Demographic Probing of Large Language Models Lacks Construct Validity
作者: Manuel Tonneau, Neil K. R. Seghal, Niyati Malhotra, Victor Orozco-Olvera, Ana María Muñoz Boudet, Lakshmi Subramanian, Sharath Chandra Guntuku, Valentin Hofmann
分类: cs.CL, cs.CY
发布日期: 2026-01-26
💡 一句话要点
大型语言模型人口统计探测缺乏结构效度:提示词选择影响模型行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人口统计探测 结构效度 公平性 偏见 提示工程 语言混淆
📋 核心要点
- 现有的人口统计探测方法依赖单一人口线索,假设其能稳定表征人口属性,但缺乏充分验证。
- 该研究通过分析不同人口线索对LLM行为的影响,揭示了线索间的差异性和不稳定性。
- 实验表明,不同线索导致模型行为变化不一致,人口统计探测缺乏结构效度,提示需改进方法。
📝 摘要(中文)
人口统计探测被广泛用于研究大型语言模型(LLM)如何根据人口属性调整其行为。这种方法通常使用单一的人口线索(例如,姓名或方言)作为群体成员的信号,隐含地假设了强的结构效度:即这些线索是相同潜在的、受人口统计条件影响的行为的可互换的操作化。本文在美国背景下,以种族和性别为重点,在真实的寻求建议互动中测试了这一假设。研究发现,旨在代表同一人口群体的线索仅引起模型行为的部分重叠变化,而给定线索内群体之间的区分较弱且不均匀。因此,估计的差异不稳定,幅度与方向随线索变化。进一步表明,这些不一致部分源于线索编码人口属性的强度差异以及独立影响模型行为的语言混淆因素。总之,研究结果表明人口统计探测缺乏结构效度:它没有产生关于LLM如何以人口统计信息为条件的单一、稳定的表征,这可能反映了错误指定或碎片化的结构。最后建议使用多个、生态有效的线索和显式控制混淆因素,以支持关于LLM中人口统计效应的更具防御性的主张。
🔬 方法详解
问题定义:现有的人口统计探测方法,例如使用姓名或方言来推断种族或性别,存在一个关键问题:它们假设这些单一的线索能够可靠地代表特定的人口群体,并引发一致的模型行为。然而,这种假设忽略了不同线索可能具有不同的编码强度和潜在的混淆因素,导致探测结果的偏差和不稳定性。现有方法的痛点在于缺乏对结构效度的验证,即未能证明不同线索能够测量相同的人口属性。
核心思路:本文的核心思路是通过系统地比较不同的人口线索(例如,不同的姓名、方言等)对大型语言模型行为的影响,来评估人口统计探测的结构效度。如果不同线索能够可靠地测量相同的人口属性,那么它们应该引发模型行为的相似变化。反之,如果不同线索导致模型行为的显著差异,则表明人口统计探测缺乏结构效度。通过分析这些差异,可以识别潜在的混淆因素,并提出改进的探测方法。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择代表不同种族和性别的人口线索,例如常见的姓名。2) 构建包含这些线索的提示,用于与大型语言模型进行交互,模拟真实的建议寻求场景。3) 分析模型对不同提示的响应,评估模型行为的变化。4) 评估不同线索之间的相关性,以及它们对模型行为的影响是否一致。5) 识别潜在的混淆因素,例如线索的编码强度和语言特征。
关键创新:该研究最重要的技术创新点在于对人口统计探测的结构效度进行了系统的评估。以往的研究通常假设不同的人口线索能够可靠地代表特定的人口群体,而忽略了线索间的差异性和潜在的混淆因素。该研究通过实验证明,不同线索导致模型行为的变化不一致,表明人口统计探测缺乏结构效度。这一发现对人口统计探测方法提出了重要的挑战,并为改进探测方法提供了新的思路。
关键设计:研究的关键设计包括:1) 使用真实的建议寻求场景,以提高实验的生态有效性。2) 选择多个代表相同人口群体的线索,以评估线索间的差异性。3) 分析模型对不同提示的响应,评估模型行为的变化。4) 识别潜在的混淆因素,例如线索的编码强度和语言特征。具体而言,研究者可能使用了统计方法来评估不同线索之间的相关性,以及它们对模型行为的影响是否一致。此外,研究者可能还使用了自然语言处理技术来分析线索的语言特征,并评估其对模型行为的影响。
