When Benchmarks Leak: Inference-Time Decontamination for LLMs
作者: Jianzhe Chai, Yu Zhe, Jun Sakuma
分类: cs.CL, cs.AI
发布日期: 2026-01-27
💡 一句话要点
提出DeconIEP,通过输入嵌入扰动实现大语言模型推理时去污染,提升评测可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 基准评测 测试集污染 推理时去污染 嵌入扰动
📋 核心要点
- 现有基准评测受测试集污染影响,导致性能虚高,直接修改测试集或抑制污染行为的方法存在缺陷。
- DeconIEP通过在输入嵌入空间引入微小扰动,引导模型避开记忆捷径,实现推理时去污染。
- 实验表明,DeconIEP在多个LLM和基准测试中有效去除了污染,同时对正常性能影响极小。
📝 摘要(中文)
基于基准的评测是比较大型语言模型(LLMs)的事实标准。然而,测试集污染日益威胁其可靠性,即测试样本或其近变体泄露到训练数据中,人为地夸大报告的性能。为了解决这个问题,之前的工作探索了两种主要的缓解方法。一种方法试图在评估之前识别和删除受污染的基准项目,但这不可避免地改变了评估集本身,并且在污染程度中等或严重时变得不可靠。另一种方法保留基准,而是在评估时抑制受污染的行为;然而,这种干预通常会干扰正常的推理,并导致良性输入的性能明显下降。我们提出了DeconIEP,这是一个完全在评估期间运行的去污染框架,通过在输入嵌入空间中应用小的、有界的扰动。在相对较少污染的参考模型的指导下,DeconIEP学习一个实例自适应的扰动生成器,引导被评估的模型远离记忆驱动的捷径路径。在多个开源LLM和基准测试中,大量的经验结果表明,DeconIEP实现了强大的去污染效果,同时仅对良性效用造成最小的降级。
