Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
作者: Lintang Sutawika, Gokul Swamy, Zhiwei Steven Wu, Graham Neubig
分类: cs.CL, cs.LG
发布日期: 2026-01-26
备注: Code available at https://github.com/lintangsutawika/SP3F
💡 一句话要点
提出SP3F框架,利用特权信息提升大语言模型在目标语言上的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言推理 强化学习 特权信息 自博弈 低资源语言
📋 核心要点
- 现有大型语言模型在低资源语言上的推理能力远低于英语,是亟待解决的问题。
- SP3F框架利用翻译后的英语数据进行监督微调,并引入特权pairwise judge进行强化学习,提升模型推理能力。
- 实验表明,SP3F框架在多种任务上显著提升模型性能,甚至优于在更多数据上训练的模型。
📝 摘要(中文)
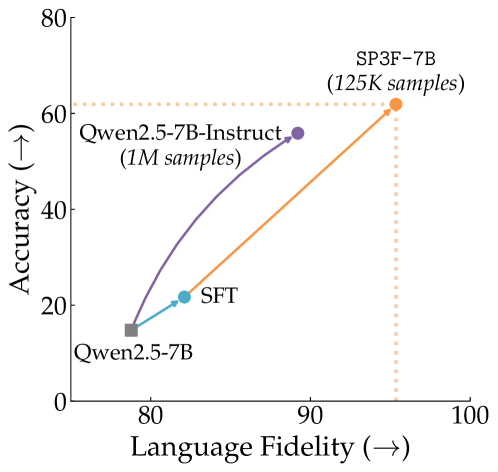
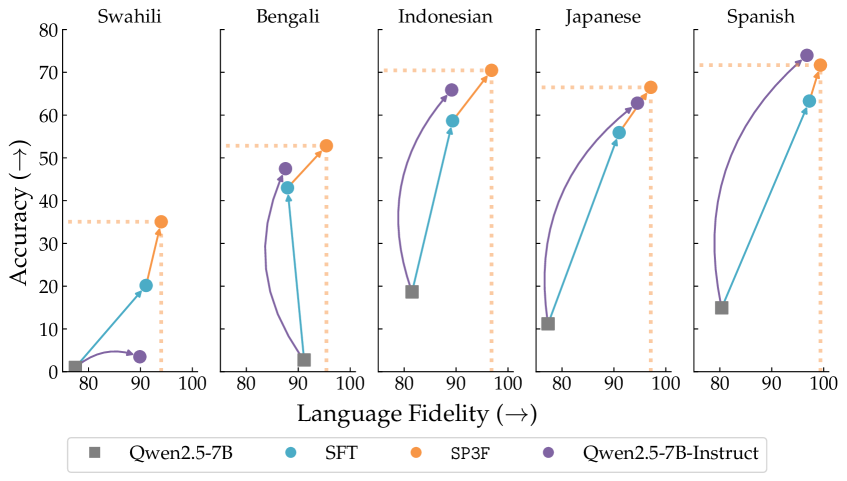
本文提出了一种名为SP3F(Self-Play with Privileged Pairwise Feedback)的两阶段框架,旨在提升大型语言模型(RLM)在训练数据较少的语言上的推理能力,而无需使用目标语言的任何数据。第一阶段,通过在翻译后的英语问答对上进行监督微调(SFT)来提高基础模型的正确性。第二阶段,以自博弈的方式进行强化学习,并使用一个pairwise judge提供反馈,该judge接收英文参考答案作为特权信息。即使模型的回答都不完全正确,特权pairwise judge仍然可以判断哪个回答更好。端到端地,SP3F显著提高了基础模型的性能,甚至在单语言、多语言和泛化到未见语言的设置中,在多个数学和非数学任务上优于完全后训练的模型,且使用的训练数据更少。
🔬 方法详解
问题定义:现有的大型语言模型(RLMs)在处理训练数据较少的语言时,性能会显著下降,即使是相同的问题用英语提问时模型表现良好。这种性能差距限制了RLMs在多语言环境中的应用。现有的方法通常需要目标语言的训练数据,这在低资源语言场景下是不可行的。
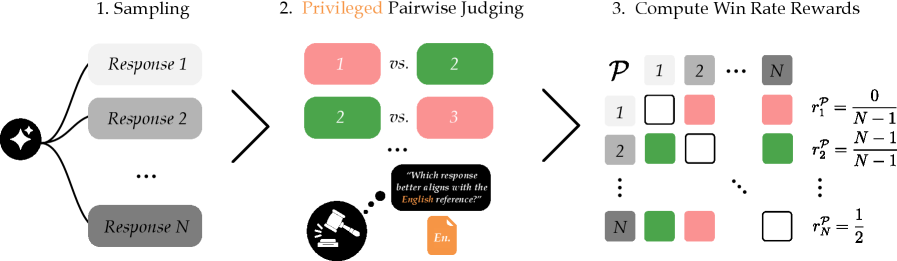
核心思路:SP3F的核心思路是利用英语作为桥梁,通过翻译后的英语数据进行训练,并引入一个能够访问英语参考答案的“特权”裁判(pairwise judge)。即使模型在目标语言上的回答不完全正确,裁判仍然可以根据与英语参考答案的比较,判断哪个回答更好。这种pairwise feedback机制能够有效地指导模型学习,提升其在目标语言上的推理能力。
技术框架:SP3F框架包含两个主要阶段:1) 监督微调(SFT):使用翻译后的英语问答对对基础模型进行微调,提高模型在目标语言上的初步理解和生成能力。2) 强化学习(RL):以自博弈的方式进行强化学习,模型生成两个不同的回答,然后由pairwise judge进行比较,并根据比较结果更新模型参数。pairwise judge接收英文参考答案作为特权信息。
关键创新:SP3F的关键创新在于引入了“特权pairwise judge”。传统的强化学习方法通常需要一个明确的奖励信号,但在低资源语言场景下,很难获得准确的奖励信号。SP3F通过pairwise judge,将奖励信号转化为相对的偏好信息,即使没有绝对正确的答案,也能指导模型学习。此外,该方法完全不需要目标语言的训练数据。
