OCR-Enhanced Multimodal ASR Can Read While Listening
作者: Junli Chen, Changli Tang, Yixuan Li, Guangzhi Sun, Chao Zhang
分类: cs.SD, cs.CL, eess.AS
发布日期: 2026-01-26
备注: 4 pages, 2 figures. Submitted to ICASSP 2026
💡 一句话要点
提出Donut-Whisper模型,利用视觉信息提升多语种语音识别性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态语音识别 视觉信息融合 交叉注意力机制 知识蒸馏 音视频数据集
📋 核心要点
- 现有语音识别模型在复杂场景下性能受限,忽略了视频字幕等视觉信息的辅助作用。
- Donut-Whisper模型融合音视频特征,通过交叉注意力机制实现模态对齐,提升特征表达能力。
- 实验表明,Donut-Whisper在多语种数据集上显著优于现有模型,尤其在中文识别上提升明显。
📝 摘要(中文)
本文提出Donut-Whisper,一种利用双编码器增强视觉信息的多模态语音识别模型,旨在提升英语和中文的语音识别性能。Donut-Whisper通过交叉注意力模块结合了线性结构和基于Q-Former的模态对齐结构的优势,从而生成更强大的音视频特征。同时,本文提出了一种轻量级的知识蒸馏方案,展示了使用音视频模型来指导纯音频模型以获得更好性能的潜力。此外,本文还提出了一个新的多语种音视频语音识别数据集,该数据集基于包含中文和英文片段的电影剪辑。实验结果表明,与Donut和Whisper large V3基线模型相比,Donut-Whisper在数据集的英文和中文部分均取得了显著更好的性能。特别是,与Whisper ASR基线相比,在英文和中文数据集上分别实现了5.75%的绝对WER降低和16.5%的绝对CER降低。
🔬 方法详解
问题定义:现有的自动语音识别(ASR)模型,尤其是在处理包含视觉信息的场景(如电影、视频会议等)时,往往忽略了视觉信息(例如字幕)的辅助作用。这些视觉信息可以提供额外的上下文线索,帮助模型更准确地识别语音。因此,如何有效地利用视觉信息来提升ASR模型的性能是一个重要的研究问题。
核心思路:Donut-Whisper的核心思路是构建一个能够同时处理音频和视觉信息的多模态ASR模型。该模型通过双编码器分别提取音频和视觉特征,并利用交叉注意力机制实现模态间的有效融合。此外,还提出了知识蒸馏方案,将多模态模型的知识迁移到纯音频模型,进一步提升性能。
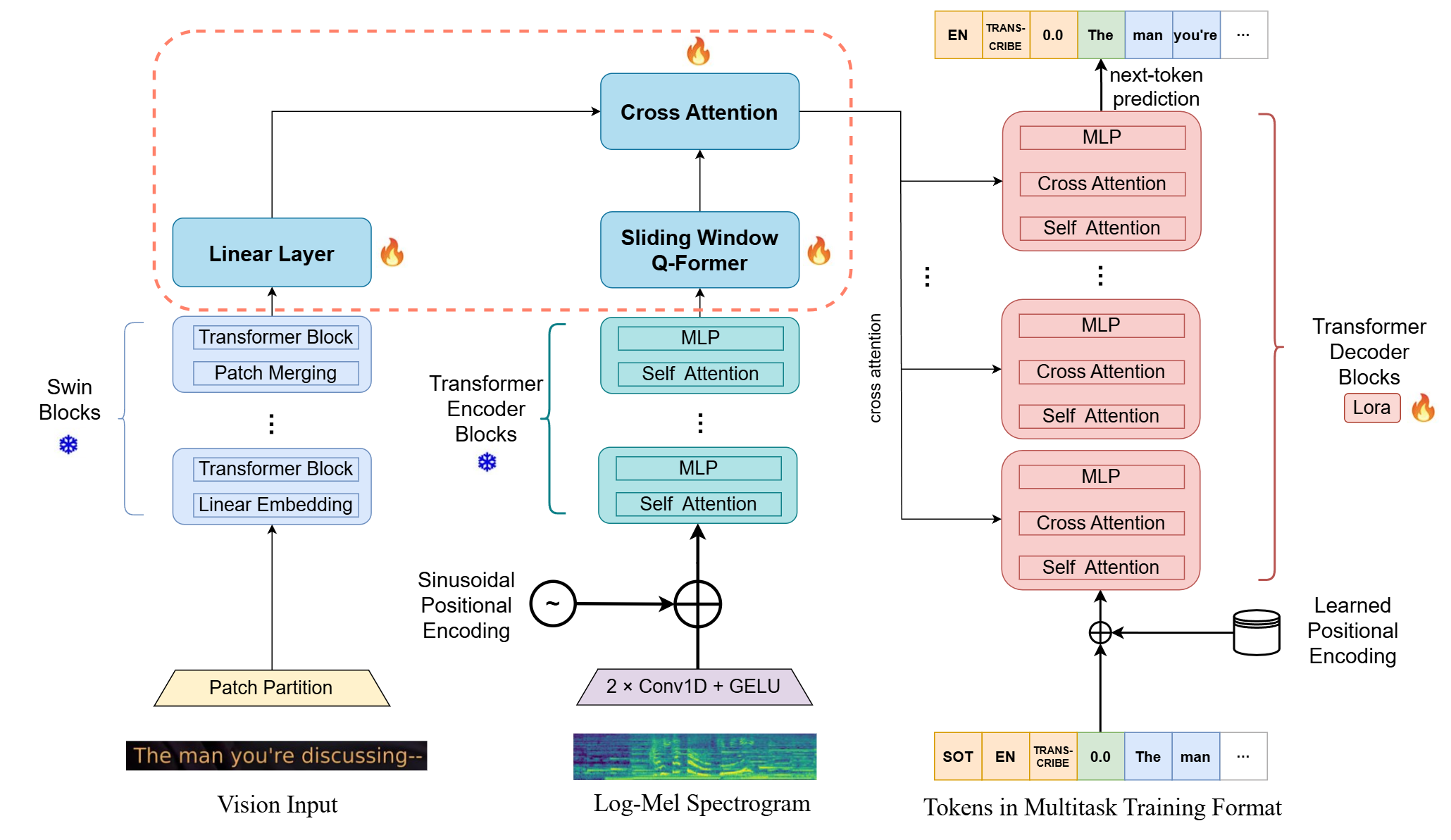
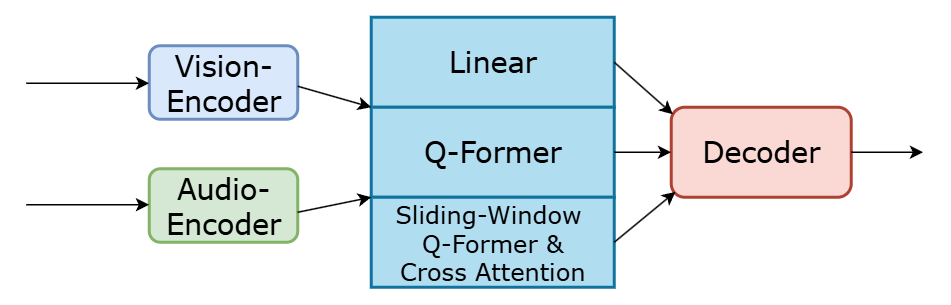
技术框架:Donut-Whisper模型包含以下主要模块:1) 音频编码器:用于提取音频特征。2) 视觉编码器:用于提取视觉特征(例如,从视频帧中提取的文本信息)。3) 交叉注意力模块:用于融合音频和视觉特征,实现模态间的交互。4) 解码器:用于将融合后的特征解码为文本。整个流程是,首先分别使用音频和视觉编码器提取特征,然后通过交叉注意力模块进行融合,最后使用解码器生成识别结果。
关键创新:Donut-Whisper的关键创新在于:1) 提出了双编码器结构,能够同时处理音频和视觉信息。2) 利用交叉注意力模块实现了线性结构和基于Q-Former的模态对齐结构的优势结合,从而更有效地融合音视频特征。3) 提出了轻量级的知识蒸馏方案,能够将多模态模型的知识迁移到纯音频模型。
