SpeechMapper: Speech-to-text Embedding Projector for LLMs
作者: Biswesh Mohapatra, Marcely Zanon Boito, Ioan Calapodescu
分类: cs.CL
发布日期: 2026-01-28
备注: Accepted to ICASSP 2026
💡 一句话要点
SpeechMapper:一种高效的语音到文本嵌入投影方法,用于连接语音基础模型和LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音LLM 语音翻译 口语问答 指令微调 嵌入投影 语音识别 多模态学习
📋 核心要点
- 现有语音LLM通过投影层连接语音基础模型和LLM,但这种方法计算密集且容易过拟合。
- SpeechMapper的核心思想是先独立预训练一个语音到文本嵌入的映射器,再将其高效连接到目标LLM。
- 实验表明,SpeechMapper在语音翻译和口语问答任务上表现出色,且所需数据和计算资源更少。
📝 摘要(中文)
本文提出SpeechMapper,一种经济高效的语音到LLM嵌入训练方法,旨在缓解过拟合,从而实现更鲁棒和更具泛化能力的模型。该模型首先在低成本硬件上进行预训练,无需LLM参与,然后通过一个简短的1K步指令微调(IT)阶段高效地连接到目标LLM。通过在语音翻译和口语问答上的实验,我们展示了SpeechMapper预训练模块的多功能性,并展示了任务无关IT(一种不针对目标任务进行训练的基于ASR的自适应策略)和任务特定IT的结果。在任务无关设置中,Speechmapper可以与IWSLT25中最佳的指令跟随语音LLM相媲美,尽管从未在这些任务上进行过训练;而在任务特定设置中,它在许多数据集上优于该模型,同时需要更少的数据和计算资源。总而言之,SpeechMapper为高效、通用的语音-LLM集成提供了一种实用且可扩展的方法,无需大规模IT。
🔬 方法详解
问题定义:现有语音LLM通常直接将语音基础模型与LLM连接,并在语音指令数据上联合训练所有组件。这种方法计算成本高昂,并且容易出现任务和prompt过拟合,导致模型泛化能力差。
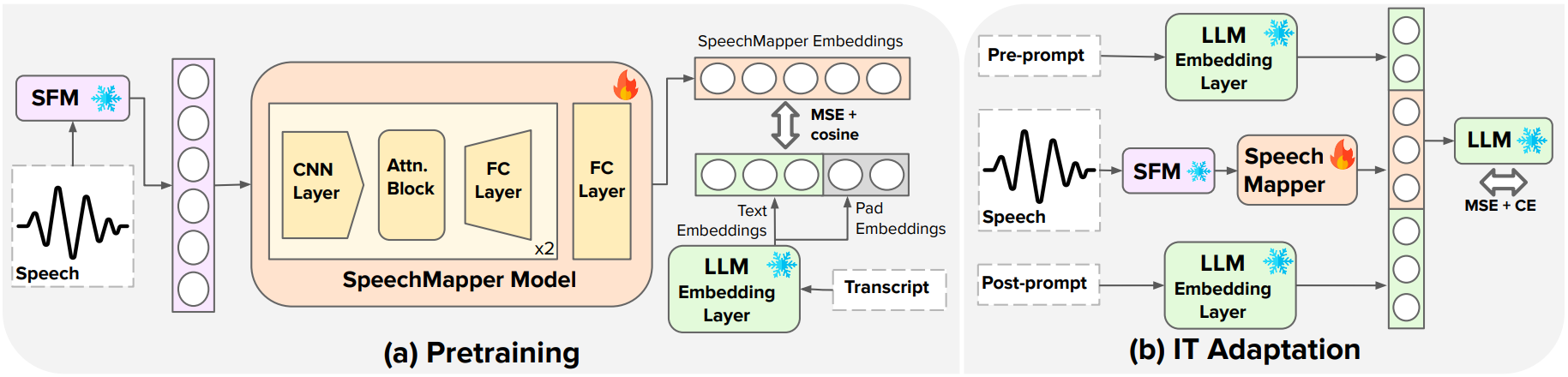
核心思路:SpeechMapper的核心思路是将语音特征映射到LLM的嵌入空间,从而实现语音和文本的有效对齐。通过预训练一个独立的映射模块,可以避免直接联合训练带来的计算负担和过拟合风险。预训练后的映射模块可以快速适配到不同的LLM,实现高效的语音-LLM集成。
