From Verifiable Dot to Reward Chain: Harnessing Verifiable Reference-based Rewards for Reinforcement Learning of Open-ended Generation
作者: Yuxin Jiang, Yufei Wang, Qiyuan Zhang, Xingshan Zeng, Liangyou Li, Jierun Chen, Chaofan Tao, Haoli Bai, Lifeng Shang
分类: cs.CL
发布日期: 2026-01-26
备注: 19 pages, 8 figures, 12 tables. Accepted at ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于可验证参考奖励的强化学习(RLVRR),用于开放式生成的LLM对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 开放式生成 奖励函数 语言模型 可验证奖励
📋 核心要点
- 开放式生成任务缺乏明确的ground truth,传统基于单一可验证答案的强化学习方法效率低且易受奖励操纵。
- RLVRR从高质量参考中提取有序的语言信号(奖励链),将奖励分解为内容和风格两个维度进行评估。
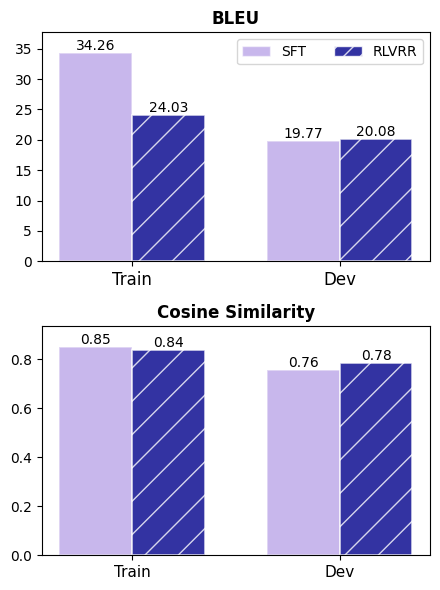
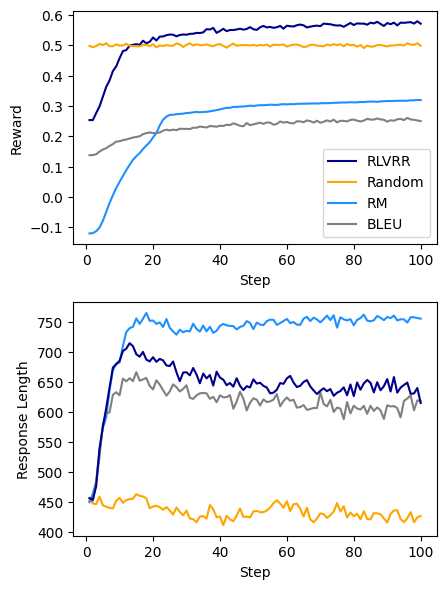
- 实验表明,RLVRR优于使用十倍数据训练的SFT,统一了结构化推理和开放式生成,并提升了泛化能力。
📝 摘要(中文)
本文提出了一种基于可验证参考奖励的强化学习方法(RLVRR),旨在解决开放式生成任务中强化学习的挑战。与依赖单一可验证答案的传统方法不同,RLVRR从高质量参考中提取有序的语言信号(即奖励链)。具体而言,RLVRR将奖励分解为内容和风格两个维度:内容维度保留确定性的核心概念(如关键词),风格维度通过基于LLM的验证评估对风格属性的遵守情况。这种方法结合了强化学习的探索能力与监督微调(SFT)的效率和可靠性。在Qwen和Llama模型上进行的广泛实验表明,RLVRR显著优于使用十倍数据训练的SFT和先进的奖励模型,统一了结构化推理和开放式生成的训练,并在保持输出多样性的同时更有效地泛化。这些结果表明,RLVRR是通向通用LLM对齐的可验证强化学习的一种有效途径。
🔬 方法详解
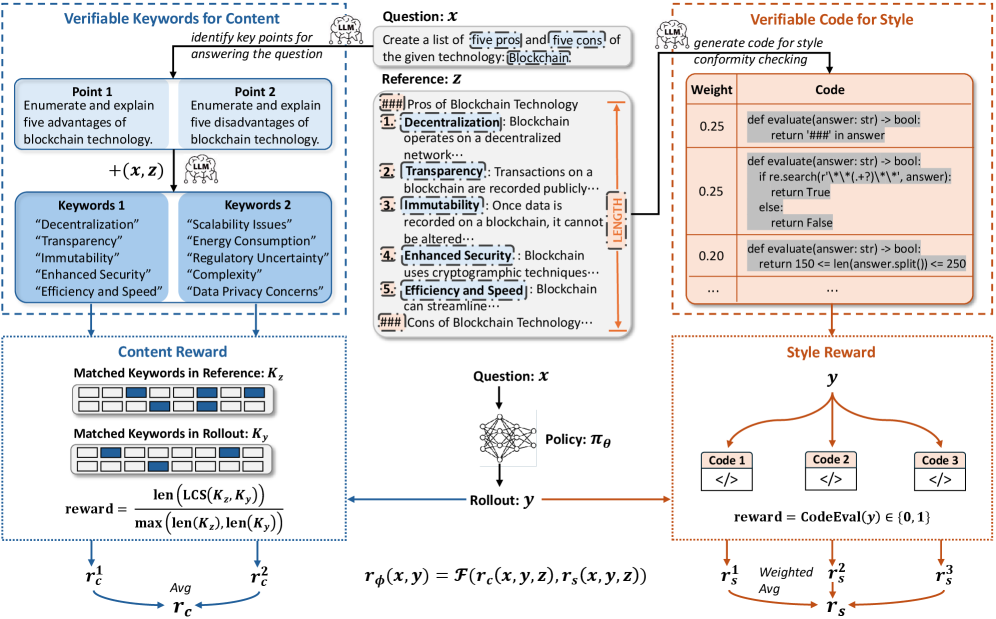
问题定义:现有基于可验证奖励的强化学习(RLVR)在推理任务中表现良好,但难以扩展到开放式生成任务,因为开放式生成缺乏明确的ground truth。依赖单一的“可验证点”监督会导致训练效率低下,并且容易出现奖励操纵问题。
核心思路:RLVRR的核心思路是从高质量的参考答案中提取有序的语言信号,构建“奖励链”,并基于此进行强化学习。通过将奖励分解为内容和风格两个维度,分别进行评估,从而更精细地指导模型的生成过程。这种方法结合了强化学习的探索能力和监督微调的效率。
技术框架:RLVRR的整体框架包括以下几个主要步骤:1) 从高质量参考答案中提取关键词等核心概念作为内容维度的监督信号;2) 使用LLM作为风格验证器,评估生成文本在风格上与参考答案的相似度;3) 将内容奖励和风格奖励结合起来,作为强化学习的奖励信号,训练生成模型。
关键创新:RLVRR的关键创新在于引入了“可验证参考奖励”的概念,将开放式生成任务的奖励信号从单一的“可验证点”扩展到有序的“奖励链”。通过内容和风格两个维度的奖励设计,更全面地评估生成文本的质量,从而提高了训练效率和生成质量。
关键设计:内容奖励通常基于关键词匹配度计算,风格奖励则通过预训练的LLM进行评估。具体而言,可以使用LLM计算生成文本和参考答案之间的语义相似度,或者训练一个专门的风格分类器来判断生成文本是否符合目标风格。奖励的权重需要根据具体任务进行调整,以平衡内容和风格的重要性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RLVRR在多个开放式生成基准测试中显著优于传统的监督微调方法和基于奖励模型的强化学习方法。例如,在某些任务上,RLVRR的性能超过了使用十倍数据训练的监督微调模型。此外,RLVRR还表现出更好的泛化能力和输出多样性。
