AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
作者: Kaiyuan Chen, Qimin Wu, Taiyu Hou, Tianhao Tang, Xueyu Hu, Yuchen Hou, Bikun Li, Chengming Qian, Guoyin Wang, Haolin Chen, Haotong Tian, Haoye Zhang, Haoyu Bian, Hongbing Pan, Hongkang Zhang, Hongyi Zhou, Jiaqi Cai, Jiewu Rao, Jiyuan Ren, Keduan Huang, Lucia Zhu Huang, Mingyu Yuan, Naixu Guo, Qicheng Tang, Qinyan Zhang, Shuai Chen, Siheng Chen, Ting Ting Li, Xiaoxing Guo, Yaocheng Zuo, Yaoqi Guo, Yinan Wang, Yinzhou Yu, Yize Wang, Yuan Jiang, Yuan Tian, Yuanshuo Zhang, Yuxuan Liu, Yvette Yan Zeng, Zenyu Shan, Zihan Yin, Xiaobo Hu, Yang Liu, Yixin Ren, Yuan Gong
分类: cs.CL
发布日期: 2026-01-28
备注: 17 pages, 8 figures
💡 一句话要点
提出AgentIF-OneDay基准,评估通用AI Agent在日常场景下的任务级指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI Agent 指令遵循 日常场景 基准测试 自然语言处理
📋 核心要点
- 现有AI Agent评估侧重任务难度,忽略了日常任务的多样性,导致通用用户对其能力感知有限。
