Dynamic Multi-Expert Projectors with Stabilized Routing for Multilingual Speech Recognition
作者: Isha Pandey, Ashish Mittal, Vartul Bahuguna, Ganesh Ramakrishnan
分类: cs.CL
发布日期: 2026-01-27
💡 一句话要点
提出SMEAR-MoE,一种用于多语种语音识别的稳定路由动态多专家投影器。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语种语音识别 混合专家模型 动态路由 声学-语义映射 跨语言学习
📋 核心要点
- 现有基于LLM的语音识别方法在多语种场景下,单投影器难以捕捉不同语言的声学-语义映射。
- SMEAR-MoE通过稳定的混合专家机制,确保所有专家获得充分训练,避免专家坍塌,并促进跨语言知识共享。
- 实验表明,SMEAR-MoE在多种印度语言上显著降低了词错误率,并观察到专家在语言学上的专业化分工。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的语音识别方法,该方法通过轻量级投影器将冻结的语音编码器与LLM连接。针对单投影器难以捕捉多语种语音识别所需的多样化声学-语义映射的问题,本文提出了一种稳定的混合专家(MoE)投影器SMEAR-MoE,它确保所有专家都有密集的梯度流,防止专家崩溃,同时实现跨语言共享。在四种印度语言(印地语、马拉地语、泰米尔语、泰卢固语)上系统地比较了单体、静态多投影器和动态MoE设计。SMEAR-MoE表现出色,与单投影器基线相比,WER相对降低高达7.6%,同时保持了相当的运行时效率。专家路由分析进一步表明了语言上有意义的专业化,相关语言共享专家。这些结果表明,稳定的多专家投影器是可扩展且鲁棒的多语种语音识别的关键。
