Identifying and Transferring Reasoning-Critical Neurons: Improving LLM Inference Reliability via Activation Steering
作者: Fangan Dong, Zuming Yan, Xuri Ge, Zhiwei Xu, Mengqi Zhang, Xuanang Chen, Ben He, Xin Xin, Zhumin Chen, Ying Zhou
分类: cs.CL
发布日期: 2026-01-27
💡 一句话要点
提出AdaRAS,通过激活干预提升LLM推理可靠性,无需额外训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理可靠性 神经元激活 激活干预 自适应学习 测试时干预 推理关键神经元
📋 核心要点
- 现有LLM推理可靠性不足,依赖后训练或高成本采样,限制了实际应用效率。
- AdaRAS通过识别并干预对推理正确性至关重要的神经元激活,提升推理可靠性。
- 实验表明,AdaRAS在数学和编码任务上显著提升性能,且具有良好的迁移性和可扩展性。
📝 摘要(中文)
尽管大型语言模型(LLM)展现出强大的推理能力,但在具有挑战性的任务上实现可靠的性能通常需要后训练或计算成本高昂的采样策略,限制了它们的实际效率。本文首先表明,LLM中一小部分神经元与推理正确性表现出很强的预测相关性。基于此,我们提出了一种轻量级的测试时框架AdaRAS(自适应推理激活干预),通过选择性地干预神经元激活来提高推理可靠性。AdaRAS通过极性感知平均差准则识别推理关键神经元(RCN),并在推理过程中自适应地调整它们的激活,从而增强不正确的推理轨迹,同时避免已经正确的案例发生退化。在10个数学和编码基准上的实验表明,该方法具有一致的改进,包括在AIME-24和AIME-25上超过13%的收益。此外,AdaRAS在数据集之间表现出强大的可迁移性,并可扩展到更强大的模型,优于后训练方法,且无需额外的训练或采样成本。
🔬 方法详解
问题定义:现有大型语言模型在复杂推理任务中,虽然能力强大,但可靠性不足。为了提高可靠性,通常需要进行后训练或者采用计算量大的采样策略,这增加了部署成本,限制了LLM的实际应用。因此,如何以轻量级的方式提高LLM的推理可靠性是一个关键问题。
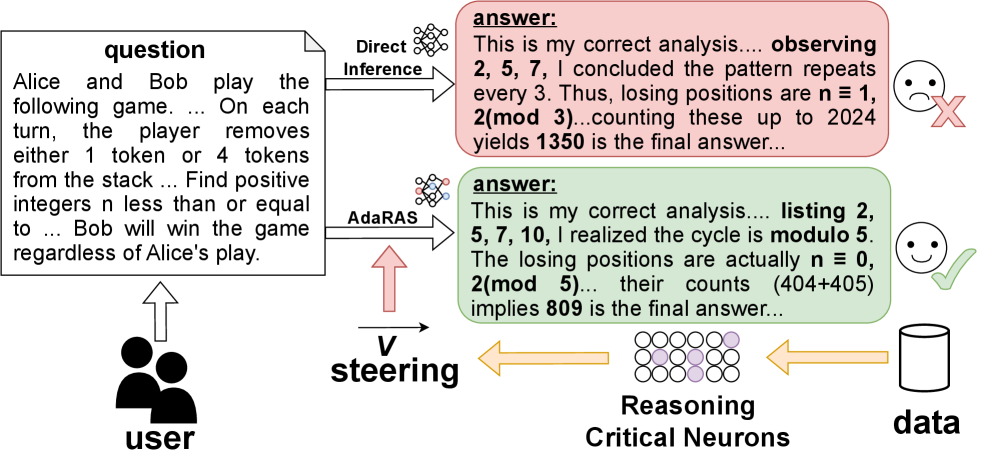
核心思路:论文的核心思路是,LLM中只有一小部分神经元对推理的正确性起着关键作用。通过识别这些“推理关键神经元”(Reasoning-Critical Neurons, RCNs),并在推理过程中选择性地干预它们的激活状态,可以有效地纠正错误的推理过程,从而提高整体的推理可靠性。这种方法避免了全局性的调整,更加高效。
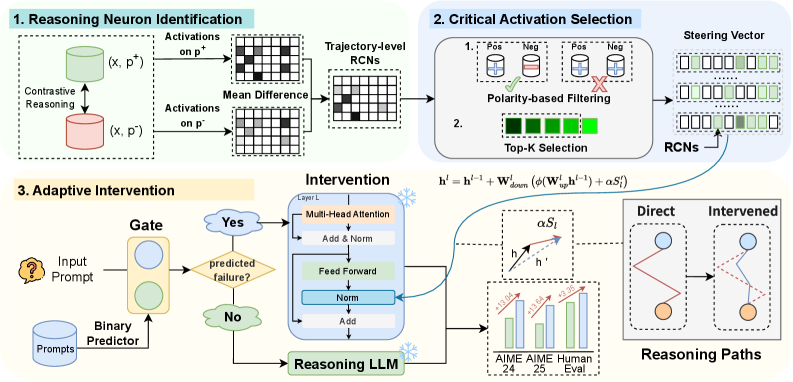
技术框架:AdaRAS (Adaptive Reasoning Activation Steering) 框架主要包含两个阶段:1) 推理关键神经元(RCN)的识别:通过极性感知平均差准则,分析神经元激活与推理正确性的相关性,从而确定RCN。2) 自适应激活干预:在推理过程中,根据当前输入和模型的预测结果,自适应地调整RCN的激活状态。如果模型预测错误,则增强RCN的激活,反之则保持不变。
关键创新:AdaRAS的关键创新在于:1) 提出了RCN的概念,并证明了少量神经元对推理正确性的重要性。2) 设计了一种轻量级的激活干预方法,可以在测试时动态地调整神经元的激活状态,而无需额外的训练。3) 提出极性感知平均差准则,用于识别RCN,该准则考虑了神经元激活与推理正确性之间的正负相关性。
