Efficient Multimodal Planning Agent for Visual Question-Answering
作者: Zhuo Chen, Xinyu Geng, Xinyu Wang, Yong Jiang, Zhen Zhang, Pengjun Xie, Kewei Tu
分类: cs.CL
发布日期: 2026-01-28
💡 一句话要点
提出多模态规划Agent,高效解决视觉问答任务中的多阶段检索增强生成问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 多模态学习 检索增强生成 强化学习 规划Agent 效率优化 知识密集型VQA
📋 核心要点
- 现有VQA方法依赖多阶段mRAG流程,效率低下,存在冗余计算和昂贵的工具调用。
- 提出多模态规划Agent,动态分解mRAG流程,智能决策每一步骤的必要性,优化效率与效果。
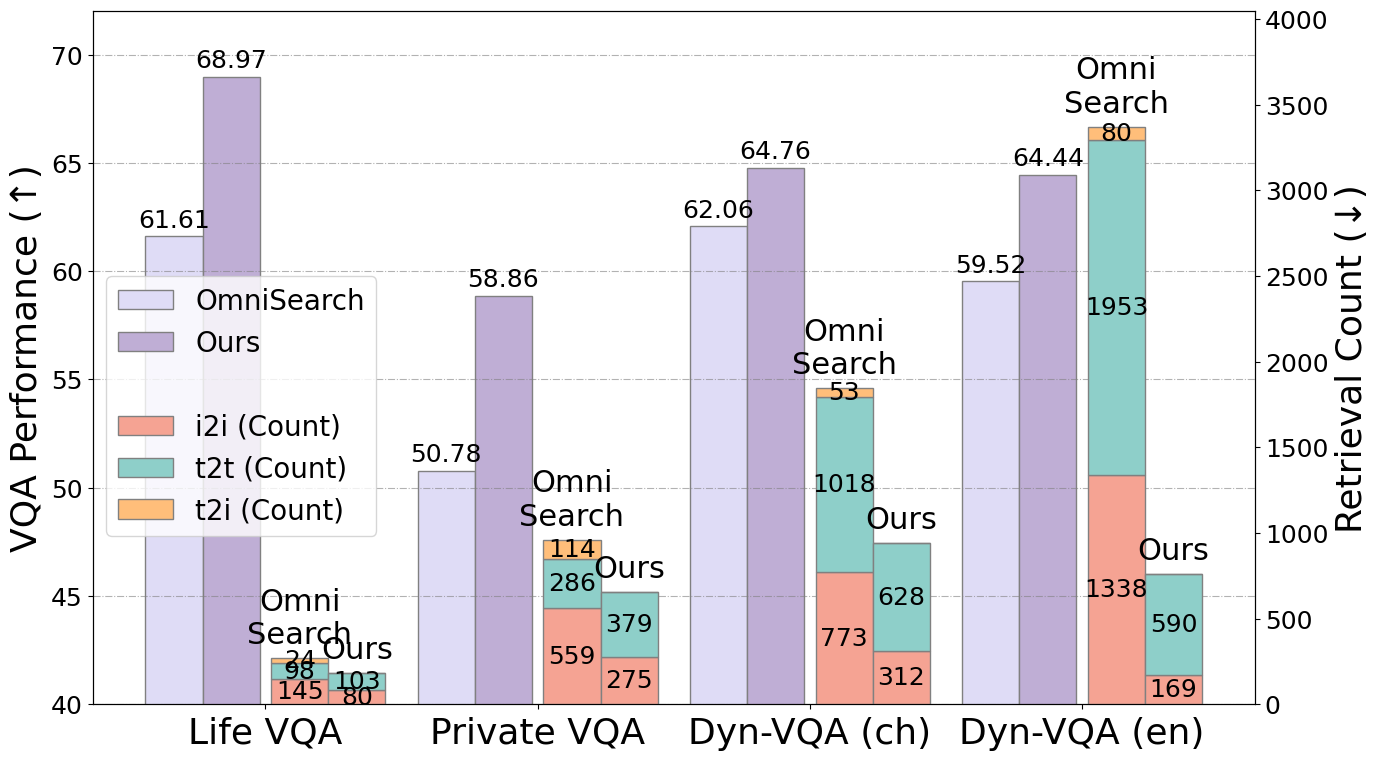
- 实验结果表明,该Agent可减少60%以上的搜索时间,并在多个数据集上优于现有基线方法。
📝 摘要(中文)
视觉问答(VQA)是一项具有挑战性的多模态任务,需要整合视觉和文本信息以生成准确的回答。多模态检索增强生成(mRAG)通过提供图像和文本方面的更多证据,在增强VQA系统方面显示出前景。然而,解决VQA查询(尤其是知识密集型查询)的默认流程通常依赖于具有内在依赖性的多阶段mRAG流程。为了在保持VQA任务性能的同时缓解效率限制,本文提出了一种训练多模态规划Agent的方法,该Agent动态分解mRAG流程以解决VQA任务。我们的方法通过训练Agent智能地确定每个mRAG步骤的必要性,从而优化效率和效果之间的权衡。实验表明,与现有方法相比,该Agent可以帮助减少冗余计算,将搜索时间缩短60%以上,并减少昂贵的工具调用。同时,实验表明,我们的方法在六个不同的数据集上的平均表现优于所有基线,包括Deep Research agent和一个精心设计的基于prompt的方法。代码将会开源。
🔬 方法详解
问题定义:论文旨在解决视觉问答(VQA)任务中,传统多模态检索增强生成(mRAG)方法效率低下的问题。现有的mRAG方法通常采用多阶段pipeline,每个阶段都可能进行不必要的检索和计算,导致冗余和资源浪费,尤其是在处理知识密集型VQA问题时,这种问题更加突出。
核心思路:论文的核心思路是引入一个多模态规划Agent,该Agent能够动态地决定mRAG pipeline中哪些步骤是必要的,从而避免不必要的计算。Agent通过学习来预测每个步骤的收益,并根据收益选择执行或跳过该步骤,从而优化整体效率。
技术框架:整体框架包含一个多模态规划Agent和一个可分解的mRAG pipeline。Agent接收VQA问题和相关视觉信息作为输入,输出一个动作序列,该序列指示mRAG pipeline中哪些步骤需要执行。mRAG pipeline包含多个可选择的检索和生成模块,例如图像检索、文本检索、知识库查询等。Agent根据当前状态和历史动作,动态地选择执行哪些模块,并将结果反馈给Agent,形成一个循环决策过程。
关键创新:最重要的技术创新点在于引入了规划Agent来动态控制mRAG pipeline的执行流程。与传统的静态pipeline相比,该方法能够根据具体问题和当前状态,自适应地调整执行策略,从而避免不必要的计算,提高效率。Agent的学习目标是最大化VQA任务的准确率,同时最小化计算成本。