🎯 应用场景
RLVRR可应用于各种开放式文本生成任务,例如故事生成、对话生成、代码生成等。该方法能够提高生成文本的质量、多样性和可控性,具有广泛的应用前景。此外,RLVRR还可以用于训练更通用的大语言模型,使其能够更好地理解和生成自然语言。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) succeeds in reasoning tasks (e.g., math and code) by checking the final verifiable answer (i.e., a verifiable dot signal). However, extending this paradigm to open-ended generation is challenging because there is no unambiguous ground truth. Relying on single-dot supervision often leads to inefficiency and reward hacking. To address these issues, we propose reinforcement learning with verifiable reference-based rewards (RLVRR). Instead of checking the final answer, RLVRR extracts an ordered linguistic signal from high-quality references (i.e, reward chain). Specifically, RLVRR decomposes rewards into two dimensions: content, which preserves deterministic core concepts (e.g., keywords), and style, which evaluates adherence to stylistic properties through LLM-based verification. In this way, RLVRR combines the exploratory strength of RL with the efficiency and reliability of supervised fine-tuning (SFT). Extensive experiments on more than 10 benchmarks with Qwen and Llama models confirm the advantages of our approach. RLVRR (1) substantially outperforms SFT trained with ten times more data and advanced reward models, (2) unifies the training of structured reasoning and open-ended generation, and (3) generalizes more effectively while preserving output diversity. These results establish RLVRR as a principled and efficient path toward verifiable reinforcement learning for general-purpose LLM alignment. We release our code and data at https://github.com/YJiangcm/RLVRR.