关键设计:在网络结构方面,Donut-Whisper采用了Transformer架构,并针对音视频模态的特点进行了优化。在损失函数方面,采用了交叉熵损失函数来训练模型。在训练过程中,使用了Adam优化器,并设置了合适的学习率和batch size。此外,为了防止过拟合,还使用了dropout等正则化技术。
🖼️ 关键图片
📊 实验亮点
Donut-Whisper模型在自建的多语种音视频数据集上取得了显著的性能提升。与Whisper ASR基线相比,在英文数据集上实现了5.75%的绝对WER降低,在中文数据集上实现了16.5%的绝对CER降低。这些结果表明,Donut-Whisper模型能够有效地利用视觉信息来提升语音识别性能,尤其是在中文语音识别方面表现突出。
🎯 应用场景
该研究成果可应用于多媒体内容理解、视频会议字幕生成、在线教育等领域。通过结合视觉信息,可以显著提升语音识别的准确率,尤其是在噪声环境或口音复杂的情况下。未来,该技术有望应用于更广泛的音视频场景,例如智能家居、车载语音助手等,提升人机交互的自然性和准确性。
📄 摘要(原文)
Visual information, such as subtitles in a movie, often helps automatic speech recognition. In this paper, we propose Donut-Whisper, an audio-visual ASR model with dual encoder to leverage visual information to improve speech recognition performance in both English and Chinese. Donut-Whisper combines the advantage of the linear and the Q-Former-based modality alignment structures via a cross-attention module, generating more powerful audio-visual features. Meanwhile, we propose a lightweight knowledge distillation scheme showcasing the potential of using audio-visual models to teach audio-only models to achieve better performance. Moreover, we propose a new multilingual audio-visual speech recognition dataset based on movie clips containing both Chinese and English partitions. As a result, Donut-Whisper achieved significantly better performance on both English and Chinese partition of the dataset compared to both Donut and Whisper large V3 baselines. In particular, an absolute 5.75% WER reduction and a 16.5% absolute CER reduction were achieved on the English and Chinese sets respectively compared to the Whisper ASR baseline.