关键设计:在SFT阶段,使用了标准的交叉熵损失函数。在RL阶段,使用了PPO(Proximal Policy Optimization)算法,并根据pairwise judge的反馈计算奖励。pairwise judge的设计至关重要,它需要能够准确地判断哪个回答更接近英语参考答案。具体的实现方式未知,论文中可能使用了基于相似度度量的方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SP3F框架在多个数学和非数学任务上显著提升了模型性能,甚至优于在更多数据上训练的模型。例如,在某些任务上,SP3F框架的性能提升超过了10%。更重要的是,SP3F框架在泛化到未见语言的设置中也表现出色,证明了其具有良好的跨语言泛化能力。
🎯 应用场景
SP3F框架可应用于各种需要多语言推理能力的场景,例如多语言问答系统、机器翻译、跨语言信息检索等。该方法尤其适用于低资源语言,可以有效提升模型在这些语言上的性能,降低对目标语言数据的依赖,具有重要的实际应用价值和推广前景。
📄 摘要(原文)
When asked a question in a language less seen in its training data, current reasoning large language models (RLMs) often exhibit dramatically lower performance than when asked the same question in English. In response, we introduce \texttt{SP3F} (Self-Play with Privileged Pairwise Feedback), a two-stage framework for enhancing multilingual reasoning without \textit{any} data in the target language(s). First, we supervise fine-tune (SFT) on translated versions of English question-answer pairs to raise base model correctness. Second, we perform RL with feedback from a pairwise judge in a self-play fashion, with the judge receiving the English reference response as \textit{privileged information}. Thus, even when none of the model's responses are completely correct, the privileged pairwise judge can still tell which response is better. End-to-end, \texttt{SP3F} greatly improves base model performance, even outperforming fully post-trained models on multiple math and non-math tasks with less than of the training data across the single-language, multilingual, and generalization to unseen language settings.