PsychePass: Calibrating LLM Therapeutic Competence via Trajectory-Anchored Tournaments
作者: Zhuang Chen, Dazhen Wan, Zhangkai Zheng, Guanqun Bi, Xiyao Xiao, Binghang Li, Minlie Huang
分类: cs.CL, cs.LG
发布日期: 2026-01-28
💡 一句话要点
PsychePass:通过轨迹锚定竞赛校准LLM的心理治疗能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理治疗 能力评估 轨迹锚定 强化学习
📋 核心要点
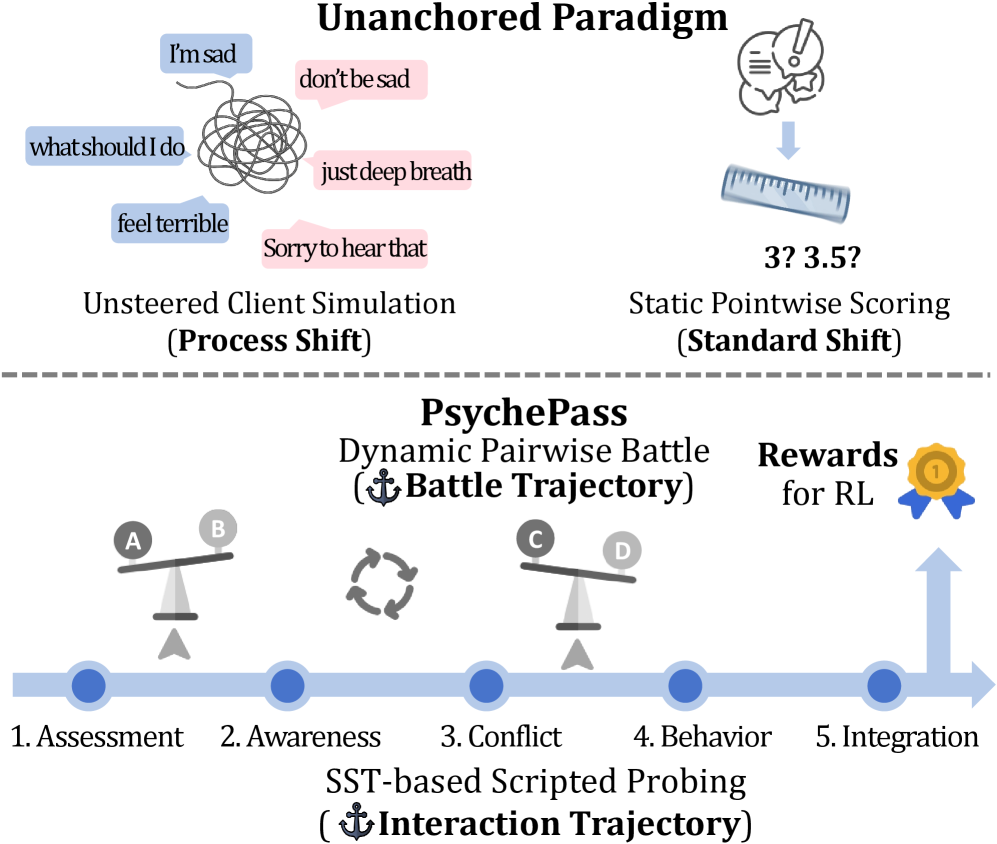
- 现有评估方法在评估LLM的心理治疗能力时,存在过程漂移和标准漂移问题,导致评估结果不稳定。
- PsychePass框架通过轨迹锚定竞赛,在模拟和判断两个层面锚定轨迹,从而校准LLM的治疗能力。
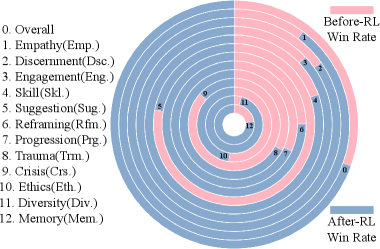
- 实验结果表明,PsychePass能够有效评估LLM的治疗能力,并与人类专家的判断高度一致,同时可用于强化学习提升LLM性能。
📝 摘要(中文)
大型语言模型在心理健康领域展现出潜力,但评估其治疗能力仍然具有挑战性,因为咨询过程具有非结构化和纵向的特点。我们认为,当前的评估范式存在未锚定的缺陷,导致两种形式的不稳定性:过程漂移,即不受控制的客户模拟偏离特定的咨询目标;标准漂移,即静态的逐点评分缺乏可靠判断的稳定性。为了解决这个问题,我们提出了PsychePass,一个统一的框架,通过轨迹锚定竞赛来校准LLM的治疗能力。我们首先在模拟中锚定交互轨迹,客户精确控制流畅的咨询过程,以探测多方面的能力。然后,我们通过高效的瑞士制锦标赛在判断中锚定战斗轨迹,利用动态的成对战斗来产生稳健的Elo评分。除了排名之外,我们还证明了锦标赛轨迹可以转化为可信的奖励信号,从而实现策略上的强化学习,以提高LLM的性能。大量的实验验证了PsychePass的有效性及其与人类专家判断的高度一致性。
🔬 方法详解
问题定义:当前评估大型语言模型(LLM)在心理治疗方面的能力面临挑战。传统的评估方法,例如静态评分或自由对话模拟,存在两个主要问题:一是过程漂移,即在模拟咨询过程中,客户的行为不受约束,可能偏离预定的咨询目标,导致评估结果不稳定;二是标准漂移,即静态的评分标准难以捕捉咨询过程的动态变化,缺乏可靠性。这些问题使得难以准确评估LLM在心理治疗中的实际能力。
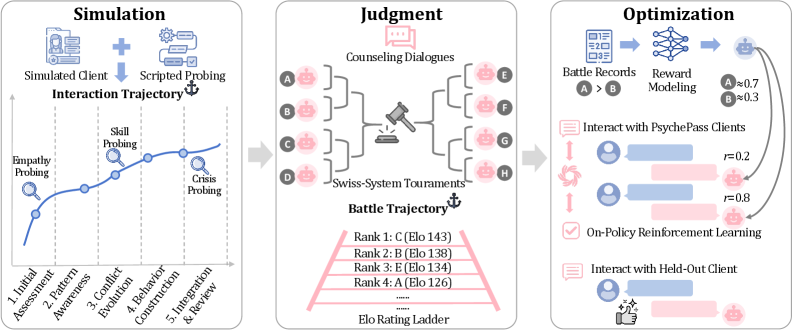
核心思路:PsychePass的核心思想是通过“轨迹锚定”来解决上述问题。具体来说,它通过在模拟咨询过程中精确控制客户的行为,将交互轨迹锚定在特定的咨询目标上,从而避免过程漂移。同时,它采用基于瑞士制锦标赛的动态成对比较方法,将判断锚定在战斗轨迹上,从而提高评估的稳定性和可靠性。这种轨迹锚定的方法能够更准确地评估LLM在心理治疗中的能力。
技术框架:PsychePass框架包含两个主要阶段:模拟阶段和评估阶段。在模拟阶段,系统模拟客户与LLM之间的咨询对话,其中客户的行为受到精确控制,以确保咨询过程围绕特定的治疗目标展开。在评估阶段,系统采用瑞士制锦标赛,让不同的LLM进行成对比较,并根据比赛结果计算Elo评分,从而对LLM的治疗能力进行排名。此外,系统还可以将锦标赛轨迹转化为奖励信号,用于强化学习,以进一步提高LLM的性能。
关键创新:PsychePass的关键创新在于其轨迹锚定的评估方法。与传统的评估方法相比,PsychePass通过精确控制客户行为和采用动态成对比较,有效地解决了过程漂移和标准漂移问题,从而提高了评估的准确性和可靠性。此外,PsychePass还提供了一种将评估结果转化为奖励信号的机制,可以用于强化学习,以进一步提高LLM的治疗能力。
