Beyond Accuracy: A Cognitive Load Framework for Mapping the Capability Boundaries of Tool-use Agents
作者: Qihao Wang, Yue Hu, Mingzhe Lu, Jiayue Wu, Yanbing Liu, Yuanmin Tang
分类: cs.CL, cs.SE
发布日期: 2026-01-28
备注: Accepted to AAAI 2026
💡 一句话要点
提出基于认知负荷理论的工具使用Agent能力边界评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 认知负荷 能力评估 基准测试
📋 核心要点
- 现有工具使用Agent的评估主要关注最终准确率,忽略了模型能力边界的认知瓶颈。
- 论文提出基于认知负荷理论的框架,将任务复杂性分解为内在负荷和外在负荷。
- 构建了ToolLoad-Bench基准测试,通过参数化调整认知负荷,精确评估模型的能力边界。
📝 摘要(中文)
大型语言模型(LLMs)使用外部工具的能力开启了强大的现实世界交互,因此严格的评估至关重要。然而,目前的基准测试主要报告最终准确率,揭示了模型能做什么,但掩盖了定义其真实能力边界的认知瓶颈。为了从简单的性能评分转变为诊断工具,我们引入了一个基于认知负荷理论的框架。我们的框架将任务复杂性分解为两个可量化的组成部分:内在负荷,即解决方案路径的固有结构复杂性,用一种新颖的工具交互图来形式化;以及外在负荷,即由模糊的任务呈现方式引起的难度。为了实现受控实验,我们构建了ToolLoad-Bench,这是第一个具有参数可调认知负荷的基准测试。我们的评估揭示了随着认知负荷增加而出现的明显的性能悬崖,使我们能够精确地绘制每个模型的能力边界。我们验证了我们的框架的预测与经验结果高度校准,从而建立了一种理解Agent极限的原则性方法,并为构建更高效的系统奠定了实践基础。
🔬 方法详解