🔬 方法详解
问题定义:大型语言模型(LLMs)的基准评测面临测试集污染问题,即测试数据泄露到训练集中,导致模型在测试集上表现虚高。现有方法要么修改测试集(不可靠),要么在推理时抑制污染行为(影响正常性能),都无法有效解决该问题。
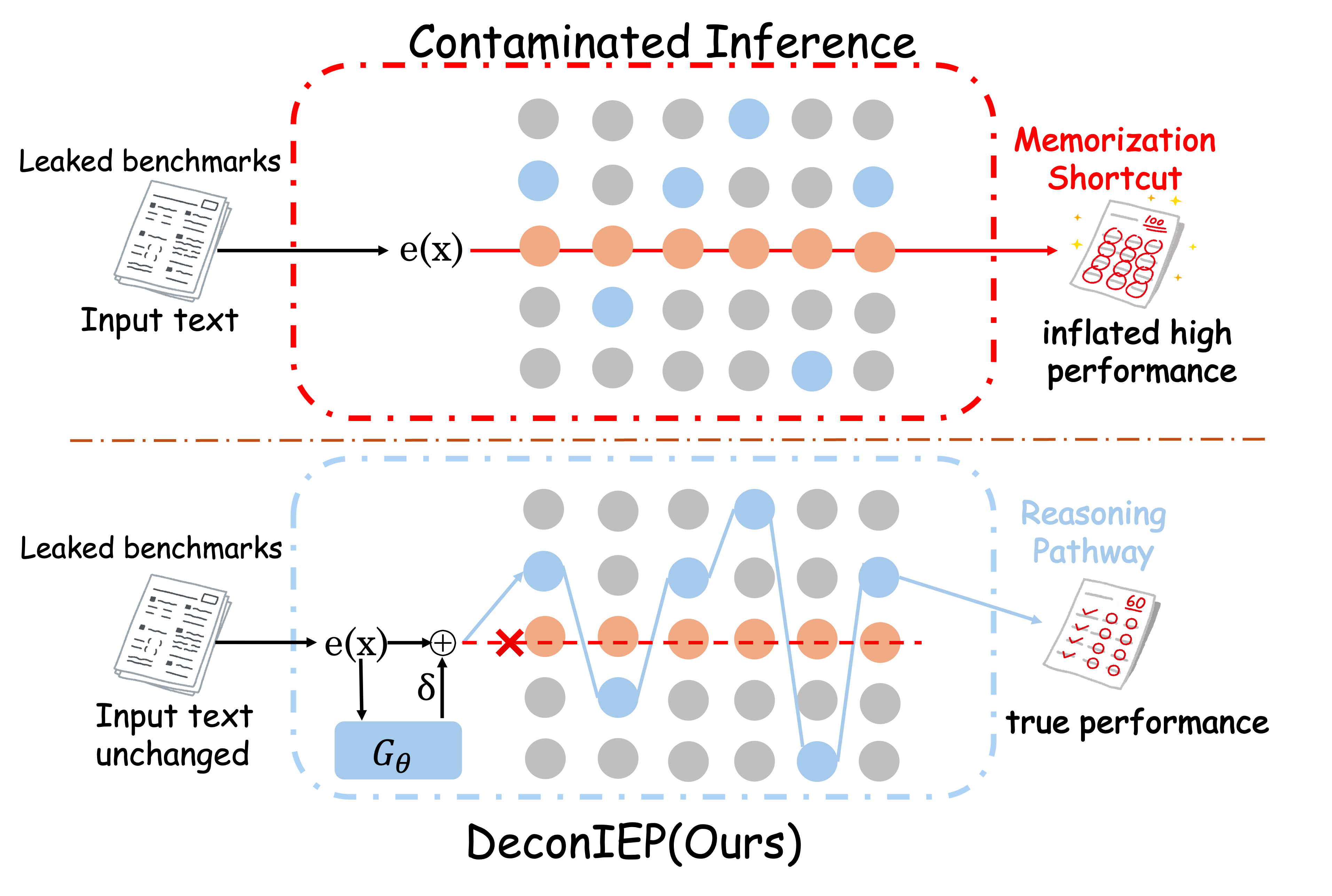
核心思路:DeconIEP的核心思路是在推理阶段,通过对输入嵌入进行微小的、有界的扰动,引导模型避开那些基于记忆的“捷径”路径,从而降低污染数据带来的性能提升。这种方法不修改测试集,也不直接抑制模型的行为,而是通过微妙的输入调整来影响模型的推理过程。
技术框架:DeconIEP框架包含以下主要步骤:1) 使用一个相对干净的参考模型(即污染较少的模型)作为指导;2) 针对每个输入实例,学习一个自适应的扰动生成器;3) 该生成器在输入嵌入空间中产生微小的扰动;4) 将扰动后的输入送入待评估的模型进行推理。整个过程在推理时进行,无需修改模型或训练数据。
关键创新:DeconIEP的关键创新在于其在推理时进行去污染的能力,以及使用实例自适应的扰动生成器。与直接修改测试集或抑制模型行为的方法不同,DeconIEP通过微妙的输入扰动来影响模型的推理过程,从而在不影响正常性能的前提下,降低污染数据带来的性能提升。
关键设计:DeconIEP的关键设计包括:1) 扰动的幅度是有界的,以避免对正常推理产生过大的影响;2) 扰动生成器是实例自适应的,即针对不同的输入,生成不同的扰动;3) 参考模型用于指导扰动生成,确保扰动能够有效地引导模型避开记忆捷径。具体的损失函数和网络结构等细节在论文中进行了详细描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
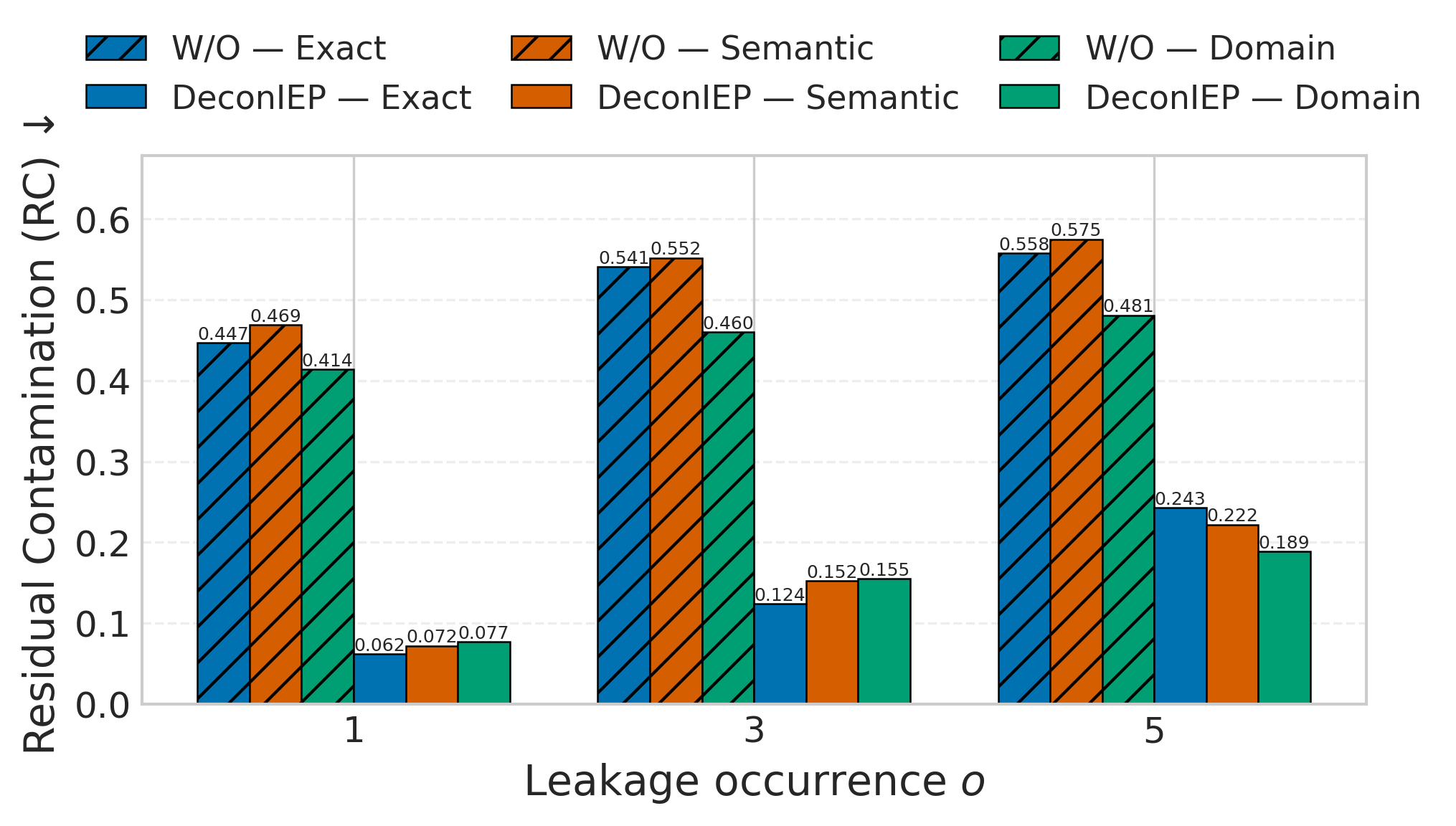