关键设计:RCN的识别基于极性感知平均差准则,具体而言,对于每个神经元,计算在正确推理和错误推理情况下的平均激活差异,并根据差异的符号确定神经元的极性。激活干预的幅度是自适应的,取决于当前输入和模型的预测结果。具体来说,如果模型预测错误,则将RCN的激活值朝着正确的方向调整一个小的幅度,该幅度由一个超参数控制。论文中没有明确提及损失函数或网络结构上的修改,重点在于推理阶段的激活干预。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AdaRAS在10个数学和编码基准上均取得了显著的性能提升,在AIME-24和AIME-25数据集上分别获得了超过13%的提升。此外,AdaRAS在不同数据集之间展现出良好的迁移性,并且可以扩展到更大的模型,优于传统的后训练方法,同时避免了额外的训练或采样成本。
🎯 应用场景
AdaRAS可应用于各种需要高可靠性推理的场景,如自动驾驶、医疗诊断、金融风控等。该方法无需额外训练,易于部署,能够显著提升LLM在这些关键领域的应用价值,并降低因推理错误带来的风险。未来,该技术有望扩展到更多类型的推理任务和更复杂的模型结构。
📄 摘要(原文)
Despite the strong reasoning capabilities of recent large language models (LLMs), achieving reliable performance on challenging tasks often requires post-training or computationally expensive sampling strategies, limiting their practical efficiency. In this work, we first show that a small subset of neurons in LLMs exhibits strong predictive correlations with reasoning correctness. Based on this observation, we propose AdaRAS (Adaptive Reasoning Activation Steering), a lightweight test-time framework that improves reasoning reliability by selectively intervening on neuron activations. AdaRAS identifies Reasoning-Critical Neurons (RCNs) via a polarity-aware mean-difference criterion and adaptively steers their activations during inference, enhancing incorrect reasoning traces while avoiding degradation on already-correct cases. Experiments on 10 mathematics and coding benchmarks demonstrate consistent improvements, including over 13% gains on AIME-24 and AIME-25. Moreover, AdaRAS exhibits strong transferability across datasets and scalability to stronger models, outperforming post-training methods without additional training or sampling cost.