One Adapts to Any: Meta Reward Modeling for Personalized LLM Alignment
作者: Hongru Cai, Yongqi Li, Tiezheng Yu, Fengbin Zhu, Wenjie Wang, Fuli Feng, Wenjie Li
分类: cs.CL, cs.AI
发布日期: 2026-01-26
💡 一句话要点
提出元奖励建模(MRM)框架,解决个性化LLM对齐中用户反馈稀疏和泛化难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化对齐 元学习 奖励模型 大型语言模型 用户偏好 少样本学习 鲁棒性 MAML
📋 核心要点
- 现有个性化LLM对齐方法面临用户反馈数据稀缺和难以快速适应新用户的挑战。
- 论文提出元奖励建模(MRM)框架,将个性化奖励建模视为元学习问题,学习偏好适应过程。
- 实验表明,MRM在少样本个性化、用户鲁棒性方面优于现有方法,性能得到显著提升。
📝 摘要(中文)
大型语言模型(LLM)的对齐旨在使其输出与人类偏好一致,而个性化对齐则进一步使模型适应个体用户。这依赖于能够捕捉用户特定偏好并自动提供个性化反馈的个性化奖励模型。然而,开发这些模型面临两个关键挑战:来自个体用户的反馈稀缺,以及需要高效地适应未见过的用户。我们认为,解决这些约束需要一种范式转变,即从拟合数据来学习用户偏好,转变为学习偏好适应的过程。为了实现这一点,我们提出了元奖励建模(MRM),它将个性化奖励建模重新定义为一个元学习问题。具体来说,我们将每个用户的奖励模型表示为基本奖励函数的加权组合,并使用模型无关的元学习(MAML)风格的框架来优化这些权重的初始化,以支持在有限反馈下的快速适应。为了确保鲁棒性,我们引入了鲁棒个性化目标(RPO),在元优化过程中更加重视难以学习的用户。在个性化偏好数据集上的大量实验验证了MRM增强了少样本个性化,提高了用户鲁棒性,并且始终优于基线。
🔬 方法详解
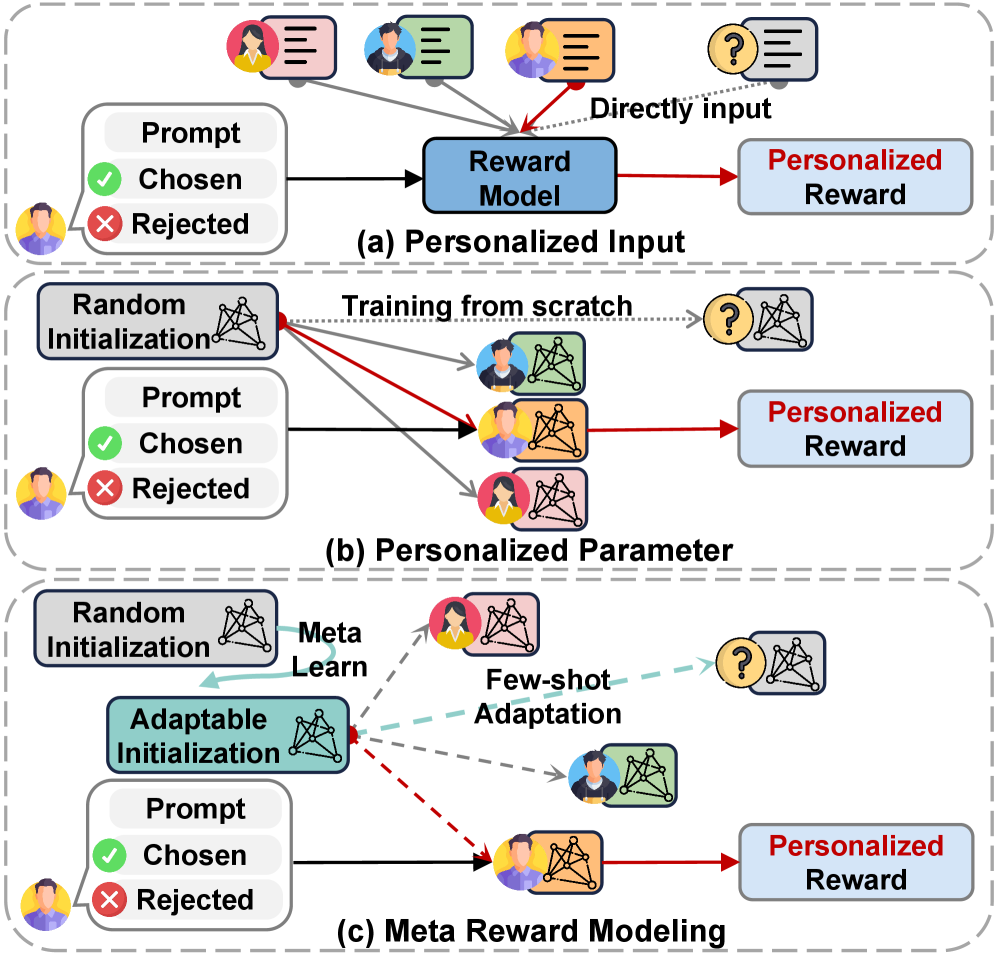
问题定义:论文旨在解决个性化大型语言模型(LLM)对齐问题,即如何使LLM的输出与特定用户的偏好相一致。现有的方法通常需要大量的用户反馈数据来训练个性化的奖励模型,然而,在实际应用中,每个用户提供的反馈往往是有限的,并且模型需要能够快速适应新的用户,这给个性化奖励模型的训练带来了挑战。
核心思路:论文的核心思路是将个性化奖励建模问题转化为一个元学习问题。通过元学习,模型学习的是一种“学习如何学习”的能力,即学习如何快速适应新的用户偏好。具体来说,模型学习的是一个良好的初始化状态,使得在面对新的用户时,只需要少量的反馈数据就可以快速地调整模型参数,从而适应用户的个性化偏好。