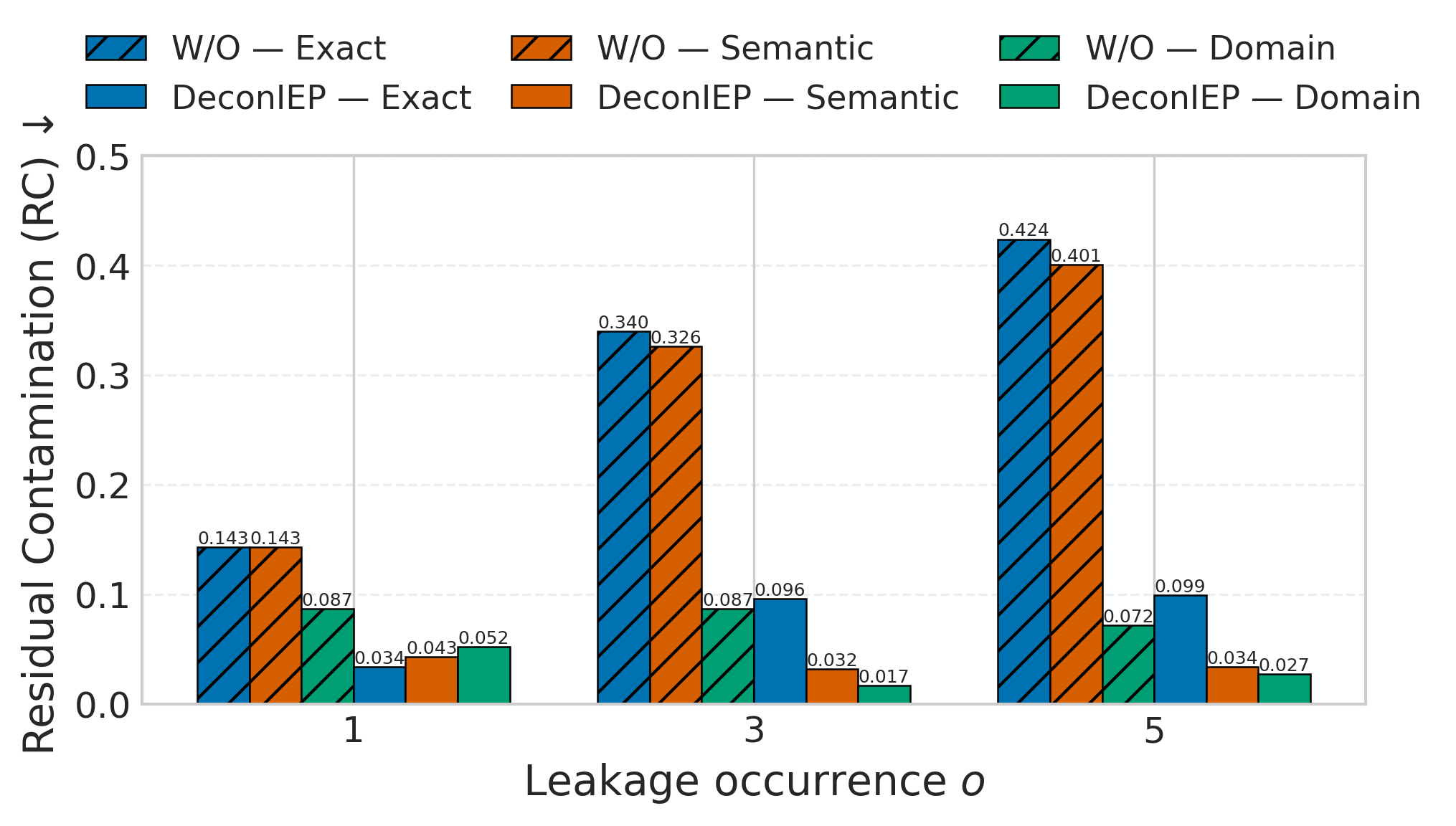
DeconIEP在多个开源LLM和基准测试中表现出强大的去污染效果,能够在有效降低污染带来的性能提升的同时,对正常输入的性能影响极小。具体的性能数据和对比基线在论文中进行了详细展示,但摘要中未提供具体数值。
🎯 应用场景
DeconIEP可应用于各种需要可靠基准评测的大语言模型,尤其是在模型训练数据来源广泛、难以完全控制的情况下。该方法能够提升模型评测的公正性和准确性,帮助研究者更客观地评估模型的真实能力,并促进更可靠的模型开发和部署。
📄 摘要(原文)
Benchmark-based evaluation is the de facto standard for comparing large language models (LLMs). However, its reliability is increasingly threatened by test set contamination, where test samples or their close variants leak into training data and artificially inflate reported performance. To address this issue, prior work has explored two main lines of mitigation. One line attempts to identify and remove contaminated benchmark items before evaluation, but this inevitably alters the evaluation set itself and becomes unreliable when contamination is moderate or severe. The other line preserves the benchmark and instead suppresses contaminated behavior at evaluation time; however, such interventions often interfere with normal inference and lead to noticeable performance degradation on clean inputs. We propose DeconIEP, a decontamination framework that operates entirely during evaluation by applying small, bounded perturbations in the input embedding space. Guided by a relatively less-contaminated reference model, DeconIEP learns an instance-adaptive perturbation generator that steers the evaluated model away from memorization-driven shortcut pathways. Across multiple open-weight LLMs and benchmarks, extensive empirical results show that DeconIEP achieves strong decontamination effectiveness while incurring only minimal degradation in benign utility.