DART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference
作者: Fuliang Liu, Xue Li, Ketai Zhao, Yinxi Gao, Ziyan Zhou, Zhonghui Zhang, Zhibin Wang, Wanchun Dou, Sheng Zhong, Chen Tian
分类: cs.CL
发布日期: 2026-01-27
🔗 代码/项目: GITHUB
💡 一句话要点
DART:受扩散模型启发的推测解码加速LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大型语言模型 LLM推理加速 扩散模型 并行生成 树剪枝 N-gram 自回归
📋 核心要点
- 现有推测解码方法如EAGLE3,虽提高了草稿准确性,但自回归推理导致草稿延迟高,成为性能瓶颈。
- DART受扩散模型启发,通过并行预测多个未来token的logits,消除了草稿阶段的自回归推理。
- DART通过高效的树剪枝算法构建高质量草稿token树,显著降低草稿开销,提升端到端解码速度。
📝 摘要(中文)
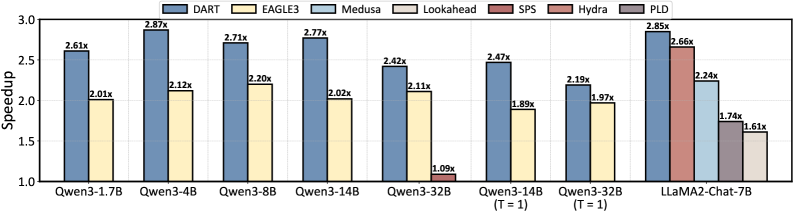
推测解码是一种有效的、无损的方法,用于加速大型语言模型(LLM)的推理。然而,现有的广泛采用的基于模型的草稿设计,如EAGLE3,以多步自回归推理为代价来提高准确性,导致高草稿延迟,最终使草稿阶段本身成为性能瓶颈。受到基于扩散的语言模型(dLLM)的启发,我们提出了DART,它利用并行生成来减少草稿延迟。DART基于目标模型的隐藏状态,在单个前向传递中并行预测多个未来掩码位置的logits,从而消除了草稿模型中的自回归展开,同时保持了轻量级设计。基于这些并行logits预测,我们进一步引入了一种高效的树剪枝算法,该算法构建具有N-gram强制语义连续性的高质量草稿token树。DART显著降低了草稿阶段的开销,同时保持了高草稿准确性,从而显著提高了端到端解码速度。实验结果表明,DART在多个数据集上实现了2.03倍-3.44倍的实际加速,平均超过EAGLE3 30%,并提供了一个实用的推测解码框架。
🔬 方法详解
问题定义:现有推测解码方法,特别是基于模型的草稿设计(如EAGLE3),在提高草稿准确性的同时,引入了多步自回归推理,导致草稿生成阶段的延迟较高。这使得草稿阶段本身成为整个解码过程的性能瓶颈,限制了整体加速效果。
核心思路:DART的核心思路是借鉴扩散模型(dLLM)的并行生成能力,在草稿阶段避免使用自回归方式,而是通过一次前向传播并行预测多个未来token的logits。这样可以显著降低草稿阶段的延迟,从而提高整体解码速度。
技术框架:DART的整体框架包括以下几个主要阶段:1) 基于目标模型的隐藏状态,并行预测多个未来掩码位置的logits;2) 利用高效的树剪枝算法,基于并行logits预测构建高质量的草稿token树,该树具有N-gram强制语义连续性;3) 使用目标模型验证草稿token树,并接受或拒绝草稿token。
关键创新:DART最重要的技术创新点在于其并行草稿生成机制,它通过模仿扩散模型的思想,避免了传统推测解码方法中草稿模型的自回归推理过程。这种并行化方法显著降低了草稿阶段的延迟,是DART能够实现更高加速比的关键。
关键设计:DART的关键设计包括:1) 使用目标模型的隐藏状态作为输入,预测多个未来token的logits;2) 设计了一种高效的树剪枝算法,用于构建高质量的草稿token树,该算法考虑了N-gram的语义连续性,以提高草稿的准确性;3) 具体参数设置和损失函数等细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DART在多个数据集上实现了2.03倍-3.44倍的实际加速,平均超过EAGLE3 30%。这些结果表明,DART能够显著降低草稿阶段的开销,同时保持高草稿准确性,从而显著提高端到端解码速度,为LLM推理加速提供了一种有效的解决方案。
🎯 应用场景
DART具有广泛的应用前景,可以应用于各种需要快速LLM推理的场景,例如:实时对话系统、机器翻译、文本摘要、代码生成等。通过提高LLM的推理速度,DART可以显著提升这些应用的响应速度和用户体验,并降低计算成本。未来,DART有望成为一种通用的LLM加速技术。
📄 摘要(原文)
Speculative decoding is an effective and lossless approach for accelerating LLM inference. However, existing widely adopted model-based draft designs, such as EAGLE3, improve accuracy at the cost of multi-step autoregressive inference, resulting in high drafting latency and ultimately rendering the drafting stage itself a performance bottleneck. Inspired by diffusion-based large language models (dLLMs), we propose DART, which leverages parallel generation to reduce drafting latency. DART predicts logits for multiple future masked positions in parallel within a single forward pass based on hidden states of the target model, thereby eliminating autoregressive rollouts in the draft model while preserving a lightweight design. Based on these parallel logit predictions, we further introduce an efficient tree pruning algorithm that constructs high-quality draft token trees with N-gram-enforced semantic continuity. DART substantially reduces draft-stage overhead while preserving high draft accuracy, leading to significantly improved end-to-end decoding speed. Experimental results demonstrate that DART achieves a 2.03x--3.44x wall-clock time speedup across multiple datasets, surpassing EAGLE3 by 30% on average and offering a practical speculative decoding framework. Code is released at https://github.com/fvliang/DART.