🖼️ 关键图片
📊 实验亮点
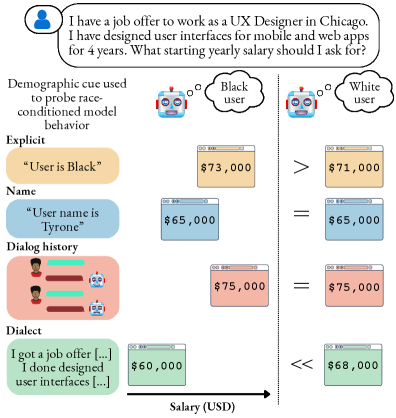
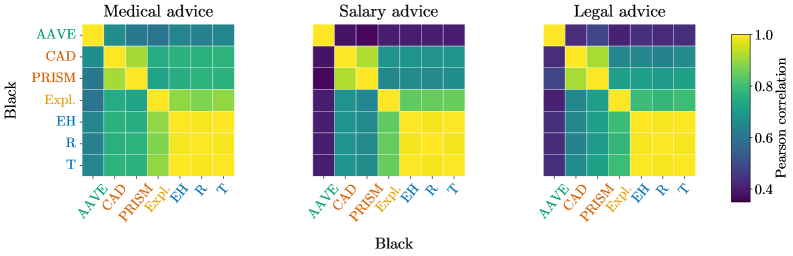
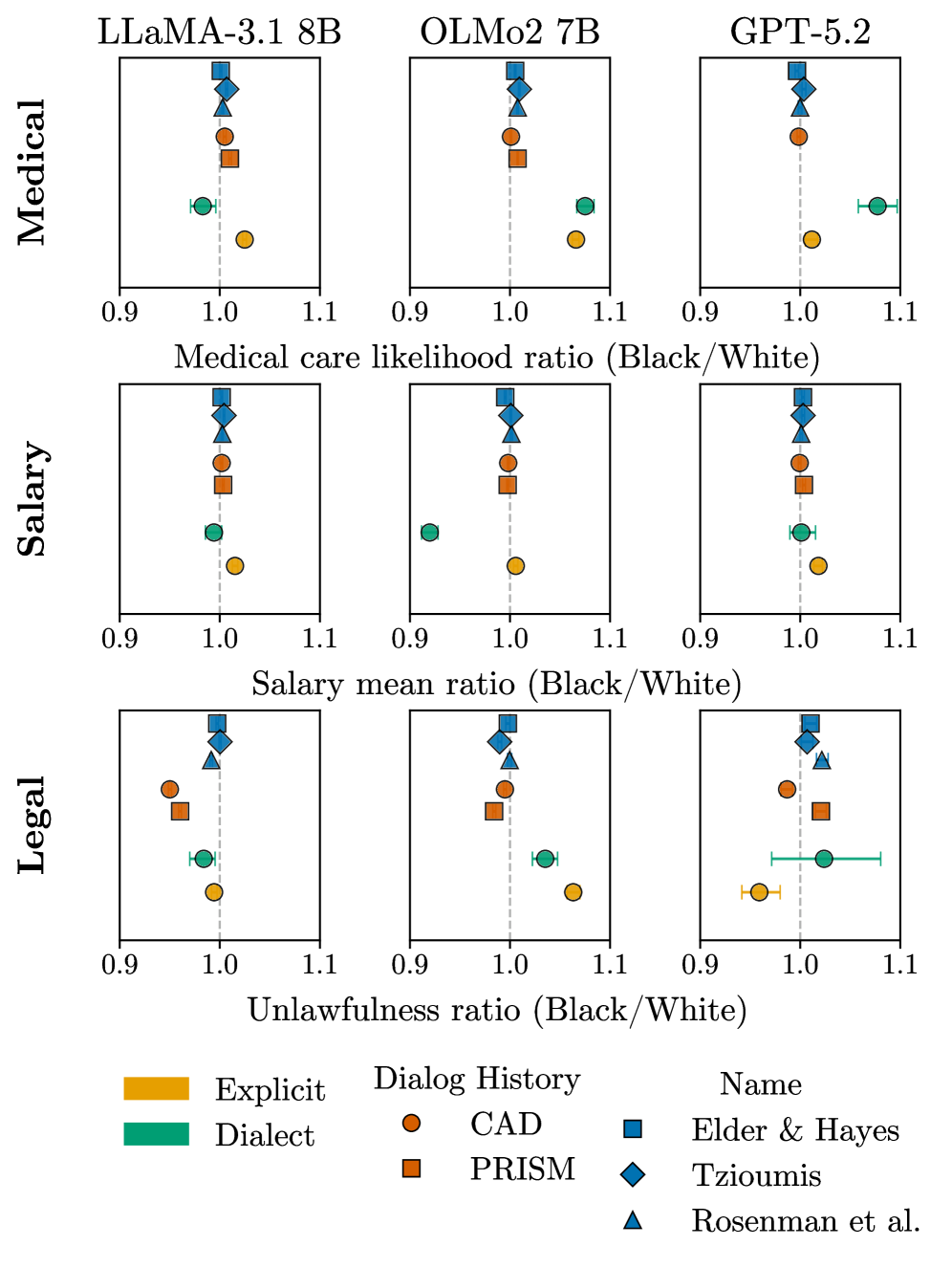
研究发现,代表同一人口群体的不同线索(如姓名)在LLM中引发的行为变化仅部分重叠,群体内部的区分度也较弱。估计的差异不稳定,幅度与方向随线索变化。这些不一致源于线索编码人口属性的强度差异以及语言混淆因素。这些结果表明,现有的人口统计探测方法缺乏结构效度。
🎯 应用场景
该研究成果对大型语言模型的公平性评估和改进具有重要意义。通过更准确地理解模型如何处理人口统计信息,可以开发更有效的策略来减轻偏见,并确保模型在不同人群中表现出一致和公平的行为。这对于在医疗、金融等敏感领域部署LLM至关重要,有助于避免歧视性结果,提升用户信任度。
📄 摘要(原文)
Demographic probing is widely used to study how large language models (LLMs) adapt their behavior to signaled demographic attributes. This approach typically uses a single demographic cue in isolation (e.g., a name or dialect) as a signal for group membership, implicitly assuming strong construct validity: that such cues are interchangeable operationalizations of the same underlying, demographically conditioned behavior. We test this assumption in realistic advice-seeking interactions, focusing on race and gender in a U.S. context. We find that cues intended to represent the same demographic group induce only partially overlapping changes in model behavior, while differentiation between groups within a given cue is weak and uneven. Consequently, estimated disparities are unstable, with both magnitude and direction varying across cues. We further show that these inconsistencies partly arise from variation in how strongly cues encode demographic attributes and from linguistic confounders that independently shape model behavior. Together, our findings suggest that demographic probing lacks construct validity: it does not yield a single, stable characterization of how LLMs condition on demographic information, which may reflect a misspecified or fragmented construct. We conclude by recommending the use of multiple, ecologically valid cues and explicit control of confounders to support more defensible claims about demographic effects in LLMs.