关键设计:在模拟阶段,需要设计客户行为的控制策略,以确保咨询过程围绕特定的治疗目标展开。这可能涉及到预定义的对话模板、行为规则或目标函数。在评估阶段,需要选择合适的瑞士制锦标赛参数,例如比赛轮数和评分系统,以确保评估的公平性和效率。此外,还需要设计合适的奖励函数,将锦标赛轨迹转化为有效的强化学习信号。具体参数设置和损失函数细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PsychePass能够有效评估LLM的治疗能力,并与人类专家的判断高度一致。通过轨迹锚定竞赛,PsychePass能够更准确地识别出具有较高治疗能力的LLM。此外,实验还证明了将锦标赛轨迹转化为奖励信号,可以有效地利用强化学习来提高LLM的治疗性能。具体的性能数据和提升幅度在论文中有所描述,但此处无法得知。
🎯 应用场景
PsychePass可应用于心理健康领域,用于评估和提升LLM在心理咨询、心理支持和心理健康教育方面的能力。该框架可以帮助开发者更好地理解LLM的优势和不足,从而开发出更有效的心理健康应用。此外,PsychePass还可以作为一种标准化的评估工具,用于比较不同LLM的治疗能力,促进该领域的研究和发展。
📄 摘要(原文)
While large language models show promise in mental healthcare, evaluating their therapeutic competence remains challenging due to the unstructured and longitudinal nature of counseling. We argue that current evaluation paradigms suffer from an unanchored defect, leading to two forms of instability: process drift, where unsteered client simulation wanders away from specific counseling goals, and standard drift, where static pointwise scoring lacks the stability for reliable judgment. To address this, we introduce Ps, a unified framework that calibrates the therapeutic competence of LLMs via trajectory-anchored tournaments. We first anchor the interaction trajectory in simulation, where clients precisely control the fluid consultation process to probe multifaceted capabilities. We then anchor the battle trajectory in judgments through an efficient Swiss-system tournament, utilizing dynamic pairwise battles to yield robust Elo ratings. Beyond ranking, we demonstrate that tournament trajectories can be transformed into credible reward signals, enabling on-policy reinforcement learning to enhance LLMs' performance. Extensive experiments validate the effectiveness of PsychePass and its strong consistency with human expert judgments.