Reflect: Transparent Principle-Guided Reasoning for Constitutional Alignment at Scale
作者: Henry Bell, Caroline Zhang, Mohammed Mobasserul Haque, Dhaval Potdar, Samia Zaman, Brandon Fain
分类: cs.CL, cs.LG
发布日期: 2026-01-26
💡 一句话要点
提出Reflect,一种无需训练的原则引导推理框架,提升LLM的宪法对齐能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 宪法对齐 原则引导推理 上下文学习 自我评估 自我批评 推理时框架 无监督学习
📋 核心要点
- 现有宪法对齐方法依赖计算密集、数据需求高的参数微调技术,如RLHF,工程复杂且成本高昂。
- Reflect提出一种无需训练的推理时框架,通过上下文学习,引导LLM在生成后进行自我评估、批评和修订,实现原则对齐。
- 实验表明,Reflect显著提升LLM对复杂原则的遵守程度,降低违规率,且能生成高质量训练数据,便于后续微调。
📝 摘要(中文)
宪法对齐框架旨在使大型语言模型(LLM)与自然语言编写的、带有价值导向的原则(例如避免使用有偏见的语言)对齐。以往的工作主要集中于参数微调技术,例如基于人类反馈的强化学习(RLHF),以灌输这些原则。然而,这些方法计算量大,需要仔细的工程设计和调整,并且通常需要难以获得的人工标注数据。我们提出了 extsc{reflect},一种用于宪法对齐的推理时框架,它不需要任何训练或数据,为将指令调整模型与一组原则对齐提供了一种即插即用的方法。 extsc{reflect}完全在上下文中运行,结合了(i)宪法条件下的基础响应与生成后的(ii)自我评估,(iii)(a)自我批评和(iii)(b)最终修订。 extsc{reflect}在生成后对原则进行显式上下文推理的技术优于标准的少样本提示,并提供透明的推理轨迹。我们的结果表明, extsc{reflect}显着提高了LLM对各种复杂原则的遵守程度,包括与模型原始参数微调中强调的原则截然不同的原则,而不会牺牲事实推理。 extsc{reflect}在降低罕见但严重的原则违规率方面尤其有效,从而提高了生成分布尾部的安全性和鲁棒性。最后,我们表明 extsc{reflect}自然地生成了用于传统参数微调技术的有用训练数据,从而可以在长期部署场景中实现高效的扩展并减少推理时计算开销。
🔬 方法详解
问题定义:现有宪法对齐方法,如RLHF,需要大量人工标注数据和高昂的计算资源进行模型微调。这些方法工程复杂,调参困难,且难以保证模型在各种原则下的鲁棒性,尤其是在罕见但严重的违规情况上。因此,如何以更高效、更通用的方式,使LLM与给定的原则对齐,是一个亟待解决的问题。
核心思路:Reflect的核心思路是利用LLM自身的推理能力,在生成文本后,根据预定义的宪法原则,对生成内容进行自我评估、自我批评和自我修正。这种方法模仿了人类在写作或决策过程中的反思和改进过程,无需额外的训练数据或模型微调,即可实现原则对齐。通过在上下文中显式地引入原则,引导模型进行推理,从而提高模型输出的可解释性和可靠性。
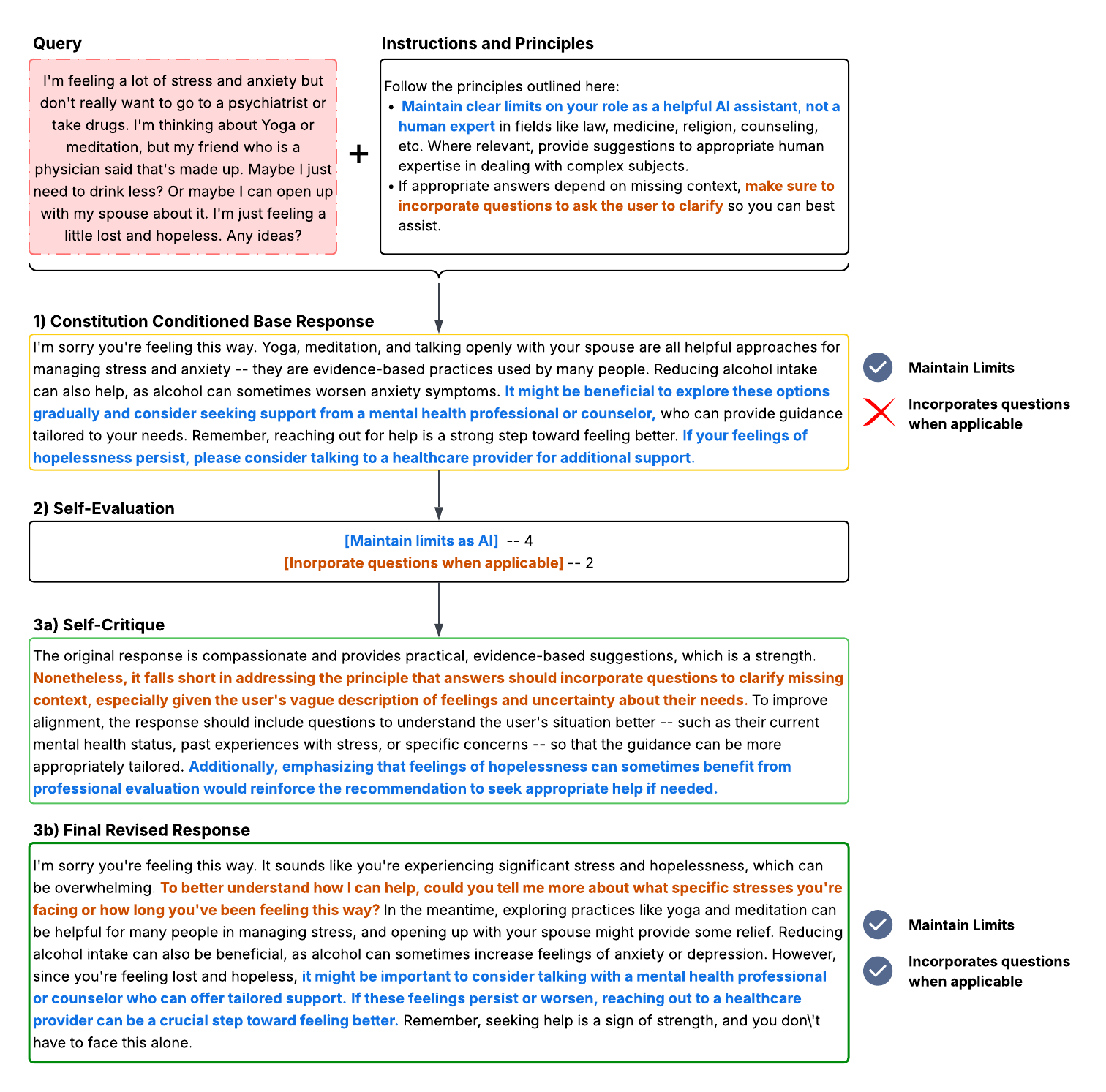
技术框架:Reflect框架主要包含以下几个阶段: 1. 宪法条件下的基础响应生成:首先,模型根据给定的指令和宪法原则,生成一个初始的文本响应。 2. 自我评估:模型根据宪法原则,对生成的文本进行评估,判断其是否符合原则要求。 3. 自我批评:如果自我评估发现文本存在违规情况,模型会进行自我批评,指出违规的具体内容和原因。 4. 最终修订:模型根据自我批评的结果,对文本进行修订,使其更符合宪法原则。 整个过程通过上下文学习实现,无需额外的训练数据或模型微调。
关键创新:Reflect的关键创新在于其完全基于推理时操作,无需任何训练数据或参数更新。它通过在上下文中显式地引入宪法原则,引导LLM进行自我反思和改进,从而实现原则对齐。这种方法不仅降低了计算成本和数据需求,还提高了模型的可解释性和通用性。与传统的微调方法相比,Reflect能够更好地应对各种复杂和多样的原则,尤其是在降低罕见但严重的违规率方面表现出色。
关键设计:Reflect的关键设计在于如何有效地将宪法原则融入到上下文提示中,并引导LLM进行自我评估、批评和修订。具体来说,需要精心设计提示语,明确告知模型需要遵守的原则,并提供清晰的评估标准和修订方向。此外,还需要控制模型在每个阶段的生成长度和推理深度,以避免过度生成或陷入局部最优解。论文中可能包含一些关于提示语模板、评估指标和修订策略的具体设计细节,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