- AgentIF-OneDay通过模拟日常工作流,评估Agent理解指令、处理附件和迭代改进的能力。
- 实验表明,基于API和Agent RL的Agent产品表现领先,LLM API已具备Agent能力。
📝 摘要(中文)
本文提出了AgentIF-OneDay,旨在评估通用AI Agent在日常场景中利用自然语言指令完成多样化任务的能力。现有评估侧重于增加任务难度,而忽略了覆盖广泛用户日常工作、生活和学习活动所需的Agent任务多样性。AgentIF-OneDay包含开放工作流执行、潜在指令和迭代改进三个用户中心类别,要求Agent不仅通过对话解决问题,还要理解各种附件类型并交付实际的文件结果。该基准包含104个任务,共767个评分点。使用Gemini-3-Pro,通过实例级规则和结合LLM验证与人工判断的评估流程,实现了80.1%的一致性。对四个领先的通用AI Agent进行了基准测试,发现基于API构建的Agent产品和基于Agent RL的ChatGPT Agent处于第一梯队。领先的LLM API和开源模型已经内化了Agent能力,使AI应用团队能够开发尖端的Agent产品。
🔬 方法详解
问题定义:现有AI Agent的评估主要集中在提高任务的难度,而忽略了日常生活中任务的多样性。这意味着即使AI在特定领域表现出色,普通用户也可能难以感受到其在日常生活中的实用性。现有方法缺乏对Agent理解复杂工作流程、处理各种附件类型以及进行迭代改进的能力的全面评估。
核心思路:AgentIF-OneDay的核心思路是创建一个更贴近用户日常生活的任务环境,通过自然语言指令驱动Agent完成多样化的任务。它强调Agent不仅要解决问题,还要理解隐式指令、处理文件,并根据反馈进行迭代改进,从而更全面地评估Agent的实用性和泛化能力。
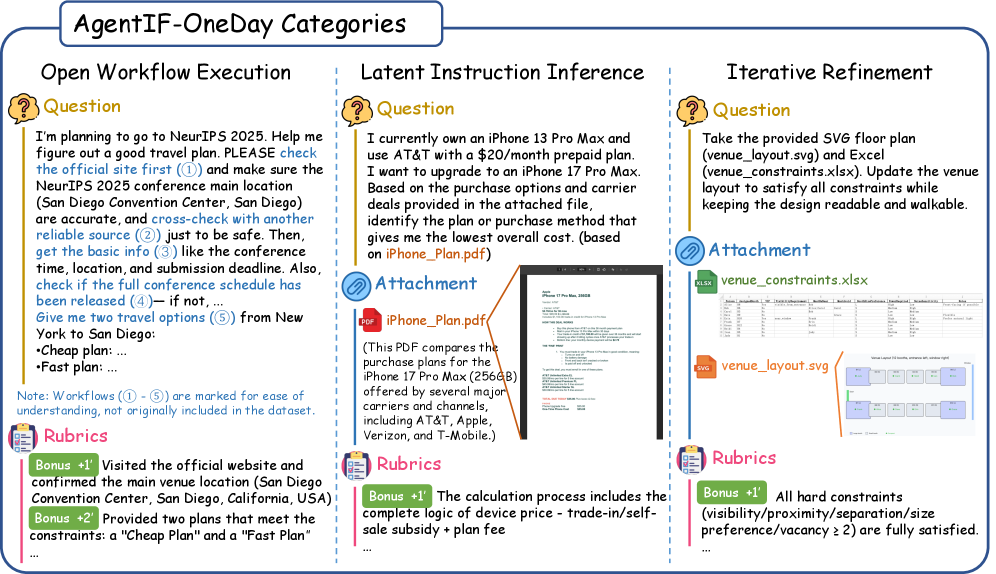
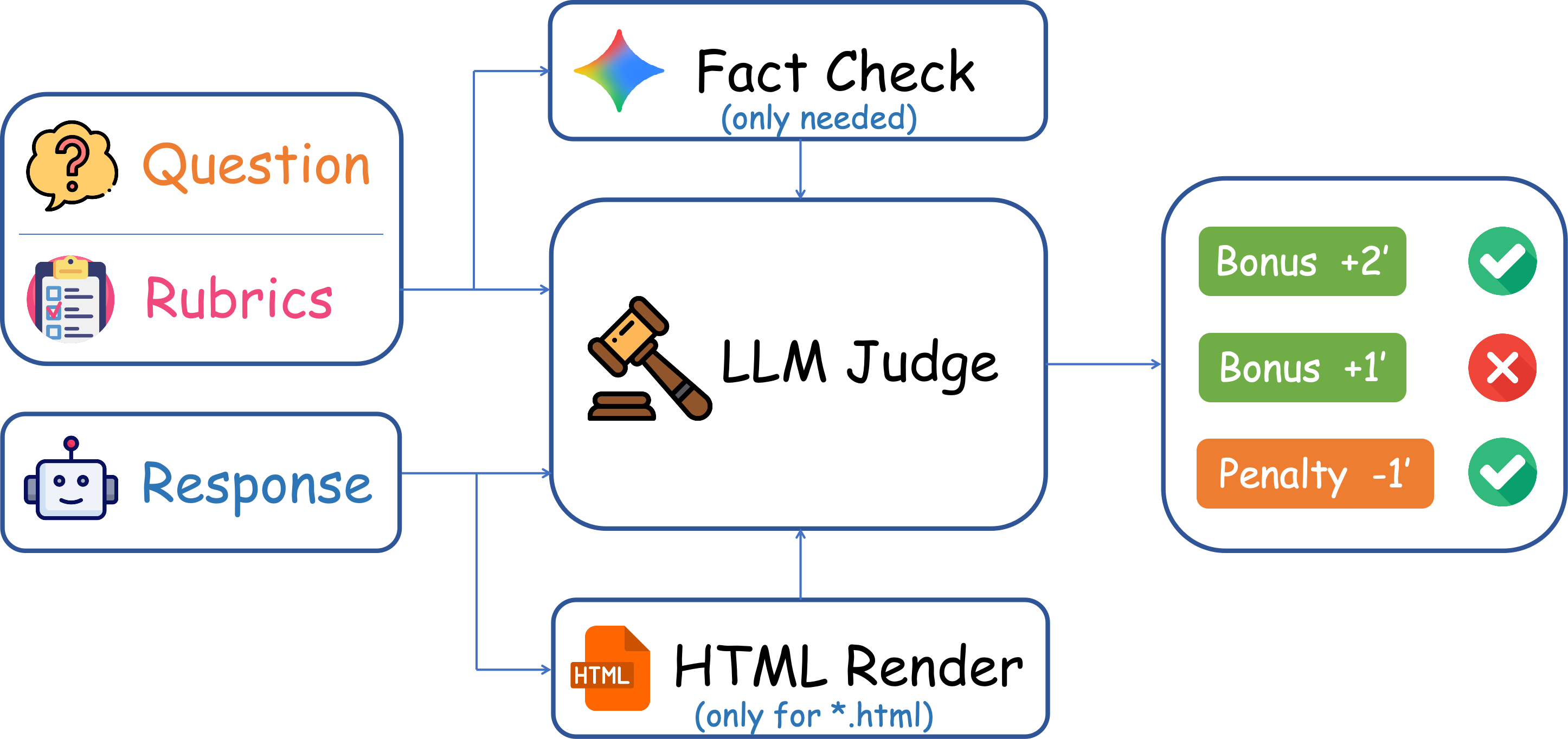