问题定义:现有的大型语言模型在工具使用方面取得了显著进展,但对其能力的评估主要集中在最终的准确率上。这种评估方式无法揭示模型在解决复杂任务时的认知瓶颈,难以诊断模型失败的原因,也无法指导模型能力的进一步提升。因此,如何更全面、更深入地评估工具使用Agent的能力边界,成为了一个亟待解决的问题。
核心思路:论文的核心思路是将认知负荷理论引入到工具使用Agent的评估中。认知负荷理论认为,任务的复杂性可以分解为内在负荷(任务本身的复杂性)和外在负荷(任务呈现方式的复杂性)。通过量化这两种负荷,可以更精确地评估模型在不同复杂程度任务下的表现,从而揭示其能力边界。论文认为,通过控制和调整认知负荷,可以更好地理解Agent的优势和劣势。
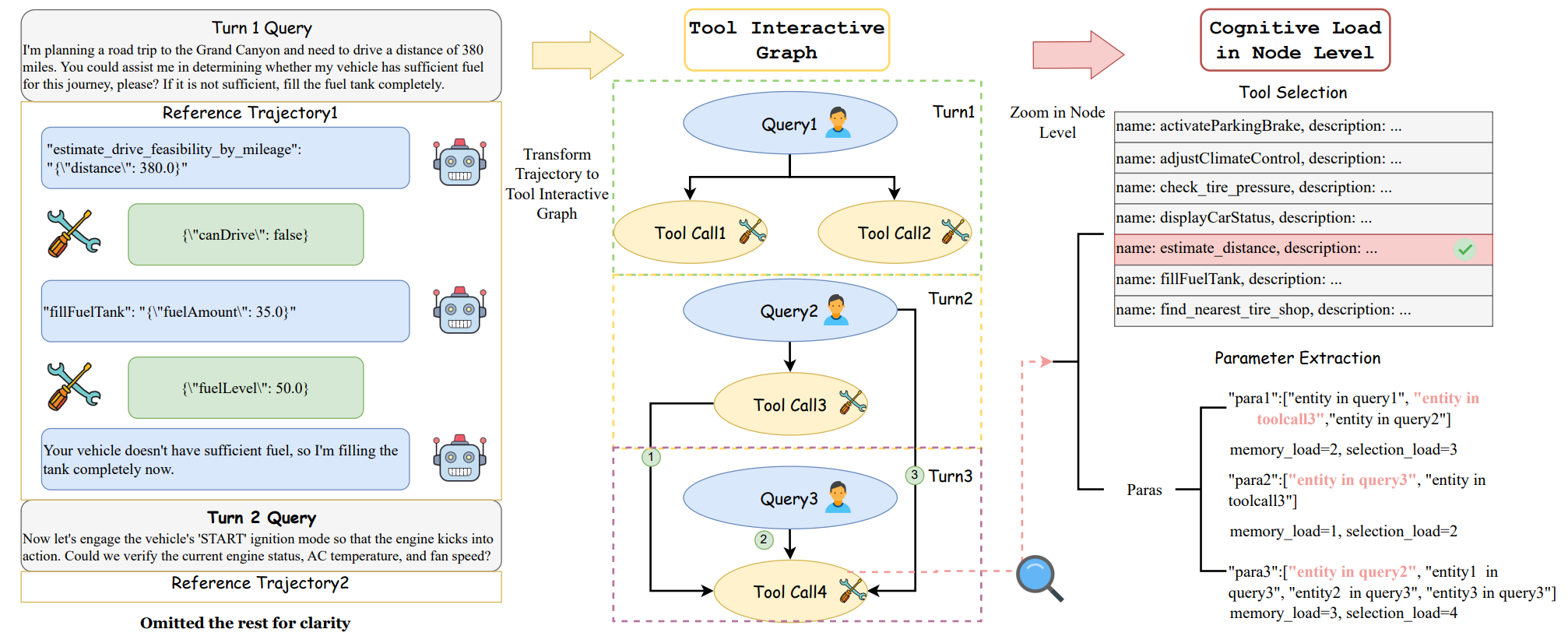
技术框架:论文提出的框架主要包含以下几个部分:1) 任务分解:将复杂的工具使用任务分解为一系列步骤,每个步骤对应一个工具的使用。2) 内在负荷量化:使用工具交互图(Tool Interaction Graph)来形式化解决方案路径的结构复杂性,从而量化内在负荷。工具交互图描述了工具之间的依赖关系和调用顺序。3) 外在负荷量化:通过分析任务描述的模糊程度和信息完整性来量化外在负荷。4) 基准测试构建:构建ToolLoad-Bench基准测试,该基准测试允许参数化调整认知负荷,从而实现受控实验。5) 模型评估:使用ToolLoad-Bench评估不同模型的性能,并分析其在不同认知负荷下的表现。
关键创新:论文的关键创新在于:1) 认知负荷框架:首次将认知负荷理论应用于工具使用Agent的评估,提供了一种更全面、更深入的评估方法。2) 工具交互图:提出了一种新颖的工具交互图,用于形式化解决方案路径的结构复杂性,从而量化内在负荷。3) ToolLoad-Bench基准测试:构建了第一个具有参数可调认知负荷的基准测试,为受控实验提供了基础。
