A Dialectic Pipeline for Improving LLM Robustness
作者: Sara Candussio
分类: cs.CL, cs.MA
发布日期: 2026-01-28
💡 一句话要点
提出一种辩证pipeline,通过自对话提升LLM的鲁棒性和输出质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性 自对话 辩证pipeline 幻觉抑制
📋 核心要点
- 现有方法如微调或训练专用验证器,计算成本高昂且限制了模型的知识领域。
- 论文提出辩证pipeline,通过LLM自对话反思和纠正错误,提升答案质量。
- 实验表明,该pipeline显著优于标准模型和Chain-of-Thought prompting。
📝 摘要(中文)
为了确保大规模应用,评估语言模型如何减少幻觉并提高输出质量至关重要。然而,在特定领域数据上进行微调或训练单独的ad hoc验证器等方法需要大量的计算资源(对于许多用户应用来说不可行),并且将模型限制在特定的知识领域。本研究提出了一种辩证pipeline,通过自对话来反思和纠正初步的错误答案,从而在保持LLM泛化能力的同时提高答案的质量。我们通过在不同的数据集和不同系列的模型上测试所提出的方法,对不同的pipeline设置进行了实验。所有pipeline阶段都使用相关的上下文(在oracle-RAG设置中)进行丰富,并对上下文的总结或过滤的影响进行了研究。结果表明,我们提出的辩证pipeline能够显著优于标准模型答案,并且始终比仅使用Chain-of-Thought prompting获得更高的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成文本时出现的幻觉问题,以及提高LLM输出质量的问题。现有方法,如微调和训练专用验证器,存在计算资源需求高、泛化能力受限等痛点。这些方法难以在资源有限的场景下应用,并且容易过拟合到特定领域的数据。
核心思路:论文的核心思路是利用LLM的自对话能力,构建一个辩证的pipeline。通过让LLM对自身的初步答案进行反思和批判,从而发现并纠正潜在的错误。这种方法旨在提高LLM的鲁棒性和输出质量,同时保持其泛化能力。