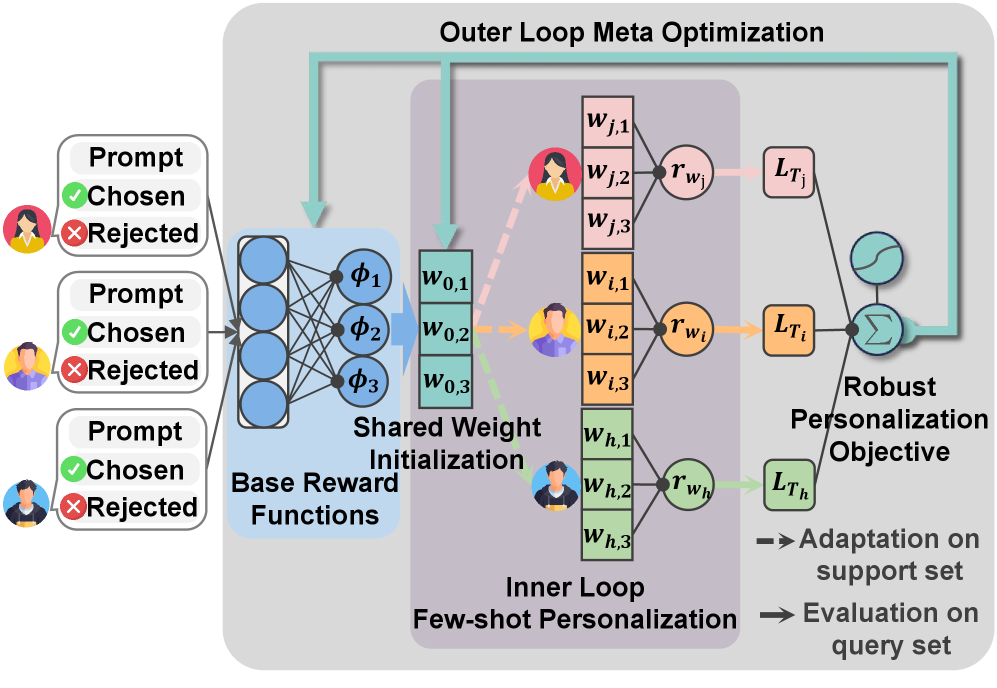
技术框架:MRM框架包含两个主要阶段:元训练阶段和个性化适应阶段。在元训练阶段,模型使用多个用户的偏好数据进行训练,学习一个通用的奖励模型初始化状态。每个用户的奖励模型被表示为一组基本奖励函数的加权组合。在个性化适应阶段,对于一个新的用户,模型使用该用户提供的少量反馈数据来调整基本奖励函数的权重,从而快速适应用户的个性化偏好。为了提高模型的鲁棒性,论文还引入了鲁棒个性化目标(RPO),在元训练阶段更加关注那些难以学习的用户。
关键创新:论文的关键创新在于将个性化奖励建模问题转化为元学习问题,并提出了元奖励建模(MRM)框架。与传统的个性化奖励建模方法相比,MRM能够利用元学习的能力,在用户反馈数据稀缺的情况下,快速适应新的用户偏好。此外,RPO的引入进一步提高了模型的鲁棒性,使其能够更好地处理不同用户的偏好差异。
关键设计:MRM的关键设计包括:1) 将每个用户的奖励模型表示为基本奖励函数的加权组合,这种表示方式使得模型可以灵活地适应不同的用户偏好;2) 使用MAML风格的元学习框架来优化基本奖励函数的权重初始化,MAML能够学习一个良好的初始化状态,使得模型可以快速适应新的任务;3) 引入鲁棒个性化目标(RPO),RPO通过对难以学习的用户赋予更高的权重,从而提高模型的鲁棒性。具体的损失函数和网络结构等细节在论文中有详细描述,这里不再赘述。
🖼️ 关键图片
📊 实验亮点
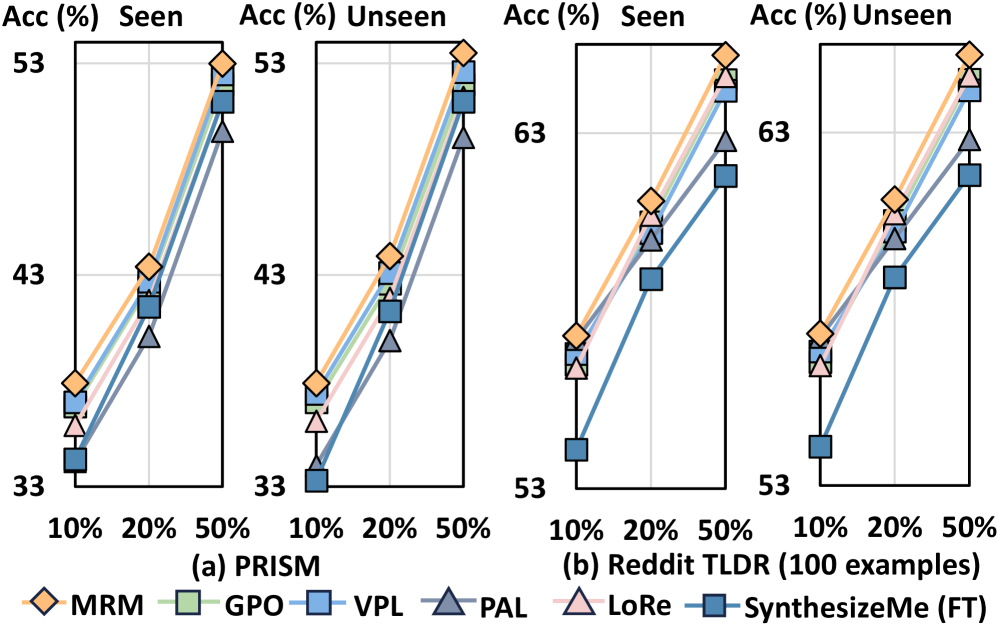
实验结果表明,MRM在多个个性化偏好数据集上显著优于基线方法。在少样本学习场景下,MRM能够利用少量用户反馈快速适应用户偏好,性能提升明显。此外,RPO的引入进一步提高了模型的鲁棒性,使得模型在不同用户上的表现更加稳定。具体性能数据和提升幅度在论文中有详细展示。
🎯 应用场景
该研究成果可广泛应用于个性化推荐系统、对话系统、内容生成等领域。例如,在个性化推荐系统中,可以利用MRM快速构建用户专属的奖励模型,从而更准确地预测用户的偏好,提高推荐的准确性和用户满意度。未来,该方法有望进一步扩展到更复杂的场景,例如多模态数据的个性化对齐。
📄 摘要(原文)
Alignment of Large Language Models (LLMs) aims to align outputs with human preferences, and personalized alignment further adapts models to individual users. This relies on personalized reward models that capture user-specific preferences and automatically provide individualized feedback. However, developing these models faces two critical challenges: the scarcity of feedback from individual users and the need for efficient adaptation to unseen users. We argue that addressing these constraints requires a paradigm shift from fitting data to learn user preferences to learn the process of preference adaptation. To realize this, we propose Meta Reward Modeling (MRM), which reformulates personalized reward modeling as a meta-learning problem. Specifically, we represent each user's reward model as a weighted combination of base reward functions, and optimize the initialization of these weights using a Model-Agnostic Meta-Learning (MAML)-style framework to support fast adaptation under limited feedback. To ensure robustness, we introduce the Robust Personalization Objective (RPO), which places greater emphasis on hard-to-learn users during meta optimization. Extensive experiments on personalized preference datasets validate that MRM enhances few-shot personalization, improves user robustness, and consistently outperforms baselines.