Up to 36x Speedup: Mask-based Parallel Inference Paradigm for Key Information Extraction in MLLMs
作者: Xinzhong Wang, Ya Guo, Jing Li, Huan Chen, Yi Tu, Yijie Hong, Gongshen Liu, Huijia Zhu
分类: cs.CL, cs.AI
发布日期: 2026-01-27
备注: Accepted by ICASSP 2026
💡 一句话要点
提出基于掩码的并行推理范式PIP,加速MLLM在关键信息抽取任务中的应用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关键信息抽取 多模态大语言模型 并行推理 掩码预训练 视觉文档 效率提升
📋 核心要点
- 多模态大语言模型在关键信息抽取任务中表现出潜力,但自回归推理方式限制了效率,尤其是在需要抽取多个独立字段时。
- 论文提出并行推理范式PIP,使用掩码令牌作为占位符,实现一次性生成多个目标值,避免了自回归的串行推理。
- 实验结果表明,PIP模型相比传统自回归模型,推理速度提升5-36倍,同时性能下降可忽略不计,显著提升了效率。
📝 摘要(中文)
本文提出了一种用于关键信息抽取(KIE)的并行推理范式(PIP),旨在解决多模态大语言模型(MLLM)在处理视觉文档(VrD)时,由于自回归推理的顺序生成特性而导致的效率瓶颈。PIP方法通过使用“[mask]”令牌作为所有目标值的占位符,从而能够在单个前向传播中同时生成多个语义独立的字段。为了支持这种范式,作者专门设计了掩码预训练策略,并构建了大规模的监督数据集。实验结果表明,与传统的自回归基线模型相比,PIP模型实现了5到36倍的推理速度提升,而性能下降可忽略不计。PIP在保持高精度的同时显著提高了效率,为可扩展和实用的真实世界KIE解决方案铺平了道路。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在关键信息抽取(KIE)任务中,由于自回归推理的串行特性导致的效率瓶颈。现有方法需要逐个生成目标字段,速度慢,难以满足实际应用需求。
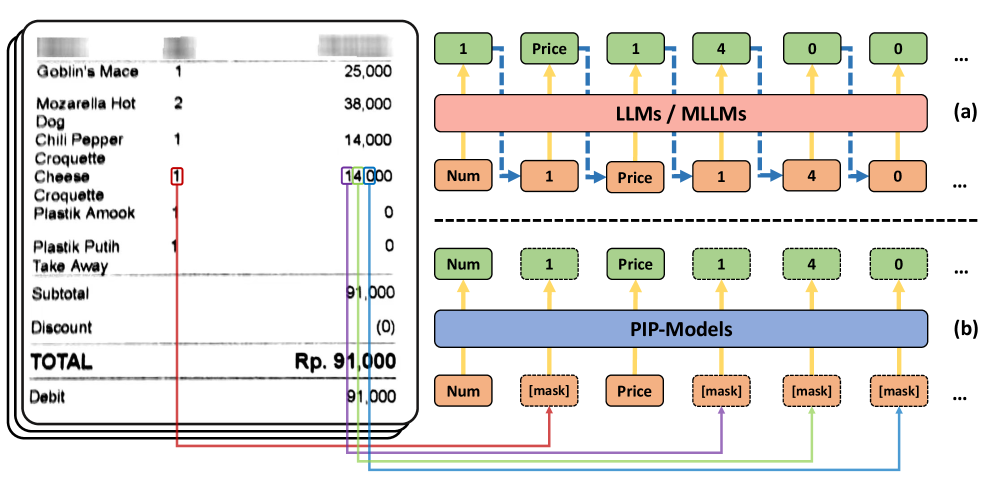
核心思路:论文的核心思路是将KIE任务转化为一个并行生成问题。通过引入“[mask]”令牌作为所有待抽取字段的占位符,模型可以在一次前向传播中同时预测所有字段的值,从而避免了自回归的顺序生成过程。这种并行化显著提高了推理速度。
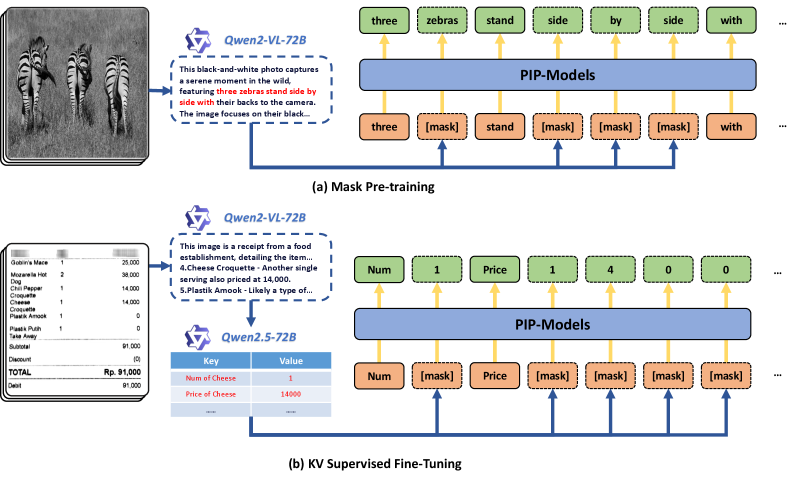
技术框架:PIP框架主要包含以下几个阶段:1) 输入视觉文档(VrD);2) 使用MLLM编码器提取视觉和文本特征;3) 将待抽取字段替换为“[mask]”令牌;4) MLLM解码器并行预测所有“[mask]”令牌对应的值;5) 输出抽取结果。框架的关键在于如何有效地训练模型来预测这些掩码令牌。
关键创新:最重要的技术创新点在于将KIE任务从自回归的序列生成问题转化为并行生成问题。通过引入掩码机制,模型可以同时预测多个目标字段,从而显著提高了推理效率。此外,论文还提出了专门的掩码预训练策略,以更好地训练模型预测掩码令牌。
关键设计:论文设计了大规模的监督数据集,用于训练PIP模型。此外,为了更好地训练模型预测掩码令牌,论文可能采用了特定的损失函数,例如,Masked Language Modeling (MLM) 损失,以鼓励模型学习上下文信息并准确预测被掩盖的字段值。具体的网络结构细节可能沿用了现有MLLM的架构,并针对并行预测任务进行了微调。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PIP模型在关键信息抽取任务中实现了5到36倍的推理速度提升,同时性能下降可忽略不计。这意味着在保持高准确率的前提下,显著提高了模型的效率,使其更适用于实际应用场景。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于各种需要从视觉文档中提取关键信息的场景,例如财务报表分析、合同信息提取、发票处理、身份验证等。通过显著提高KIE的效率,该方法能够降低运营成本,提升自动化水平,并加速企业数字化转型。
📄 摘要(原文)
Key Information Extraction (KIE) from visually-rich documents (VrDs) is a critical task, for which recent Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) have demonstrated strong potential. However, their reliance on autoregressive inference, which generates outputs sequentially, creates a significant efficiency bottleneck, especially as KIE tasks often involve extracting multiple, semantically independent fields. To overcome this limitation, we introduce PIP: a Parallel Inference Paradigm for KIE. Our approach reformulates the problem by using "[mask]" tokens as placeholders for all target values, enabling their simultaneous generation in a single forward pass. To facilitate this paradigm, we develop a tailored mask pre-training strategy and construct large-scale supervised datasets. Experimental results show that our PIP-models achieve a 5-36x inference speedup with negligible performance degradation compared to traditional autoregressive base models. By substantially improving efficiency while maintaining high accuracy, PIP paves the way for scalable and practical real-world KIE solutions.