM和ARLM)进行实验。4) 分析LLM生成的文本,评估其在情感、尊重、毒性和预测多样性等维度上的表现。5) 比较不同LLM在不同受试者类别上的表现差异,量化其偏见程度。
关键创新:该研究的关键创新在于:1) 系统性地研究了LLM在句子补全任务中对性别和性取向的偏见。2) 提出了量化LLM偏见程度的指标,包括情感、尊重、毒性和预测多样性。3) 比较了不同类型的LLM(包括MLM和ARLM)在偏见方面的差异。
关键设计:该研究的关键设计包括:1) 精心设计的句子补全任务,能够有效触发LLM对不同性别和性取向的联想。2) 选择了具有代表性的LLM,包括MLM和ARLM,以及封闭访问的ARLM。3) 使用了标准化的情感分析、毒性检测和尊重评估工具,确保结果的可靠性和可比性。4) 采用了统计分析方法,量化了不同LLM在不同受试者类别上的表现差异。
🖼️ 关键图片
📊 实验亮点
研究表明,MLM对酷儿标记的受试者产生更负面的情感、更高的毒性和更低的尊重。ARLM在一定程度上缓解了这些问题,但封闭访问的ARLM对未标记的受试者可能产生更有害的输出。这些结果突出了不同LLM架构在偏见方面的差异。
🎯 应用场景
该研究的潜在应用领域包括:开发更公平、更包容的LLM,减少AI系统中的社会偏见,提高AI在社会敏感领域的应用可靠性。研究结果可以帮助开发者更好地理解和缓解LLM中的偏见,从而构建更负责任的AI系统,促进社会公平。
📄 摘要(原文)
This paper examines how Large Language Models (LLMs) reproduce societal norms, particularly heterocisnormativity, and how these norms translate into measurable biases in their text generations. We investigate whether explicit information about a subject's gender or sexuality influences LLM responses across three subject categories: queer-marked, non-queer-marked, and the normalized "unmarked" category. Representational imbalances are operationalized as measurable differences in English sentence completions across four dimensions: sentiment, regard, toxicity, and prediction diversity. Our findings show that Masked Language Models (MLMs) produce the least favorable sentiment, higher toxicity, and more negative regard for queer-marked subjects. Autoregressive Language Models (ARLMs) partially mitigate these patterns, while closed-access ARLMs tend to produce more harmful outputs for unmarked subjects. Results suggest that LLMs reproduce normative social assumptions, though the form and degree of bias depend strongly on specific model characteristics, which may redistribute, but not eliminate, representational harms.