技术框架:该辩证pipeline包含多个阶段,具体流程如下:1) LLM生成初步答案;2) LLM对初步答案进行反思,识别潜在的错误或不确定性;3) LLM基于反思结果,生成修正后的答案;4) 对修正后的答案进行评估,选择最优答案。在pipeline的每个阶段,都使用相关的上下文信息(通过oracle-RAG)来增强LLM的推理能力。论文还研究了上下文信息的总结和过滤对pipeline性能的影响。
关键创新:该论文的关键创新在于提出了一种基于自对话的辩证pipeline,用于提高LLM的鲁棒性和输出质量。与传统的微调或训练专用验证器的方法相比,该方法不需要大量的计算资源,并且能够保持LLM的泛化能力。此外,该方法利用LLM自身的知识和推理能力,避免了对外部知识库的依赖。
关键设计:论文中涉及的关键设计包括:1) 如何设计有效的自对话prompt,引导LLM进行反思和批判;2) 如何选择合适的评估指标,对修正后的答案进行评估;3) 如何利用oracle-RAG获取相关的上下文信息;4) 如何对上下文信息进行总结和过滤,以提高pipeline的效率。
🖼️ 关键图片
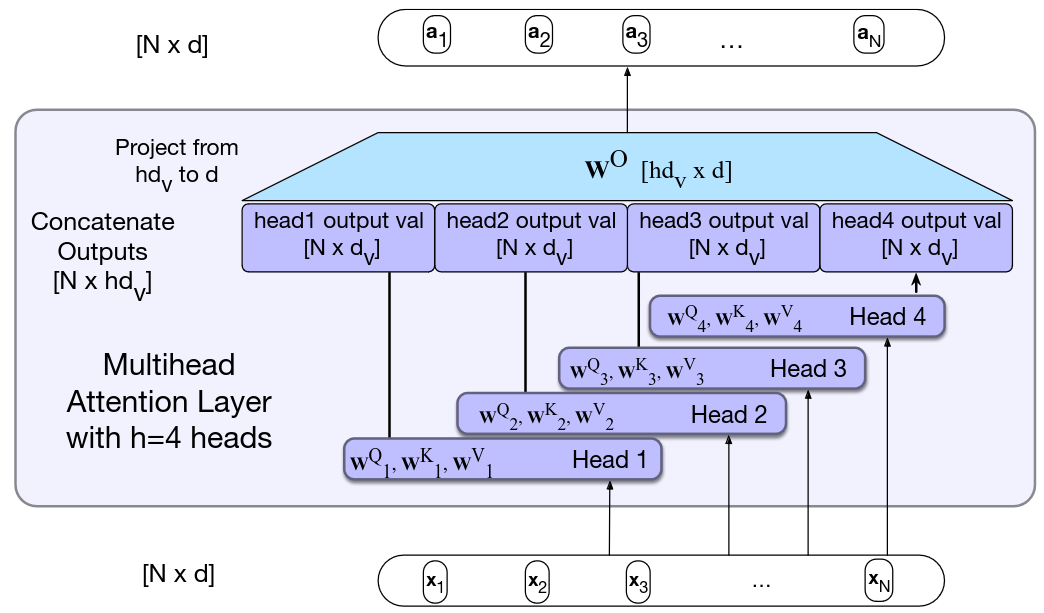
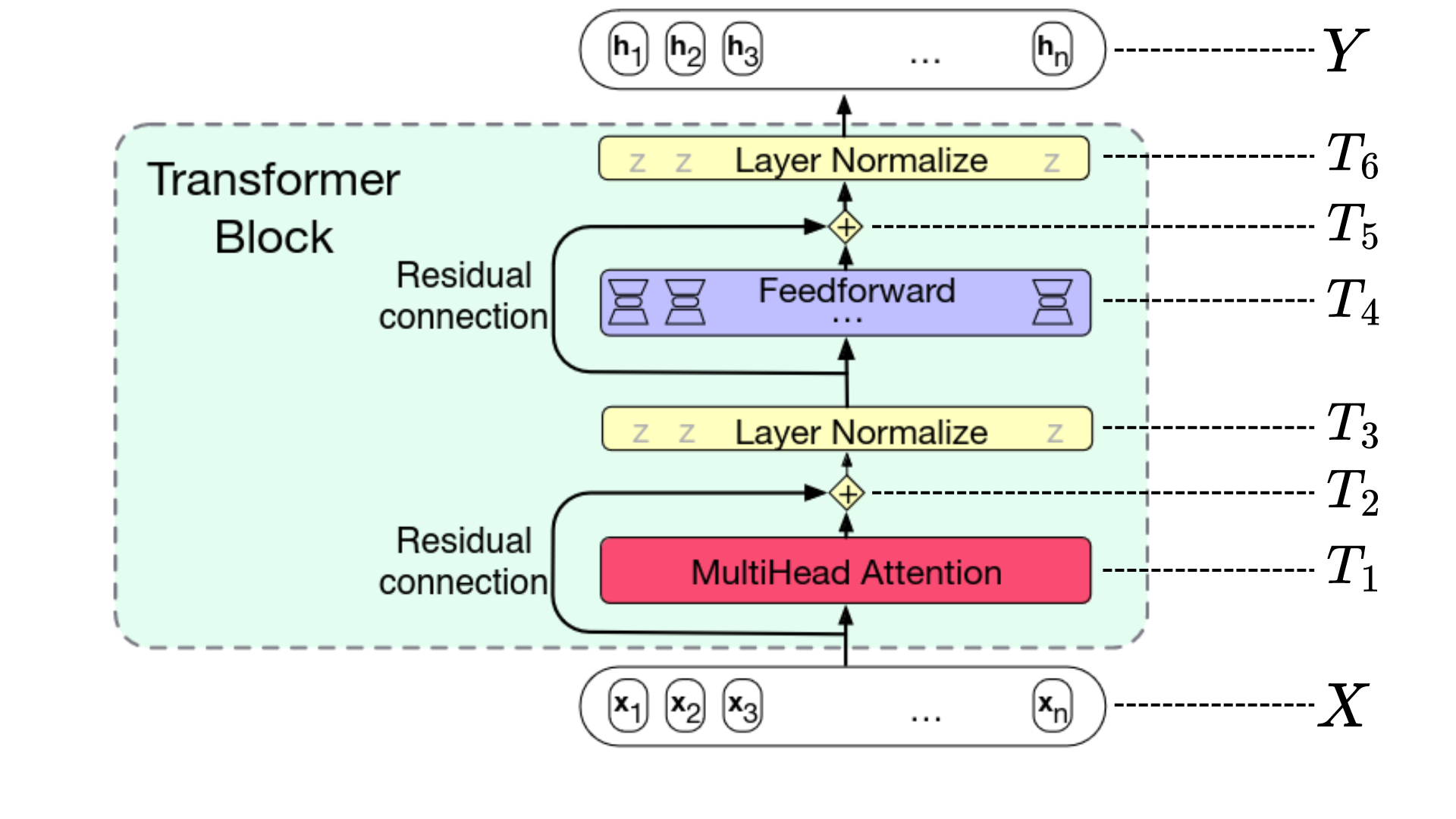
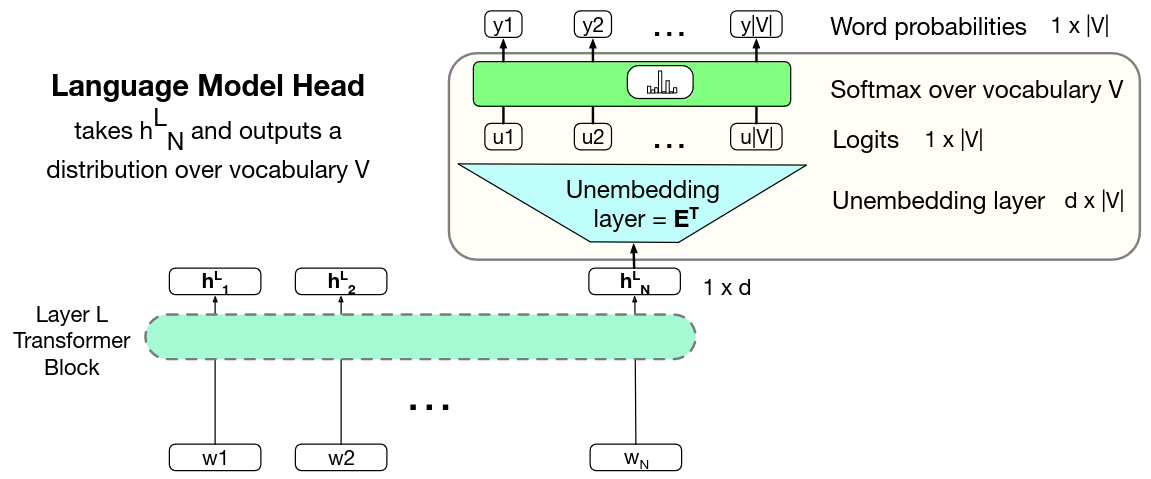
📊 实验亮点
实验结果表明,该辩证pipeline能够显著优于标准模型答案,并且始终比仅使用Chain-of-Thought prompting获得更高的性能。具体的性能提升幅度未知,但论文强调了其显著性。该pipeline在不同的数据集和不同系列的模型上都表现出良好的效果,证明了其泛化能力。
🎯 应用场景
该研究成果可应用于各种需要高质量文本生成的场景,例如智能客服、内容创作、教育辅导等。通过提高LLM的鲁棒性和输出质量,可以减少错误信息的传播,提高用户满意度,并促进LLM在更广泛领域的应用。未来,该方法有望与其他技术相结合,进一步提升LLM的性能和可靠性。
📄 摘要(原文)
Assessing ways in which Language Models can reduce their hallucinations and improve the outputs' quality is crucial to ensure their large-scale use. However, methods such as fine-tuning on domain-specific data or the training of a separate \textit{ad hoc} verifier require demanding computational resources (not feasible for many user applications) and constrain the models to specific fields of knowledge. In this thesis, we propose a dialectic pipeline that preserves LLMs' generalization abilities while improving the quality of its answer via self-dialogue, enabling it to reflect upon and correct tentative wrong answers. We experimented with different pipeline settings, testing our proposed method on different datasets and on different families of models. All the pipeline stages are enriched with the relevant context (in an oracle-RAG setting) and a study on the impact of its summarization or its filtering is conducted. We find that our proposed dialectic pipeline is able to outperform by significative margins the standard model answers and that it consistently achieves higher performances than Chain-of-Thought only prompting.