When Domain Pretraining Interferes with Instruction Alignment: An Empirical Study of Adapter Merging in Medical LLMs
作者: Junyi Zou
分类: cs.CL, cs.AI
发布日期: 2026-01-26
💡 一句话要点
针对医学LLM,提出加权Adapter融合方法,解决领域预训练与指令对齐的干扰问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学LLM 领域预训练 指令对齐 Adapter融合 LoRA微调
📋 核心要点
- 医学LLM在领域知识和指令对齐间存在冲突,领域预训练可能干扰指令微调,导致模型无法同时兼顾专业性和安全性。
- 提出加权Adapter融合方法,通过线性组合领域预训练和指令微调的Adapter,平衡模型在知识保留和指令遵循方面的能力。
- 实验表明,该方法在医学问答任务上取得了显著的性能提升,BLEU-4达到16.38,ROUGE-1达到20.42,验证了方法的有效性。
📝 摘要(中文)
大型语言模型(LLMs)展现出强大的通用能力,但通常在医学术语的精确性和安全相关的指令遵循方面表现不佳。本文以一个140亿参数的基础模型为例,研究了安全关键领域中Adapter的干扰问题,采用两阶段LoRA流程:(1)领域自适应预训练(PT),通过持续预训练(DAPT)注入广泛的医学知识;(2)监督微调(SFT),通过指令风格的数据使模型与医学问答行为对齐。为了平衡指令遵循能力和领域知识保留,我们提出了加权Adapter融合方法,在线性组合SFT和PT Adapter后,导出一个融合的基础模型检查点。在一个保留的医学验证集(F5/F6)上,该融合模型在实际解码配置下实现了BLEU-4 = 16.38,ROUGE-1 = 20.42,ROUGE-2 = 4.60和ROUGE-L = 11.54。我们进一步分析了解码敏感性和训练稳定性,通过损失曲线和受控解码比较。
🔬 方法详解
问题定义:论文旨在解决医学领域大型语言模型(LLM)在进行领域自适应预训练(DAPT)和指令微调(SFT)时出现的知识冲突问题。具体来说,DAPT旨在注入医学知识,而SFT旨在使模型遵循医学问答指令。然而,直接进行SFT可能会覆盖或干扰DAPT获得的领域知识,导致模型在医学专业性方面表现不佳。现有方法难以在指令遵循和领域知识保留之间取得平衡。
核心思路:论文的核心思路是通过加权Adapter融合来平衡DAPT和SFT的影响。Adapter是一种轻量级的参数化模块,可以插入到LLM中进行微调,而无需修改原始模型参数。通过分别训练DAPT和SFT的Adapter,然后将它们线性组合,可以控制模型对领域知识和指令的关注程度。这种方法允许模型在遵循指令的同时,保留尽可能多的医学知识。
技术框架:整体流程包括三个主要阶段:(1)使用LoRA技术进行领域自适应预训练(DAPT),训练一个Adapter以注入医学知识。(2)使用LoRA技术进行监督微调(SFT),训练另一个Adapter以对齐医学问答指令。(3)使用提出的加权Adapter融合方法,将DAPT和SFT的Adapter线性组合,得到一个融合的Adapter。最终,将融合后的Adapter合并回基础模型,得到一个同时具备领域知识和指令遵循能力的模型。
关键创新:最重要的技术创新点是加权Adapter融合方法。与直接进行SFT或简单地将DAPT和SFT模型进行集成不同,该方法通过线性组合Adapter来细粒度地控制模型对不同知识来源的关注程度。这种方法可以有效地平衡指令遵循和领域知识保留,从而提高模型在医学问答任务上的性能。