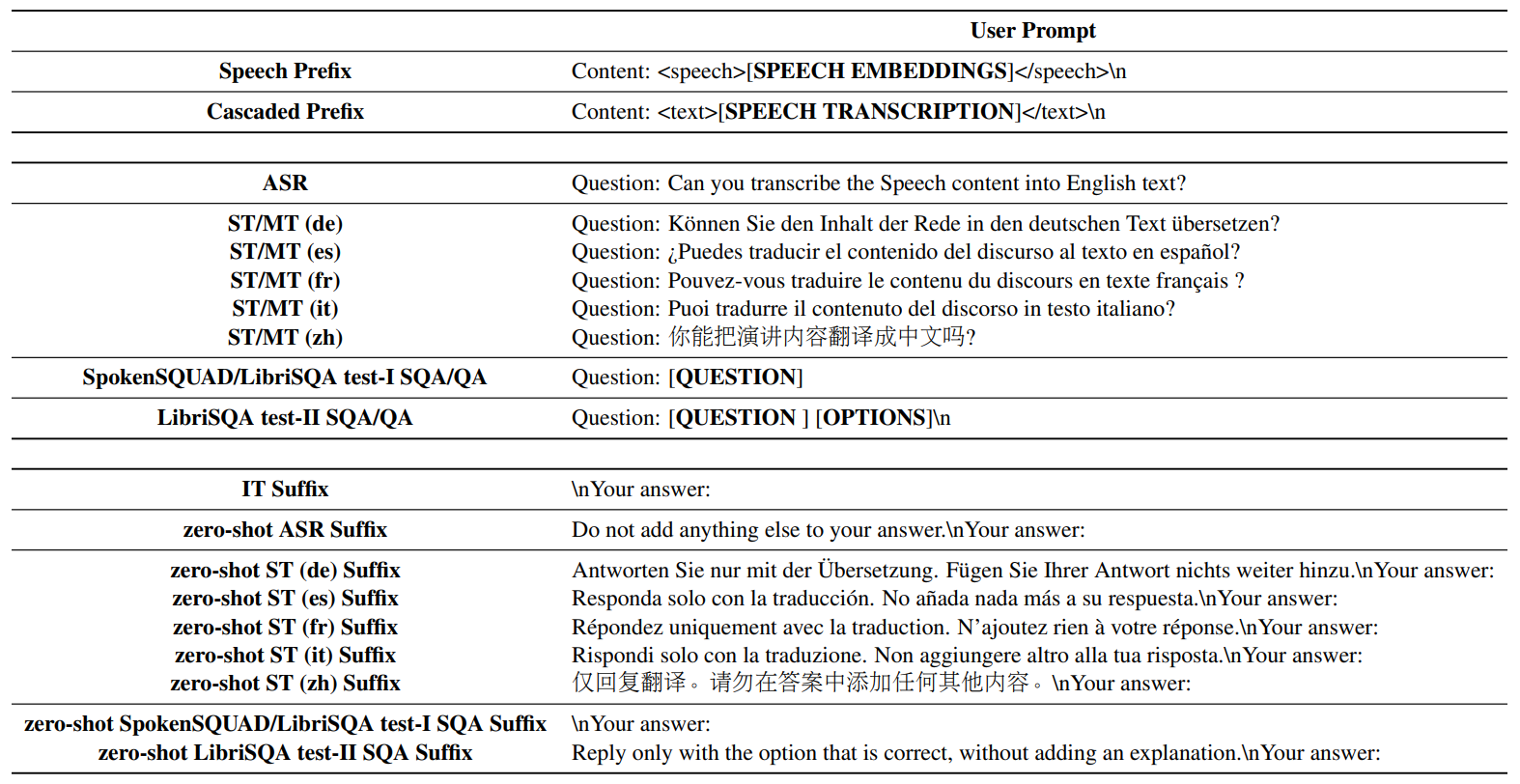
技术框架:SpeechMapper包含两个主要阶段:预训练阶段和指令微调阶段。在预训练阶段,SpeechMapper学习将语音特征映射到文本嵌入空间,该阶段不涉及LLM。在指令微调阶段,将预训练的SpeechMapper连接到目标LLM,并使用少量指令数据进行微调,以使SpeechMapper更好地适应LLM的嵌入空间。
关键创新:SpeechMapper的关键创新在于其解耦的训练策略。通过将语音特征映射模块的训练与LLM的训练分离,可以显著降低计算成本,并提高模型的泛化能力。此外,SpeechMapper采用了一种高效的指令微调方法,仅需少量数据即可实现良好的性能。
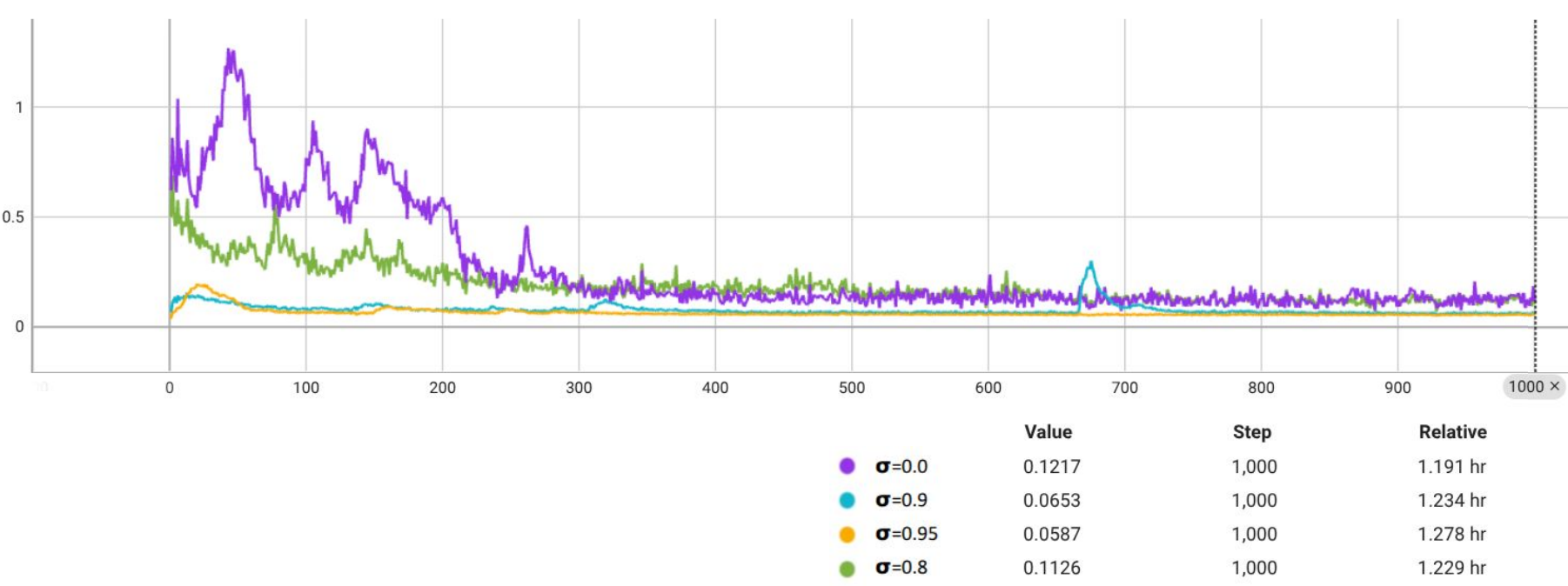
关键设计:SpeechMapper的预训练阶段可以使用各种语音基础模型作为输入,例如ASR模型或语音编码器。映射模块可以使用简单的线性层或更复杂的神经网络结构。指令微调阶段可以使用不同的损失函数,例如交叉熵损失或对比损失。论文中使用了1K步的指令微调,证明了其高效性。
🖼️ 关键图片
📊 实验亮点
SpeechMapper在任务无关设置中,可以与IWSLT25中最佳的指令跟随语音LLM相媲美,尽管从未在这些任务上进行过训练。在任务特定设置中,SpeechMapper在许多数据集上优于该模型,同时需要更少的数据和计算资源。例如,在口语问答任务上,SpeechMapper在多个数据集上取得了显著的性能提升。
🎯 应用场景
SpeechMapper可应用于各种语音相关的任务,例如语音翻译、口语问答、语音助手等。该方法可以降低开发成本,提高模型性能,并促进语音技术在更多场景中的应用。未来,SpeechMapper可以扩展到支持更多语言和模态,实现更强大的多模态智能。
📄 摘要(原文)
Current speech LLMs bridge speech foundation models to LLMs using projection layers, training all of these components on speech instruction data. This strategy is computationally intensive and susceptible to task and prompt overfitting. We present SpeechMapper, a cost-efficient speech-to-LLM-embedding training approach that mitigates overfitting, enabling more robust and generalizable models. Our model is first pretrained without the LLM on inexpensive hardware, and then efficiently attached to the target LLM via a brief 1K-step instruction tuning (IT) stage. Through experiments on speech translation and spoken question answering, we demonstrate the versatility of SpeechMapper's pretrained block, presenting results for both task-agnostic IT, an ASR-based adaptation strategy that does not train in the target task, and task-specific IT. In task-agnostic settings, Speechmapper rivals the best instruction-following speech LLM from IWSLT25, despite never being trained on these tasks, while in task-specific settings, it outperforms this model across many datasets, despite requiring less data and compute. Overall, SpeechMapper offers a practical and scalable approach for efficient, generalizable speech-LLM integration without large-scale IT.