技术框架:AgentIF-OneDay基准测试包含三个主要类别:开放工作流执行(Open Workflow Execution),评估Agent遵循明确和复杂工作流程的能力;潜在指令(Latent Instruction),要求Agent从附件中推断隐含指令;迭代改进(Iterative Refinement),涉及修改或扩展正在进行的工作。评估流程结合了基于LLM的验证和人工判断,以提高评估的准确性和可靠性。
关键创新:AgentIF-OneDay的关键创新在于其任务设计的用户中心性,以及评估指标的细粒度。它不仅关注Agent能否完成任务,还关注Agent完成任务的方式是否符合用户的期望。此外,结合LLM和人工判断的评估流程,提高了评估的客观性和准确性。
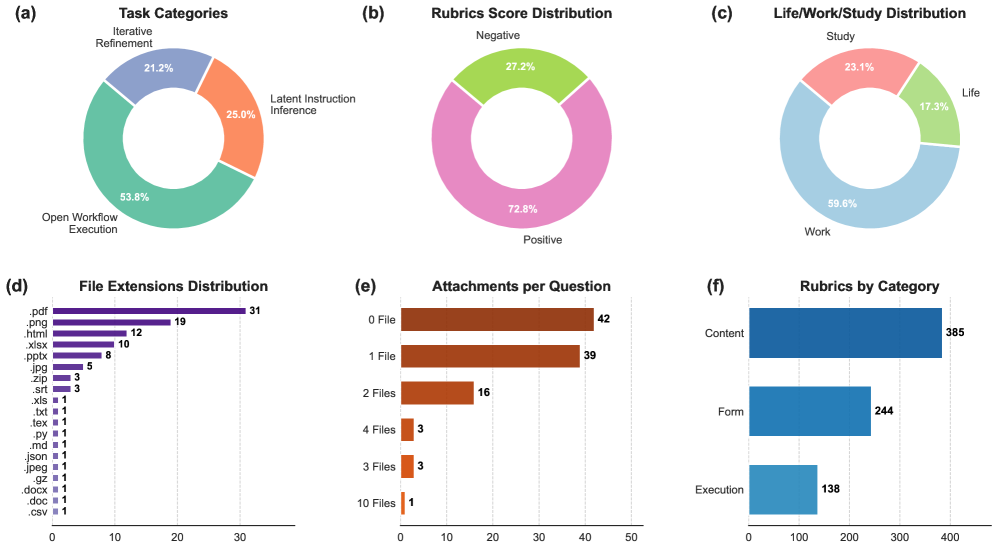
关键设计:AgentIF-OneDay包含104个任务,共767个评分点。评估流程使用实例级规则,并结合LLM(Gemini-3-Pro)验证与人工判断。通过这种方式,实现了80.1%的一致性。任务设计涵盖了日常工作、生活和学习的各个方面,例如撰写报告、整理文件、安排日程等。
🖼️ 关键图片
📊 实验亮点
AgentIF-OneDay基准测试结果显示,基于API构建的Agent产品和基于Agent RL的ChatGPT Agent表现领先。这表明,通过API集成和强化学习等技术,可以有效提升Agent的性能。此外,领先的LLM API和开源模型已经内化了Agent能力,为AI应用开发提供了更强大的基础。
🎯 应用场景
AgentIF-OneDay可用于评估和改进通用AI Agent在日常场景中的表现,推动AI技术在办公自动化、智能助手、教育辅助等领域的应用。通过该基准,可以更好地了解AI Agent的优势和局限性,从而开发出更实用、更智能的AI产品,提升用户体验。
📄 摘要(原文)
The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.