关键设计:关键的设计包括:(1) 使用LoRA进行Adapter训练,降低训练成本。(2) 使用线性加权融合Adapter,权重系数的选择至关重要,需要根据具体任务进行调整。(3) 在医学验证集上评估融合模型的性能,并分析解码敏感性和训练稳定性。
🖼️ 关键图片
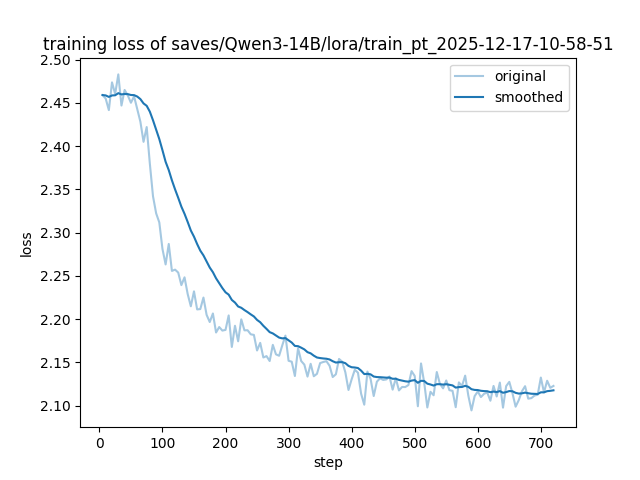
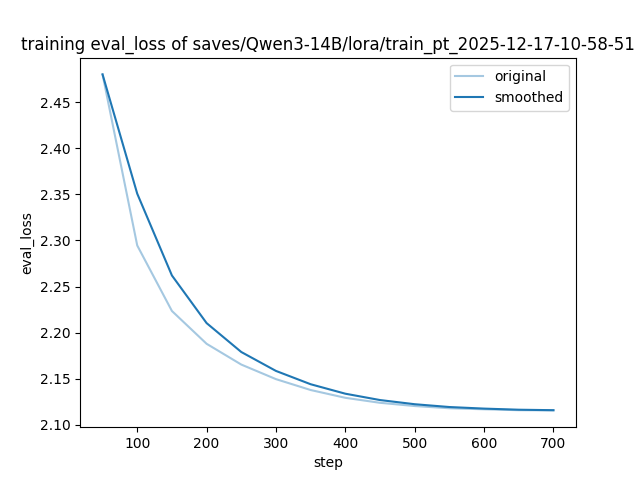
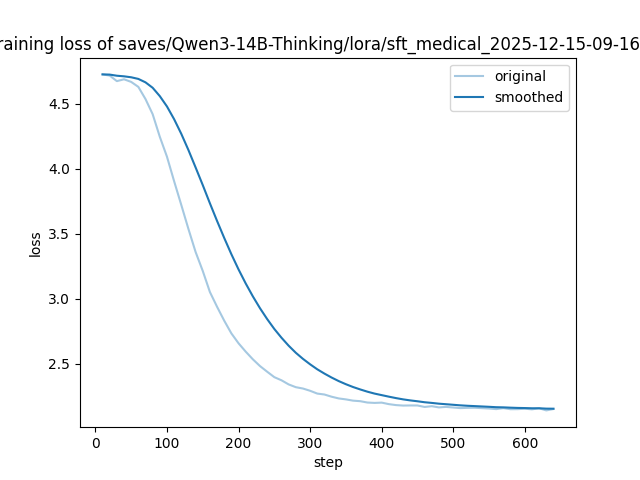
📊 实验亮点
实验结果表明,提出的加权Adapter融合方法在医学验证集上取得了显著的性能提升。具体来说,融合模型在BLEU-4指标上达到了16.38,ROUGE-1指标上达到了20.42,ROUGE-2指标上达到了4.60,ROUGE-L指标上达到了11.54。这些结果表明,该方法能够有效地平衡指令遵循和领域知识保留,从而提高模型在医学问答任务上的性能。
🎯 应用场景
该研究成果可应用于医疗问答系统、智能诊断助手、医学知识库构建等领域。通过提升医学LLM的专业性和安全性,可以为医生和患者提供更准确、可靠的医疗信息和决策支持,从而改善医疗服务质量和效率。未来,该方法可以推广到其他安全关键领域,例如金融、法律等。
📄 摘要(原文)
Large language models (LLMs) show strong general capability but often struggle with medical terminology precision and safety-critical instruction following. We present a case study for adapter interference in safety-critical domains using a 14B-parameter base model through a two-stage LoRA pipeline: (1) domain-adaptive pre-training (PT) to inject broad medical knowledge via continued pre-training (DAPT), and (2) supervised fine-tuning (SFT) to align the model with medical question-answering behaviors through instruction-style data. To balance instruction-following ability and domain knowledge retention, we propose Weighted Adapter Merging, linearly combining SFT and PT adapters before exporting a merged base-model checkpoint. On a held-out medical validation set (F5/F6), the merged model achieves BLEU-4 = 16.38, ROUGE-1 = 20.42, ROUGE-2 = 4.60, and ROUGE-L = 11.54 under a practical decoding configuration. We further analyze decoding sensitivity and training stability with loss curves and controlled decoding comparisons.