TokenSeek: Memory Efficient Fine Tuning via Instance-Aware Token Ditching
作者: Runjia Zeng, Qifan Wang, Qiang Guan, Ruixiang Tang, Lifu Huang, Zhenting Wang, Xueling Zhang, Cheng Han, Dongfang Liu
分类: cs.CL, cs.AI
发布日期: 2026-01-27
备注: ICLR 2026
💡 一句话要点
TokenSeek:通过实例感知的Token丢弃实现内存高效的微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 内存优化 Token选择 实例感知
📋 核心要点
- 现有微调方法内存消耗巨大,激活值优化是降低内存的关键,但现有方法忽略了数据本身的特性。
- TokenSeek通过实例感知的token寻找和丢弃,动态地选择重要token进行训练,从而降低内存占用。
- 实验表明,TokenSeek在显著降低内存消耗的同时,能够保持甚至提升模型性能,例如在Llama3.2 1B上仅需14.8%的内存。
📝 摘要(中文)
微调已成为将大型语言模型(LLMs)适应下游任务的事实标准方法,但LLMs固有的高训练内存消耗使得这一过程效率低下。在现有的内存高效方法中,与激活相关的优化已被证明特别有效,因为激活始终占据总内存消耗的主导地位。尽管先前的技术提供了各种激活优化策略,但它们与数据无关的性质最终导致无效和不稳定的微调。在本文中,我们提出TokenSeek,这是一种通用的插件解决方案,通过实例感知的token寻找和丢弃,适用于各种基于Transformer的模型,从而显著节省微调内存(例如,在Llama3.2 1B上仅需要14.8%的内存),同时保持甚至更好的性能。此外,我们可解释的token寻找过程揭示了其有效性的根本原因,为未来token效率的研究提供了宝贵的见解。
🔬 方法详解
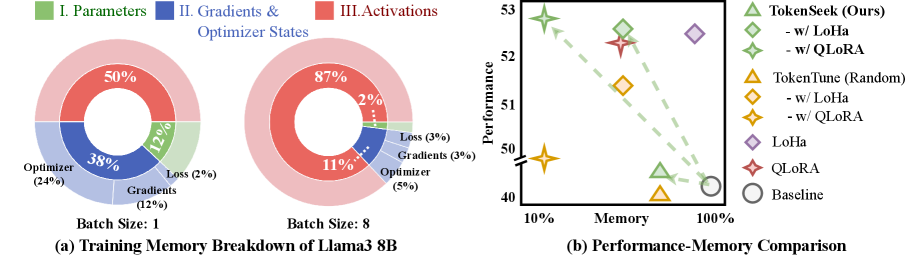
问题定义:大型语言模型微调时,激活值占据了大量的内存,导致训练效率低下。现有的激活值优化方法通常是数据无关的,即对所有输入样本采用相同的优化策略,忽略了不同样本的重要性差异,导致微调效果不稳定甚至性能下降。
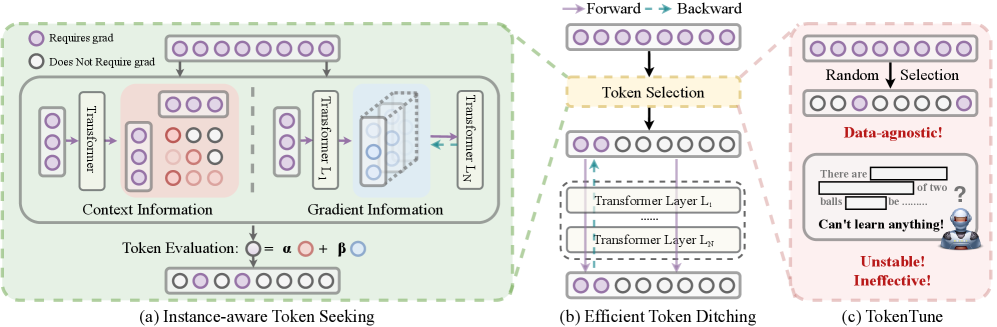
核心思路:TokenSeek的核心思想是根据输入实例的重要性,动态地选择和保留重要的token,丢弃不重要的token,从而减少参与计算的token数量,降低内存消耗。这种实例感知的token选择策略能够更有效地利用有限的计算资源,提高微调效率和性能。
技术框架:TokenSeek作为一个通用插件,可以集成到各种基于Transformer的模型中。其主要流程包括:1) Token重要性评估:对于每个输入实例,评估每个token的重要性;2) Token选择:根据重要性评估结果,选择保留最重要的token,丢弃不重要的token;3) 微调训练:使用选择后的token进行微调训练。
关键创新:TokenSeek的关键创新在于提出了实例感知的token选择策略。与现有方法不同,TokenSeek能够根据输入实例的特点,动态地调整token选择策略,从而更有效地降低内存消耗,提高微调效率和性能。此外,TokenSeek提供了一种可解释的token寻找过程,能够揭示模型关注的关键token,为未来的研究提供有价值的见解。
关键设计:TokenSeek的关键设计包括:1) Token重要性评估方法:可以使用梯度、注意力权重等指标来评估token的重要性。具体实现细节未知,论文中可能涉及具体计算公式;2) Token选择策略:可以采用固定比例或动态阈值等方法来选择token。具体实现细节未知,论文中可能涉及具体策略选择;3) 损失函数:使用标准的交叉熵损失函数进行微调训练。具体实现细节未知,论文中可能涉及损失函数的具体形式。
🖼️ 关键图片
📊 实验亮点
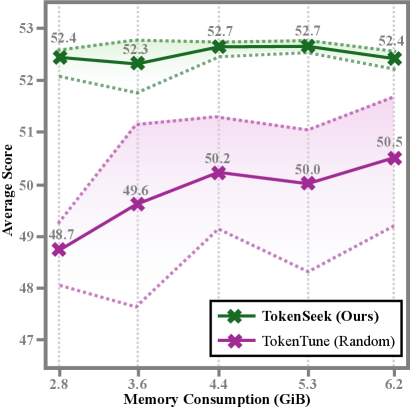
TokenSeek在Llama3.2 1B模型上实现了显著的内存节省,仅需14.8%的原始内存,同时保持甚至提升了模型性能。实验结果表明,TokenSeek是一种有效的内存高效微调方法,能够显著降低训练成本,提高训练效率。
🎯 应用场景
TokenSeek可应用于各种需要对大型语言模型进行微调的场景,例如自然语言处理、机器翻译、文本生成等。该方法能够显著降低微调所需的内存资源,使得在资源受限的设备上进行模型微调成为可能,加速LLM在各领域的应用。
📄 摘要(原文)
Fine tuning has been regarded as a de facto approach for adapting large language models (LLMs) to downstream tasks, but the high training memory consumption inherited from LLMs makes this process inefficient. Among existing memory efficient approaches, activation-related optimization has proven particularly effective, as activations consistently dominate overall memory consumption. Although prior arts offer various activation optimization strategies, their data-agnostic nature ultimately results in ineffective and unstable fine tuning. In this paper, we propose TokenSeek, a universal plugin solution for various transformer-based models through instance-aware token seeking and ditching, achieving significant fine-tuning memory savings (e.g., requiring only 14.8% of the memory on Llama3.2 1B) with on-par or even better performance. Furthermore, our interpretable token seeking process reveals the underlying reasons for its effectiveness, offering valuable insights for future research on token efficiency. Homepage: https://runjia.tech/iclr_tokenseek/