🔬 方法详解
问题定义:论文旨在解决多语种语音识别中,现有单投影器方法无法有效捕捉不同语言之间声学特征到语义信息复杂映射关系的问题。单投影器在处理多种语言时,容易出现性能瓶颈,无法充分利用不同语言的特性。
核心思路:论文的核心思路是利用混合专家(MoE)模型,为每种语言或每组语言分配不同的专家投影器,从而实现更精细的声学-语义映射。通过动态路由机制,根据输入语音的特征,选择合适的专家进行处理。同时,引入稳定化策略,防止部分专家因训练不足而失效,确保所有专家都能有效学习。
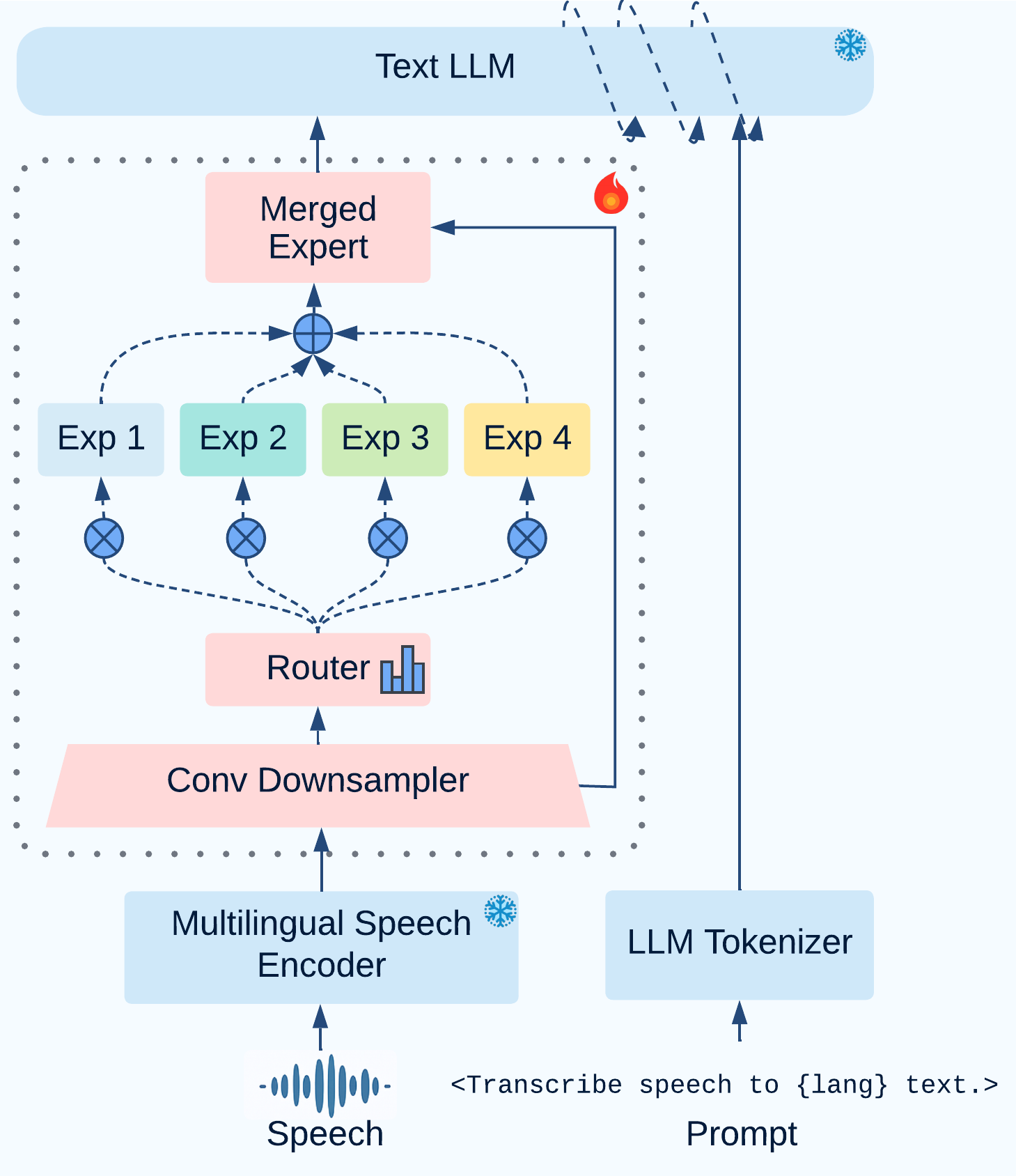
技术框架:SMEAR-MoE的整体框架包括一个冻结的语音编码器、一个动态多专家投影器和一个大型语言模型(LLM)。语音编码器将输入的语音信号转换为高维特征表示,然后动态多专家投影器根据输入特征选择合适的专家进行投影,最后LLM利用投影后的特征进行语音识别。动态路由机制根据输入特征计算每个专家的权重,并使用这些权重对专家的输出进行加权平均。
关键创新:SMEAR-MoE的关键创新在于其稳定的混合专家投影器设计。传统的MoE模型容易出现专家坍塌问题,即部分专家始终未被激活,导致训练效率低下。SMEAR-MoE通过引入辅助损失函数,鼓励所有专家都参与到训练过程中,从而避免专家坍塌。此外,SMEAR-MoE还采用了动态路由机制,可以根据输入语音的特征自适应地选择合适的专家。