关键设计:Agent通常使用强化学习进行训练,状态空间包括VQA问题、视觉信息、历史动作等,动作空间包括执行或跳过mRAG pipeline中的每个步骤。奖励函数的设计至关重要,通常包括VQA任务的准确率奖励和计算成本惩罚。具体的网络结构可以采用Transformer等模型,用于编码多模态信息和预测动作。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的多模态规划Agent能够显著提高VQA任务的效率。与现有方法相比,该Agent可以将搜索时间缩短60%以上,并减少昂贵的工具调用。在六个不同的数据集上,该方法平均优于所有基线方法,包括Deep Research agent和一个精心设计的基于prompt的方法,证明了其有效性和泛化能力。
🎯 应用场景
该研究成果可应用于智能客服、图像搜索、教育辅助等领域。例如,在智能客服中,可以利用该方法快速准确地回答用户提出的关于图像的问题。在教育领域,可以帮助学生理解图像内容,并提供相关的知识背景。该方法还可以扩展到其他多模态任务中,例如视频问答、跨模态检索等,具有广阔的应用前景。
📄 摘要(原文)
Visual Question-Answering (VQA) is a challenging multimodal task that requires integrating visual and textual information to generate accurate responses. While multimodal Retrieval-Augmented Generation (mRAG) has shown promise in enhancing VQA systems by providing more evidence on both image and text sides, the default procedure that addresses VQA queries, especially the knowledge-intensive ones, often relies on multi-stage pipelines of mRAG with inherent dependencies. To mitigate the inefficiency limitations while maintaining VQA task performance, this paper proposes a method that trains a multimodal planning agent, dynamically decomposing the mRAG pipeline to solve the VQA task. Our method optimizes the trade-off between efficiency and effectiveness by training the agent to intelligently determine the necessity of each mRAG step. In our experiments, the agent can help reduce redundant computations, cutting search time by over 60\% compared to existing methods and decreasing costly tool calls. Meanwhile, experiments demonstrate that our method outperforms all baselines, including a Deep Research agent and a carefully designed prompt-based method, on average over six various datasets. Code will be released.