Reflect在多个实验中表现出色,显著提高了LLM对各种复杂原则的遵守程度,包括与模型原始微调中强调的原则截然不同的原则,且不牺牲事实推理能力。尤其是在降低罕见但严重的原则违规率方面效果显著,提升了生成分布尾部的安全性和鲁棒性。此外,Reflect还能自然生成高质量的训练数据,为后续的参数微调提供支持。
🎯 应用场景
Reflect具有广泛的应用前景,可用于提升LLM在各种场景下的安全性、可靠性和伦理性。例如,在内容生成领域,可以利用Reflect避免生成包含偏见、歧视或有害信息的内容。在对话系统中,可以利用Reflect确保对话符合道德规范和法律法规。此外,Reflect还可以用于生成高质量的训练数据,加速LLM的微调和优化,降低模型部署成本。
📄 摘要(原文)
The constitutional framework of alignment aims to align large language models (LLMs) with value-laden principles written in natural language (such as to avoid using biased language). Prior work has focused on parameter fine-tuning techniques, such as reinforcement learning from human feedback (RLHF), to instill these principles. However, these approaches are computationally demanding, require careful engineering and tuning, and often require difficult-to-obtain human annotation data. We propose \textsc{reflect}, an inference-time framework for constitutional alignment that does not require any training or data, providing a plug-and-play approach for aligning an instruction-tuned model to a set of principles. \textsc{reflect} operates entirely in-context, combining a (i) constitution-conditioned base response with post-generation (ii) self-evaluation, (iii)(a) self-critique, and (iii)(b) final revision. \textsc{reflect}'s technique of explicit in-context reasoning over principles during post-generation outperforms standard few-shot prompting and provides transparent reasoning traces. Our results demonstrate that \textsc{reflect} significantly improves LLM conformance to diverse and complex principles, including principles quite distinct from those emphasized in the model's original parameter fine-tuning, without sacrificing factual reasoning. \textsc{reflect} is particularly effective at reducing the rate of rare but significant violations of principles, thereby improving safety and robustness in the tail end of the distribution of generations. Finally, we show that \textsc{reflect} naturally generates useful training data for traditional parameter fine-tuning techniques, allowing for efficient scaling and the reduction of inference-time computational overhead in long-term deployment scenarios.