关键设计:SMEAR-MoE的关键设计包括:1) 使用Gumbel-Softmax技巧进行可微分的专家选择;2) 引入辅助损失函数,例如专家负载均衡损失,以稳定专家训练;3) 采用残差连接和层归一化等技术,提高模型的训练稳定性和泛化能力。具体的参数设置,例如专家数量、隐藏层维度等,需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
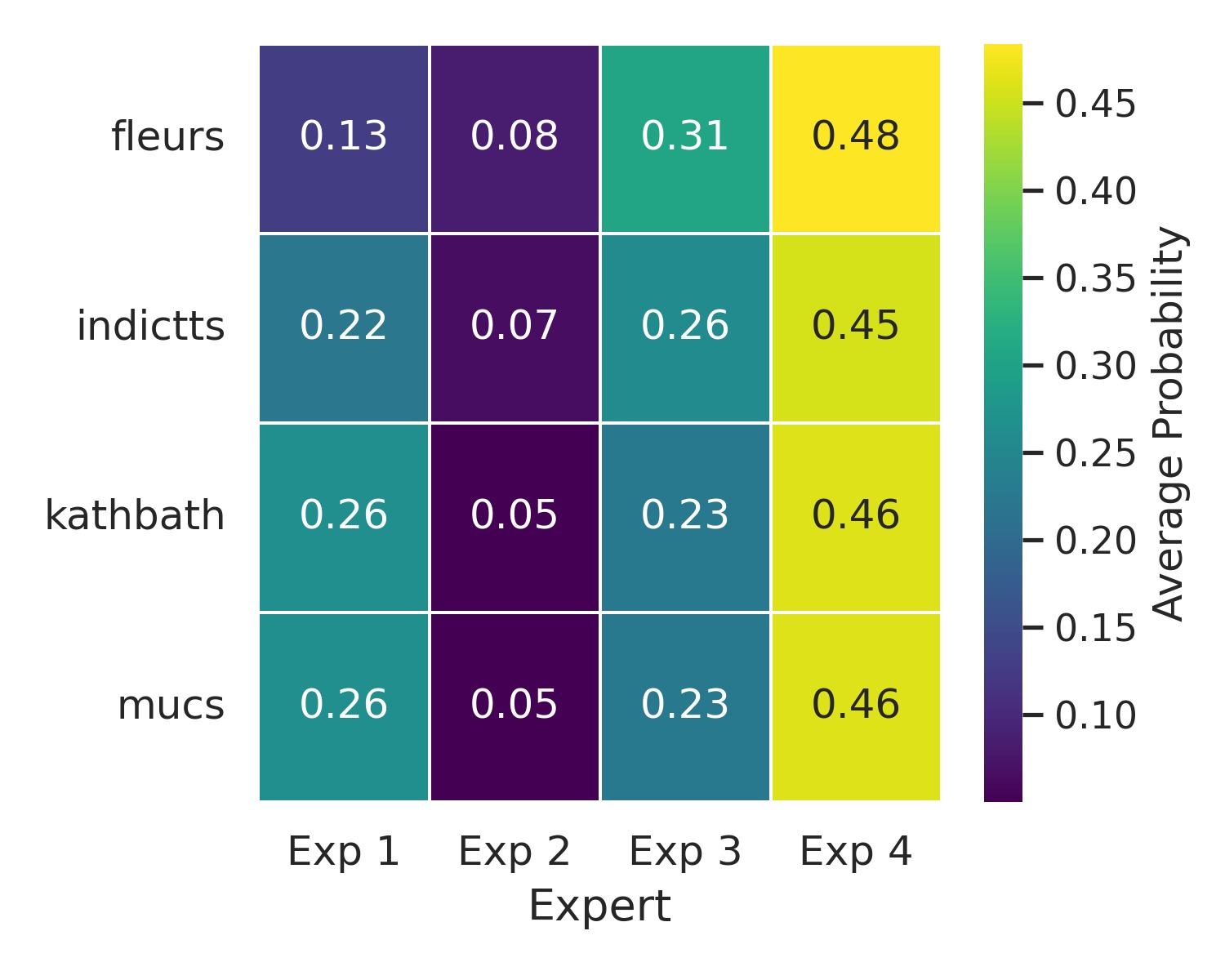
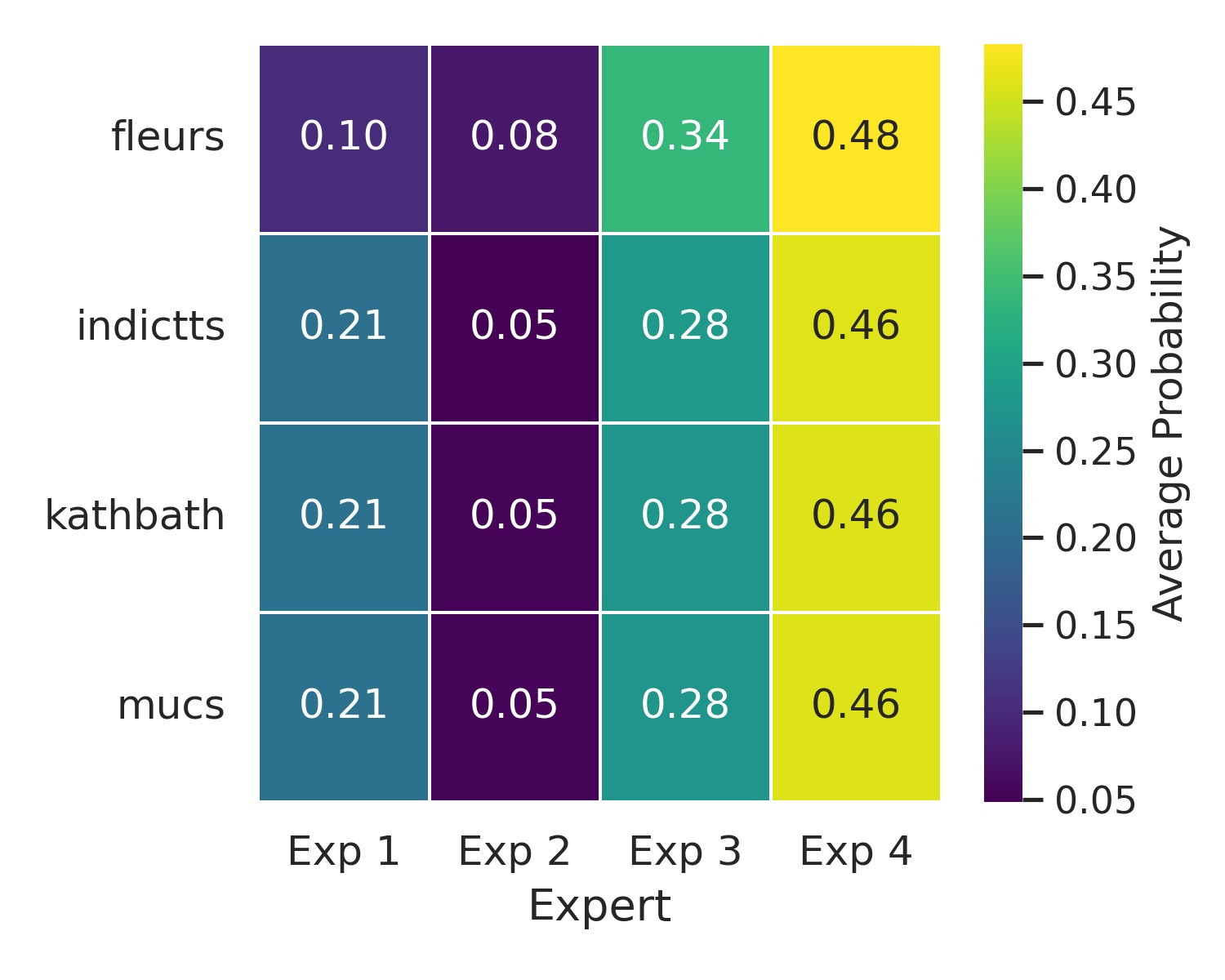
实验结果表明,SMEAR-MoE在四种印度语言(印地语、马拉地语、泰米尔语、泰卢固语)上取得了显著的性能提升,与单投影器基线相比,词错误率(WER)相对降低高达7.6%。专家路由分析显示,相关语言倾向于共享专家,表明SMEAR-MoE能够学习到语言之间的共性和差异,实现有效的跨语言知识迁移。
🎯 应用场景
该研究成果可应用于多语种语音助手、跨语言语音翻译、多语种语音搜索等领域。通过提升多语种语音识别的准确性和鲁棒性,可以有效促进不同语言人群之间的交流和信息获取,具有重要的社会价值和商业潜力。未来,该技术有望扩展到更多语言和更复杂的语音场景。
📄 摘要(原文)
Recent advances in LLM-based ASR connect frozen speech encoders with Large Language Models (LLMs) via lightweight projectors. While effective in monolingual settings, a single projector struggles to capture the diverse acoustic-to-semantic mappings required for multilingual ASR. To address this, we propose SMEAR-MoE, a stabilized Mixture-of-Experts projector that ensures dense gradient flow to all experts, preventing expert collapse while enabling cross-lingual sharing. We systematically compare monolithic, static multi-projector, and dynamic MoE designs across four Indic languages (Hindi, Marathi, Tamil, Telugu). Our SMEAR-MoE achieves strong performance, delivering upto a 7.6% relative WER reduction over the single-projector baseline, while maintaining comparable runtime efficiency. Analysis of expert routing further shows linguistically meaningful specialization, with related languages sharing experts. These results demonstrate that stable multi-expert projectors are key to scalable and robust multilingual ASR.