关键设计:ToolLoad-Bench基准测试的关键设计在于其参数化可调的认知负荷。具体来说,可以通过以下方式调整认知负荷:1) 内在负荷:通过改变工具交互图的结构(例如,增加节点数量、增加边的数量、改变边的权重)来调整内在负荷。2) 外在负荷:通过改变任务描述的清晰程度(例如,增加歧义性、减少信息量)来调整外在负荷。此外,论文还设计了相应的评估指标,用于衡量模型在不同认知负荷下的性能。
🖼️ 关键图片
📊 实验亮点
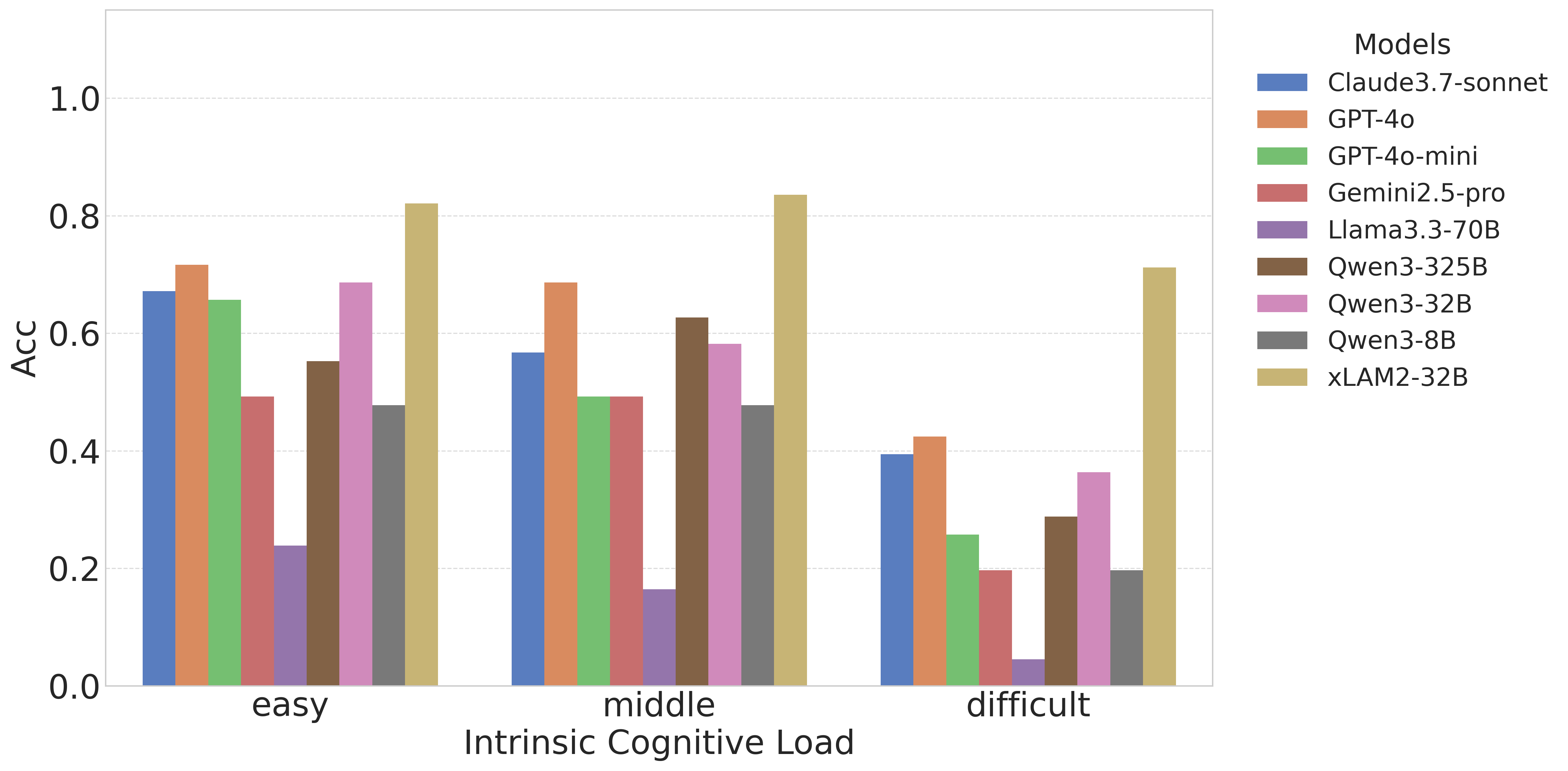
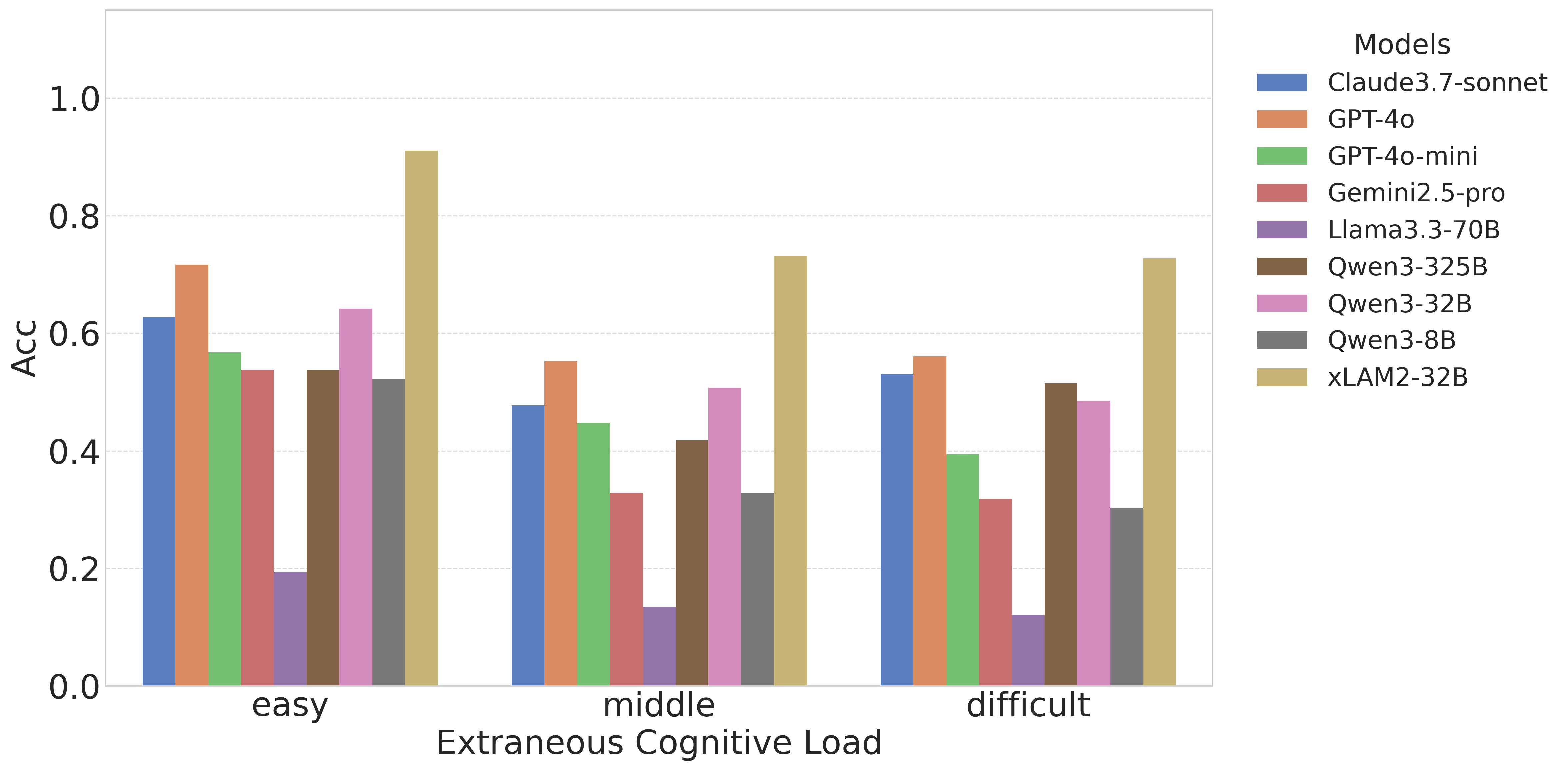
实验结果表明,随着认知负荷的增加,模型的性能会出现明显的性能悬崖,这验证了认知负荷理论的有效性。此外,实验还验证了论文提出的框架的预测与经验结果高度校准,表明该框架可以有效地评估模型的能力边界。ToolLoad-Bench基准测试为未来的研究提供了一个有价值的平台。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型在各种实际场景中的工具使用能力,例如智能客服、自动化流程、机器人控制等。通过诊断模型在不同认知负荷下的表现,可以针对性地改进模型的设计,提高其效率和可靠性。此外,该框架还可以用于比较不同模型的工具使用能力,为模型选择提供依据。
📄 摘要(原文)
The ability of Large Language Models (LLMs) to use external tools unlocks powerful real-world interactions, making rigorous evaluation essential. However, current benchmarks primarily report final accuracy, revealing what models can do but obscuring the cognitive bottlenecks that define their true capability boundaries. To move from simple performance scoring to a diagnostic tool, we introduce a framework grounded in Cognitive Load Theory. Our framework deconstructs task complexity into two quantifiable components: Intrinsic Load, the inherent structural complexity of the solution path, formalized with a novel Tool Interaction Graph; and Extraneous Load, the difficulty arising from ambiguous task presentation. To enable controlled experiments, we construct ToolLoad-Bench, the first benchmark with parametrically adjustable cognitive load. Our evaluation reveals distinct performance cliffs as cognitive load increases, allowing us to precisely map each model's capability boundary. We validate that our framework's predictions are highly calibrated with empirical results, establishing a principled methodology for understanding an agent's limits and a practical foundation for building more efficient systems.