Latent Knowledge as a Predictor of Fact Acquisition in Fine-Tuned Large Language Models
作者: Daniel B. Hier, Tayo Obafemi-Ajayi
分类: cs.CL
发布日期: 2026-01-26
💡 一句话要点
利用潜在知识预测微调大语言模型中的事实获取速度与泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 潜在知识 事实获取 泛化能力 生物医学 知识表示
📋 核心要点
- 大型语言模型存储事实的能力不均衡,部分事实以“潜在知识”形式存在,难以通过确定性解码访问,影响模型性能。
- 该研究通过微调Llama 3.1 8B,并结合随机解码和Cox比例风险模型,分析了潜在知识对事实获取、泛化和退化的影响。
- 实验表明,潜在知识是事实获取速度的关键预测因子,并影响泛化能力,而训练期间的强化有助于抵抗知识退化。
📝 摘要(中文)
本文研究了大型语言模型在预训练后存储生物医学事实的不均衡性:一些事实存在于模型权重中但无法通过确定性解码可靠访问(潜在知识),而另一些事实则很少被表示。研究人员对Llama 3.1 8B Instruct进行微调,使其学习来自人类表型本体(800对)和基因本体(400对训练对)的本体术语标识符映射,并保留400个GO对以测试泛化能力。将学习视为一个跨越20个epoch的时间事件过程,使用随机解码来检测基线时的潜在知识,并使用Cox比例风险模型来识别获取、泛化和退化的预测因子。HPO的基线确定性召回率为2.8%,微调后升至71.9%。潜在知识是更快的事实获取的最强预测因子(HR 2.6),并且与更早、更高的峰值学习率和更快的收敛相关;标识符频率和人工注释计数的影响较小。推广到保留的GO事实并不常见(5.8%),但在存在潜在知识时更有可能。先前正确的GO映射对于保留(未见)术语比对于训练(已见)术语更频繁地退化,表明训练期间的强化具有保护作用。这些结果表明,潜在知识可以预测微调期间事实学习的速度和未见本体事实的有限泛化,而抵抗退化取决于事实是否得到强化。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在微调过程中,事实学习速度和泛化能力差异的问题。现有方法缺乏对模型中“潜在知识”的有效利用和评估,无法准确预测模型对新事实的学习能力,以及已学知识的稳定性。
核心思路:论文的核心思路是将模型中已存在的但难以直接访问的“潜在知识”作为预测因子,研究其对模型学习新事实的速度、泛化能力以及知识稳定性的影响。通过分析潜在知识与学习过程之间的关系,揭示影响模型事实学习的关键因素。
技术框架:整体框架包括以下几个阶段:1) 数据准备:构建人类表型本体(HPO)和基因本体(GO)的术语标识符映射数据集,并划分训练集和测试集。2) 模型微调:使用Llama 3.1 8B Instruct模型在训练集上进行微调。3) 潜在知识检测:在微调前后,使用随机解码方法检测模型中存在的潜在知识。4) 风险模型分析:使用Cox比例风险模型分析潜在知识、标识符频率等因素对事实获取、泛化和退化的影响。
关键创新:论文的关键创新在于:1) 将“潜在知识”这一概念引入到对语言模型事实学习过程的分析中,并证明其对学习速度和泛化能力具有显著影响。2) 使用随机解码方法来检测模型中的潜在知识,为量化潜在知识提供了有效手段。3) 利用Cox比例风险模型,系统地分析了多个因素对事实获取、泛化和退化的影响,揭示了影响模型知识学习和稳定性的关键因素。
关键设计:1) 使用Llama 3.1 8B Instruct模型作为基础模型。2) 采用随机解码方法,通过多次采样来估计模型中潜在知识的存在程度。3) 使用Cox比例风险模型,将学习过程建模为时间事件过程,分析不同因素对学习速度的影响。4) 将数据集划分为训练集(用于微调)和测试集(用于评估泛化能力),并对训练集中的事实进行强化,以研究强化对知识稳定性的影响。
🖼️ 关键图片


📊 实验亮点
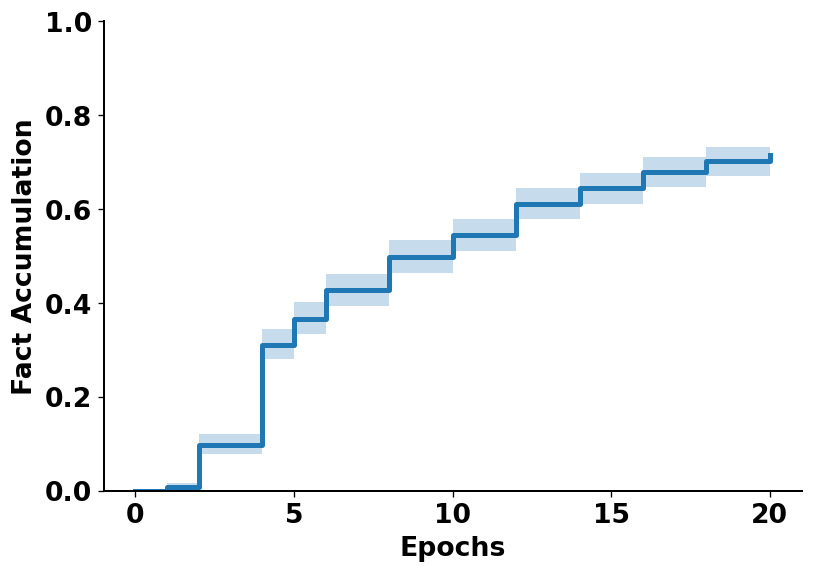
实验结果表明,潜在知识是事实获取速度的最强预测因子(HR 2.6),并且与更早、更高的峰值学习率和更快的收敛相关。微调后,HPO的确定性召回率从2.8%提升至71.9%。推广到保留的GO事实的概率为5.8%,且在存在潜在知识时更高。先前正确的GO映射对于未见术语比已见术语更频繁地退化。
🎯 应用场景
该研究成果可应用于提升大型语言模型在生物医学领域的知识学习效率和准确性。通过识别和利用模型中的潜在知识,可以更有效地进行微调,提高模型对新事实的学习速度和泛化能力。此外,该研究也为评估和改进语言模型的知识表示和推理能力提供了新的思路。
📄 摘要(原文)
Large language models store biomedical facts with uneven strength after pretraining: some facts are present in the weights but are not reliably accessible under deterministic decoding (latent knowledge), while others are scarcely represented. We fine tuned Llama 3.1 8B Instruct to learn ontology term identifier mappings from the Human Phenotype Ontology (800 pairs) and the Gene Ontology (400 training pairs), withholding 400 GO pairs to test generalization. Treating learning as a time to event process across 20 epochs, we used stochastic decoding to detect latent knowledge at baseline and Cox proportional hazards models to identify predictors of acquisition, generalization, and degradation. Baseline deterministic recall for HPO was 2.8%, rising to 71.9% after fine-tuning. Latent knowledge was the strongest predictor of faster fact acquisition (HR 2.6) and was associated with earlier, higher peak learning rates and faster convergence; identifier frequency and curated annotation counts had smaller effects. Generalization to withheld GO facts was uncommon (5.8%) but more likely when latent knowledge was present. Previously correct GO mappings degraded more often for withheld (unseen) terms than for trained (seen) terms, suggesting a protective effect of reinforcement during training. These results show that latent knowledge predicts both the speed of factual learning during fine-tuning and the limited generalization of unseen ontology facts, while resistance to degradation depends on whether facts are reinforced.