PEARL: Plan Exploration and Adaptive Reinforcement Learning for Multihop Tool Use
作者: Qihao Wang, Mingzhe Lu, Jiayue Wu, Yue Hu, Yanbing Liu
分类: cs.CL
发布日期: 2026-01-28
备注: Accepted to PRICAI25
💡 一句话要点
PEARL:探索式规划与自适应强化学习提升多步工具使用能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 强化学习 规划 多步推理
📋 核心要点
- 现有LLM在复杂工具使用中存在规划能力弱、易产生幻觉、参数生成错误等问题,导致多轮交互鲁棒性差。
- PEARL框架通过离线探索学习工具使用模式,在线利用强化学习训练规划器,从而提升LLM的工具使用能力。
- 实验结果表明,PEARL在ToolHop基准测试上取得了56.5%的成功率,显著优于现有方法,并降低了调用错误率。
📝 摘要(中文)
大型语言模型(LLM)在外部工具使用方面展现出巨大潜力,但在复杂的多轮工具调用中面临显著挑战,如规划能力弱、工具幻觉、参数生成错误以及交互鲁棒性不足。为了解决这些问题,我们提出了PEARL,一个旨在增强LLM规划和执行复杂工具使用的新框架。PEARL采用两阶段方法:离线阶段,智能体探索工具以学习有效的用法模式和失败条件;在线阶段,通过分组相对策略优化(GRPO)训练一个专用规划器,并使用精心设计的奖励函数为规划质量提供明确的信号。在ToolHop和T-Eval基准测试上的实验表明,PEARL显著优于现有方法,在ToolHop上实现了56.5%的最新成功率,同时保持了较低的调用错误率。我们的工作标志着在解决工具使用复杂规划挑战方面的一个关键进展,有助于开发更强大和可靠的基于LLM的智能体。
🔬 方法详解
问题定义:现有大型语言模型在多步工具使用任务中,面临规划能力不足的问题。具体表现为:难以生成合理的工具调用序列,容易产生“工具幻觉”(即调用不存在的工具),生成的参数不正确,以及在多轮交互中鲁棒性较差。这些问题限制了LLM在需要复杂工具调用的实际场景中的应用。
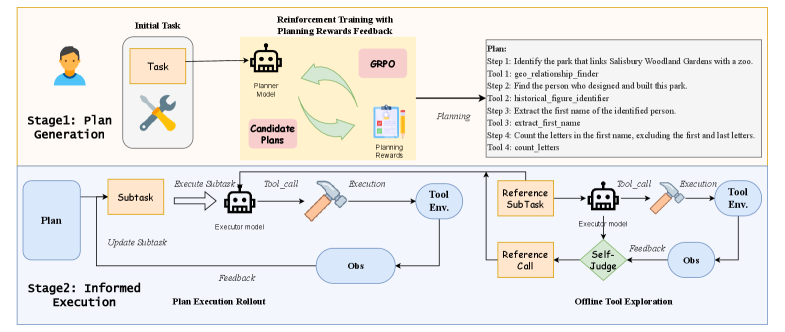
核心思路:PEARL的核心思路是将工具使用过程分解为离线探索和在线强化学习两个阶段。离线探索阶段用于学习工具的有效使用模式和失败条件,为后续的在线强化学习提供先验知识。在线强化学习阶段则专注于训练一个专门的规划器,使其能够根据当前状态选择合适的工具和参数,从而完成任务。这种分解能够有效地利用数据,并提高规划器的学习效率和泛化能力。
技术框架:PEARL框架包含两个主要阶段:离线探索阶段和在线强化学习阶段。在离线探索阶段,智能体通过与环境交互,探索各种工具的使用方式,并记录成功和失败的案例。这些案例被用于构建一个工具使用知识库。在线强化学习阶段,一个专门的规划器被训练,该规划器接收当前状态作为输入,并输出一个工具调用序列。规划器的训练采用分组相对策略优化(GRPO)算法,并使用精心设计的奖励函数来指导学习。奖励函数不仅考虑了任务的完成情况,还考虑了规划的质量,例如工具调用的合理性和参数的正确性。
关键创新:PEARL的关键创新在于其两阶段学习框架和分组相对策略优化(GRPO)算法的应用。两阶段学习框架能够有效地利用数据,并提高规划器的学习效率和泛化能力。GRPO算法则能够更好地处理复杂的奖励函数,并提高规划器的探索能力。此外,PEARL还引入了工具使用知识库,用于存储工具的使用模式和失败条件,从而提高规划器的鲁棒性。
关键设计:PEARL的关键设计包括:1) 离线探索策略:采用随机策略或基于规则的策略来探索工具的使用方式。2) 奖励函数:设计一个综合考虑任务完成情况和规划质量的奖励函数,例如,对正确的工具调用和参数生成给予正向奖励,对错误的工具调用和参数生成给予负向奖励。3) 分组相对策略优化(GRPO):将智能体分成多个组,并根据组内的相对表现来更新策略,从而提高探索能力。4) 工具使用知识库:存储工具的使用模式和失败条件,用于指导规划器的学习。
🖼️ 关键图片
📊 实验亮点
PEARL在ToolHop基准测试上取得了56.5%的成功率,相较于现有最佳方法有显著提升。同时,PEARL保持了较低的工具调用错误率,表明其在提高成功率的同时,也保证了工具使用的可靠性。实验结果充分验证了PEARL框架的有效性和优越性。
🎯 应用场景
PEARL框架可应用于需要复杂工具调用的各种场景,例如智能客服、自动化运维、科学研究等。通过提升LLM的工具使用能力,可以实现更智能、更高效的自动化任务处理,降低人工成本,提高工作效率。未来,该研究有望推动LLM在实际应用中的更广泛应用。
📄 摘要(原文)
Large Language Models show great potential with external tools, but face significant challenges in complex, multi-turn tool invocation. They often exhibit weak planning, tool hallucination, erroneous parameter generation, and struggle with robust interaction. To tackle these issues, we present PEARL, a novel framework to enhance LLM planning and execution for sophisticated tool use. PEARL adopts a two-stage approach: an offline phase where the agent explores tools to learn valid usage patterns and failure conditions, and an online reinforcement learning phase. In the online phase, a dedicated Planner is trained via group Relative Policy Optimization (GRPO) with a carefully designed reward function that provides distinct signals for planning quality. Experiments on the ToolHop and T-Eval benchmarks show PEARL significantly outperforms existing methods, achieving a new state-of-the-art success rate of \textbf{56.5\%} on ToolHop while maintaining a low invocation error rate. Our work marks a key advance in addressing the complex planning challenges of tool use, contributing to the development of more robust and reliable LLM-based agents.